Keep in mind that everything is a trade-off.
Next, we’ll look at high-level trade-offs:
- Performance vs. Scalability;
- Latency vs. Throughput;
- Consistency vs. Availability;
性能与可扩展性
如果服务性能的增长与资源的增加是成比例的,服务就是可扩展的。通常,提高性能意味着服务于更多的工作单元,另一方面,当数据集增长时,同样也可以处理更大的工作单位。
另一个角度来看待性能与可扩展性:
- 如果你的系统有性能问题,对于单个用户来说是缓慢的;
- 如果你的系统有可扩展性问题,单个用户较快但在高负载下会变慢;
延迟与吞吐量
延迟是执行操作或运算结果所花费的时间。吞吐量是单位时间内(执行)此类操作或运算的数量。通常,你应该以可接受级延迟下最大化吞吐量为目标。
一致性与可用性
CAP 理论
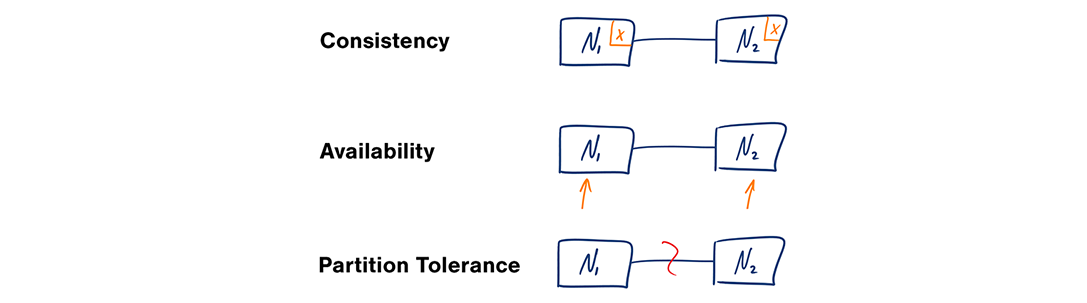
在一个分布式计算系统中,只能同时满足下列的两点:
- 一致性:每次访问都能获得最新数据但可能会收到错误响应;
- 可用性:每次访问都能收到非错响应,但不保证获取到最新数据;
- 分区容错性:在任意分区网络故障的情况下系统仍能继续运行;
网络并不可靠,所以你应要支持分区容错性,并需要在软件一致性和可用性间做出取舍。
CP:一致性和分区容错性
等待分区节点的响应可能会导致延时错误。如果你的业务需求需要原子读写,CP 是一个不错的选择。
AP:可用性和分区容错性
响应节点上可用数据的最近版本可能并不是最新的。当分区解析完后,写入(操作)可能需要一些时间来传播。如果业务需求允许最终一致性,或当有外部故障时要求系统继续运行,AP 是一个不错的选择。
一致性模式
有同一份数据的多份副本,我们面临着怎样同步它们的选择,以便让客户端有一致的显示数据。回想 CAP 理论中的一致性定义 – 每次访问都能获得最新数据但可能会收到错误响应。
弱一致性
在写入之后,访问可能看到,也可能看不到(写入数据)。尽力优化它,让其能访问最新数据。这种方式可以在 Memcached 等系统中看到。弱一致性在 VoIP,视频聊天和实时多人游戏等真实用例中表现不错。例如:如果你在通话中丢失信号几秒钟时间,当重新连接时,你是听不到这几秒钟所说的话的。
强一致性
在写入后,访问立即可见,数据被同步复制。文件系统和 RDBMS 使用的是此种方式。强一致性在需要记录的系统中运作良好。
最终一致性
在写入后,访问最终能看到写入数据,数据被异步复制。DNS 和 Email 等系统使用的是此种方式。最终一致性在 HA 系统中效果不错。
可用性模式
有两种支持高可用性的模式:failover 和 replication。
故障转移
- Active-Passive
关于工作到备用的故障转移流程是:工作服务器发送周期信号给待机中的备用服务器。如果周期信号中断,备用服务器切换成工作服务器的 IP 地址并恢复服务。宕机时间取决于备用服务器处于“热”待机状态,还是需要从“冷”待机状态进行启动。只有工作服务器处理流量。工作到备用的故障转移也被称为主从切换; - Active-Active
在双工作切换中,双方都在管控流量,在它们之间分散负载。如果是外网服务器,DNS 将需要对两方都了解;如果是内网服务器,应用程序逻辑将需要对两方都了解。双工作切换也可以称为主主切换;
故障转移的缺陷:
- 故障转移需要添加额外硬件并增加复杂性;
- 如果新写入数据在能被复制到备用系统之前,工作系统出现了故障,则有可能会丢失数据;
复制
主从复制和主主复制
How many 9s are enough?
Availability is often quantified by uptime (or downtime) as a percentage of time the service is available. Availability is generally measured in number of 9s – a service with 99.99% availability is described as having four 9s.
99.9% availability – three 9s:
| Duration | Acceptable downtime |
|---|---|
| Downtime per year | 8h 45min 57s |
| Downtime per month | 43m 49.7s |
| Downtime per week | 10m 4.8s |
| Downtime per day | 1m 26.4s |
99.99% availability – four 9s:
| Duration | Acceptable downtime |
|---|---|
| Downtime per year | 52min 35.7s |
| Downtime per month | 4m 23s |
| Downtime per week | 1m 5s |
| Downtime per day | 8.6s |
In sequence vs. In parallel
If a service consists of multiple components prone to failure, the service’s overall availability depends on whether the components are in sequence or in parallel:
- In sequence
Overall availability decreases when two components with availability < 100% are in sequence:
If both Foo and Bar each has 99.9% availability, their total availability in sequence would be 99.8%.Availability(Total) = Availability(Foo) * Availability(Bar)
- In parallel
Overall availability increases when two components with availability < 100% are in parallel:
If both Foo and Bar each has 99.9% availability, their total availability in parallel would be 99.9999%.Availability(Total) = 1 - (1 - Availability(Foo)) * (1 - Availability(Bar))