元组
元组(tuple)是一种一维的、定长的、不可变的Python 对象序列。最简单的创建方式是一组以逗号隔开的值:
1 | tup = 4, 5, 6 |
任何序列或迭代器都可以被转换为元组:
1 | tup = tuple('string') |
元组的元素也可以通过方括号([])进行访问。
元组可以通过加号(+)运算符连接起来以产生更长的元组。
一个元组乘以一个整数,相当于是连接该元组的多个副本:
1 | ('foo', 'bar') * 4 |
元组拆包
对元组型变量表达式进行赋值:
1 | tup = (4, 5, 6) |
非常轻松地交换变量名:
1 | b, a = a, b |
对由元组或列表组成的序列进行迭代:
1 | seq = [(1, 2, 3), (4, 5, 6), (7, 8, 9)] |
处理从函数中返回的多个值。
元组方法
由于元组的大小和内存不能被修改,所以其实例方法很少。count 用于计算指定值的出现次数:
1 | a = (1, 2, 2, 2, 3, 4, 2) |
列表
列表(list)是变长的,其内容也是可以修改的,可以通过方括号([])或 list 函数进行定义:
1 | tup = ('foo', 'bar', 'baz') |
添加和移除元素
通过 append 方法,可以将元素添加到列表的末尾:
1 | b_list.append('dwarf') |
利用 insert 可以将元素插入到列表的指定位置:
1 | b_list.insert(1, 'red') |
insert 的逆运算是 pop,用于移除并返回指定索引处的元素:
1 | b_list.pop(2) |
remove 用于按值删除元素(删除第一个符合要求的值):
1 | b_list.remove('foo') |
通过 in 关键字,可以判断列表中是否含有某个值:
1 | 'dwarf' in b_list |
判断列表是否含有某个值的操作比字典和集合慢得多,因为 Python 会对列表中的值进行线性扫描,而另外两个基于哈希表,可以瞬间完成判断。
合并列表
列表的合并是一种相当费资源的操作,必须创建一个新列表并将所有对象复制过去;用 extend 将元素附加到现有列表,就会好很多:
1 | x = [4, None, 'foo'] |
排序
调用列表的 sort 方法可以实现就地排序(无需创建新对象):
1 | a = [7, 2, 5, 1, 3] |
sort 有几个很不错的选项。次要排序键:一个能够产生可用于排序的值的函数。
可以通过长度对一组字符串进行排序:
1 | b = ['saw', 'small', 'He', 'foxes', 'six'] |
二分搜索及维护有序列表
内置的 bisect 模块实现了二分查找以及对有序列表的插入操作:
- bisect.bisect 可以找出新元素应该被插入的位置。
- bisect.insort 确实地将新元素插入到那个位置上去。
bisect 模块的函数不会判断原列表是否是有序的。将它们用于无序列表虽然不会报错,但可能导致不正确的结果。
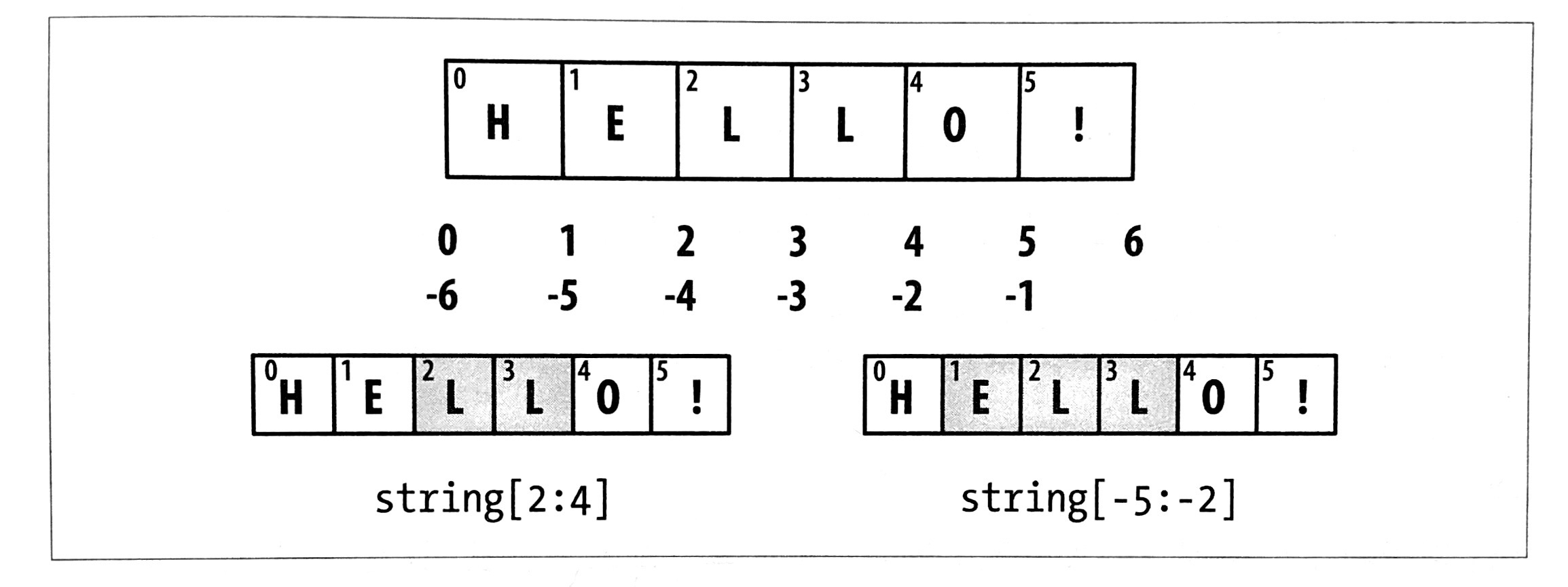
切片
通过切片标记法,可以选取序列类型的子集,其基本形式由索引运算符([])以及传入其中的 start:stop 构成:
1 | seq = [7, 2, 3, 6, 3, 5, 6, 0, 1] |
stop 索引处的元素是未被包括在内的,元素的数量是 stop - start。
start 或 stop 都是可以省略的,此时它们分别默认为序列的起始处和结尾处,负数索引从序列的末尾开始切片:
1 | seq[-4:] |
还可以在第二个冒号后面加上步长(step),实现每隔一位取出一个元素:
1 | seq[::2] |
使用 -1 是一个很巧妙的方法,可以实现列表或元组的反序:
1 | seq[::-1] |
内置的序列函数
Python 有一些很不错的序列函数,你应该熟悉它们,只要有机会就用。
enumerate
在对一个序列进行迭代时,常常需要跟踪当前项的索引。
Python 内置了一个 enumerate 函数,可以逐个返回序列的 (i, value) 元组:
1 | for i, value in enumerate(collection): |
sorted
sorted 函数可以将任何序列返回为一个新的有序列表:
1 | sorted('horse race') |
zip
zip 用于将多个序列中的元素配对,从而产生一个新的元组列表。zip 可以接受任意数量的序列,得到的元组数量由最短的序列决定:
1 | seq1 = ['foo', 'bar', 'baz'] |
reversed
reversed 用于按逆序迭代序列中的元素:
1 | list(reversed(range(10))) |
字典
字典(dict)更常见的名字是哈希映射(hash map),是一种大小可变的键值对集。创建字典的方式之一是:使用大括号({})并用冒号分隔键和值:
1 | empty_dict = {} |
keys 和 values 方法分别用于获取键和值的列表。虽然键值对没有特定的顺序,但这两个函数会以相同的顺序输出键和值:
1 | d1.keys() |
利用 update 方法,一个字典可以被合并到另一个字典中去:
1 | d1.update({'b':'foo', 'c':12}) |
从序列类型创建字典
我们完全可以用 dict 类型函数,直接将两个序列中的元素两两配对地组成一个字典:
1 | mapping = dict(zip(range(5), reversed(range(5)))) |
默认值
dict 的 get 和 pop 方法可以接受一个可供返回的默认值(如果 key 不存在,get 默认返回 None,pop 会引发异常)。
1 | if key in some_dict: |
上面的 if-else 块可以被简单地写成:
1 | value = some_dict.get(key, default_value) |
常常会将字典中的值处理成别的集类型(比如列表),根据首字母对一组单词进行分类:
1 | word = ['apple', 'bat', 'bar', 'atom', 'book'] |
使用 setdefault 方法,上面的 if-else 块可以写成:
1 | by_letter.setdefault(letter, []).append(word) |
内置的 collections 模块有一个叫做 defaultdict 的类,传入一个类型或函数,用于生成字典各插槽所使用的默认值:
1 | from colletions import defaultdict |
defaultdict 的初始化器只需要一个可调用对象,将默认值设置为 4:
1 | counts = defaultdict(lambda: 4) |
字典键的有效类型
字典的值可以是任何 Python 对象,但键必须是不可变对象。术语是可哈希性,可通过 hash 函数判断:
1 | # TypeError |
如果要将列表当作键,最简单的方法就是将其转换成元组。
集合
集合(set)是由唯一元素组成的无序集,可以看成是只有键的字典。创建方式为 set 函数或大括号包起来的集合字面量:
1 | set([2, 2, 2, 1, 3, 3]) |
支持各种数学集合运算:
1 | a = {1, 2, 3, 4, 5} |
还可以判断一个集合是否是另一个集合的子集或超集:
1 | a_set = {1, 2, 3, 4, 5} |