我们学习算法的方法是用 Java 编程语言编写的程序来实现算法,这样做是出于以下原因:
- 程序是对算法精确、优雅和完全的描述;
- 可以通过运行程序来学习算法的各种性质;
- 可以在应用程序中直接使用这些算法;
缺点:使用特定的编程语言,会使分离算法的思想和实现细节变得困难。
我们把描述和实现算法所用到的语言特性、软件库和操作系统特性总称为基础编程模型。
Java 程序的基本结构
一段 Java 程序(类)或者是一个静态方法(函数)库,或者定义一个数据类型,会用到下面七种语法,它们是 Java 语言的基础,也是大多数现代语言所共有的:
- 原始数据类型:在计算机程序中精确地定义整数、浮点数和布尔值等;
- 语句:声明、赋值、条件、循环、调用和返回;
- 数组:多个同种数据类型的值的集合;
- 静态方法:封装并重用代码,使我们可以用独立的模块开发程序;
- 字符串:一连串的字符,Java 内置了对它们的一些操作;
- 标准输入/输出:程序与外界联系的桥梁;
- 数据抽象:使我们可以定义非原始数据类型,进而支持面向对象编程;
要执行一个 Java 程序,首先需要用 javac 命令编译它(*.class),然后再用 java 命令运行它。
原始数据类型与表达式
首先考虑以下四种 Java 语言最基本的原始数据类型:
- 整型,及其算术运算符(
int); - 双精度实数类型,及其算术运算符(
double); - 布尔型,它的值 {true, false} 及其逻辑操作(
boolean); - 字符型,它的值是你能够输入的英文字母数字字符和符号(
char);
指明这些类型的值和对这些类型的操作:
注意:+、-、*、/ 都是被重载过的——根据上下文,同样的运算符对不同类型会执行不同的操作。
表达式
Java 语言规范约定了如下的运算符优先级:* 和 /(以及 %)的优先级高于 + 和 -;在逻辑运算中,! 拥有最高优先级,之后是 &&,接下来是 ||。
类型转换
如果不会损失信息,数值会被自动提升为高级的数据类型。应该小心并尽量少使用类型转换,最好是在表达式中只使用同一类型的字面量和变量。
比较
==、!=、<、<=、> 和 >= 被称为混合类型运算符,因为它们的结果是布尔型,而不是参与比较的数据类型。
其他原始类型
Java 的 int 型能够表示 2^32 个不同的值,用一个字长 32 位的机器字即可表示;与此相似,double 型的标准规定为 64 位。
为了提供更大的灵活性,Java 还提供了其他五种原始数据类型:
- 64 位整数,及其算术运算符(
long); - 16 位整数,及其算术运算符(
short); - 16 位字符,及其算术运算符(
char); - 8 位整数,及其算术运算符(
byte); - 32 位单精度实数,及其算术运算符(
float);
语句
Java 程序是由语句组成的,语句通常会被组织成代码段,即花括号中的一系列语句:
- 声明语句:创建某种类型的变量并用标识符为其命名;
- 赋值语句:将由表达式产生的某种类型的数值赋予一个变量;
- 条件语句:能够简单地改变执行流程——根据指定的条件执行两个代码段之一;
- 循环语句:更彻底地改变执行流程——只要条件为真就不断地反复执行代码中的语句;
- 调用和返回语句:和静态方法有关,是改变执行流程和代码组织的另一种方式;
声明语句
声明语句将一个变量名和一个类型在编译时关联起来。Java 是一种强类型的语言,因为 Java 编译器会检查类型的一致性。
赋值语句
赋值语句将某个数据类型的值和一个变量关联起来。
条件语句
大多数运算都需要用不同的操作来处理不同的输入。在 Java 中表达这种差异的一种方法是 if 语句:
1 | if (<boolean expression>) |
这种描述方式是一种叫做
模版的形式记法,<> 中的是我们已经定义过的语法。
循环语句
许多运算都需要重复:
1 | while (<boolean expression>) |
只要布尔表达式的值为真,就继续执行代码段。
break 和 continue 语句
Java 支持在 while 循环中使用另外两条语句:
- break 语句,立即从循环中退出;
- continue 语句,立即开始下一轮循环;
简便记法
程序有很多种写法,我们追求清晰、优雅和高效的代码。
声明并初始化
可以将声明语句和赋值语句结合起来。最好在接近首次使用变量的地方声明它并将其初始化(为了限制作用域)。
隐式赋值
当希望一个变量的值相对于其当前值变化时,可以使用一些简便的写法:
- 递增/递减运算符,++i 等价于 i=i+1;
- 其他复合运算符,i/=2 等价于 i=i/2;
单语句代码段
即使条件或循环语句的代码段只有一条语句,代码段的花括号也不要省略。
for 语句
很多循环的模式都是这样的:初始化一个索引变量,然后使用 while 循环并将包含索引变量的表达式作为循环的条件,while 循环的最后一条语句会将索引变量加 1。
使用 for 语句可以更紧凑地表达这种循环:
1 | for (<initialize>; <boolean expression>; <increment>) |
这段代码一般等价于:
1 | <initialize>; |
数组
数组能够顺序存储相同类型的多个数据。除了存储数据,我们也希望能够访问数据。访问数组中的某个元素的方法是将其编号然后索引。
创建并初始化数组
在 Java 程序中创建一个数组需要三步:
- 声明数组的名字和类型;
- 创建数组,需要指定数组的长度(元素的个数);
- 初始化数组元素;
完整模式:
1 | double[] a; |
第二条语句中的关键字 new 使 Java 创建了这个数组。我们需要在运行时明确地创建数组的原因是编译器在编译时无法知道应该为数组预留多少空间(对于原始类型则可以)。
使用数组时,一定要依次声明、创建并初始化数组。
简化写法
常常会利用 Java 对数组默认的初始化来将三个步骤合为一条语句:
1 | double[] a = new double[N]; |
等号的左侧声明了数组,等号的右侧创建了数组。
1 | int[] a = {1, 1, 2, 3, 5, 8}; |
第三种方式用花括号将一列由逗号分隔的值,在编译时将数组初始化。
使用数组
在声明并创建数组之后,在代码的任何地方都能通过数组名之后的方括号中的索引来访问其中的元素。数组一经创建,它的大小就是固定的。
起别名
数组名表示的是整个数组——如果我们将一个数组变量赋予另一个变量,那么两个变量将会指向同一个数组。例如以下这段代码:
1 | int[] a = new int[N]; |
这种情况叫做起别名。如果想将数组复制一份,那么应该声明、创建并初始化一个新的数组,然后将原数组中的元素值挨个复制到新数组。
二维数组
在 Java 中二维数组就是一维数组的数组。二维数组可以是参差不齐的(元素数组的长度可以不一致)。
默认的初始化对二维数组更有用,因为可以节约更多的代码。
静态方法
所有 Java 程序要么是数据类型的定义,要么是一个静态方法库。修饰符 static 将这类方法和实例方法区别开来。
静态方法
方法封装了由一系列语句所描述的运算。需要参数并根据参数计算出某种数据类型的返回值或者产生某种副作用。
每个静态方法都是由签名和函数体组成的。
调用静态方法
调用静态方法的方法是写出方法名并在后面的括号中列出参数值,用逗号分隔。
仅由一个方法调用和一个分号组成的语句,一般用于产生副作用。
返回语句将结束静态方法并将控制权交还给调用者。
方法的性质
- 方法的参数按值传递:在方法中参数变量的使用方法和局部变量相同,唯一不同的是参数变量的初始值是由调用方提供的。方法处理的是参数的值,而非参数本身;
- 方法名可以被重载:常见用法是为函数定义两个版本,其中一个需要参数而另一个则为该参数提供默认值;
- 方法只能返回一个值,但可以包含多个返回语句:Java 方法只能返回一个值,它的类型是方法签名中声明的类型;
- 方法可以产生副作用:我们称 void 类型的静态方法会产生副作用,接受输入、产生输出、修改数组或者改变系统状态;
递归
我们会经常使用递归,因为递归代码比相应的非递归代码更加简洁优雅、易懂。
编写递归代码时,最重要的有以下三点:
- 递归总有一个最简单的情况——方法的第一条语句总是一个包含 return 的条件语句;
- 递归调用总是去尝试解决一个规模更小的子问题,这样递归才能收敛到最简单的情况;
- 递归调用的父问题和尝试解决的子问题之间不应该有交集;
基础编程模型
静态方法库是定义在一个 Java 类中的一组静态方法。类的声明是 public class 加上类名,存放类的文件的文件名和类名相同,扩展名是 .java。
Java 开发的基本模式是:编写一个静态方法库来完成一个任务。
模块化编程
通过静态方法库实现了模块化编程。我们可以构造许多个静态方法库(模块),一个库的静态方法也能够调用另一库中定义的静态方法,这样能够带来许多好处:
- 程序整体的代码量很大时,每次处理的模块大小仍然适中;
- 可以共享和重用代码而无需重新实现;
- 很容易用改进的实现替换老的实现;
- 可以为解决编程问题建立合适的抽象模型;
- 缩小调试范围;
单元编程
Java 编程的最佳实践之一就是每个静态方法库中都包含一个 main() 函数来测试库中的所有方法。
每个模块的 main() 方法至少应该调用模块的其他代码并在某种程度上保证它的正确性。
外部库
重用每种库代码的方式都稍有不同,它们大多都是静态方法库:
- 系统标准库 java.lang.*:例如 Math 库,实现了常用的数学函数;
- 导入的系统库:例如 java.util.Arrays;
要调用另一库中的方法(存放在相同或指定的目录中,或是一个系统标准库,或是在类定义前用 import 语句导入的库),我们需要在方法前指定库的名称。
我们自己及他人使用模块化方式编写的方法库,能够极大地扩展我们的编程模型。
API
模块化编程的一个重要组成部分就是记录库方法的用法并供其他人参考的文档。我们会使用应用程序编程接口(API)的方式列出每个库方法名称、签名和简短的描述。
举例
用 java.lang 中 Math 库常用的静态方法说明 API 的文档格式:
Java 库
Arrays 库不在 java.lang 中,因此我们需要用 import 语句导入后才能使用它。
为了避免混淆,我们一般会使用自己的实现,但对于你已经掌握的算法使用高度优化的库实现当然也没有任何问题。
我们的标准库
为了介绍 Java 编程、为了科学计算以及算法的开发、学习和应用,我们也开发了若干库来提供一些实用的功能。这些库大多用于处理输入输出。
第一个库扩展了 Math.random() 方法,以根据不同的概率密度函数得到随机值;第二个库则支持各种统计计算:
设计良好的方法库:
- 这些方法所实现的抽象层有助于我们将精力集中在实现和测试算法,而非生成随机数或是统计计算;
- 方法库会经过大量测试,覆盖极端和罕见的情况,是我们可以信任的。这样的实现需要大量的代码;
自己编写的库
将自己编写的每一个程序都当作一个日后可以重用的库:
- 编写用例,在实现中将计算过程分解成可控的部分;
- 明确静态方法库和与之对应的 API;
- 实现 API 和一个能够对方法进行独立测试的 main() 函数;
API 的目的是将调用和实现分离:除了 API 给出的信息,调用者不需要知道实现的其他细节,而实现也不应考虑特殊的应用场景。
相应地,程序员也可以将 API 看作调用和实现之间的一份契约,它详细说明了每个方法的作用。实现的目标就是能够遵守这份契约。
字符串
一个 String 类型的字面量包括一对双引号和其中的字符(char)。String 类型是 Java 的一个数据类型,但并不是原始数据类型。
字符串拼接
Java 内置了一个串联 String 类型字符串的运算符:“+”。
类型转换
字符串的两个主要用途:
- 将用户从键盘输入的内容转换成相应数据类型的值;
- 将各种数据类型的值转化成能够在屏幕上显示的内容;

自动转换
我们很少明确使用 toString() 方法,因为 Java 在连接字符串的时候会自动将任意数据类型的值转换为字符串:
如果“+”的一个参数是字符串,那么 Java 会自动将其他参数都转换为字符串。
命令行参数
在 Java 中字符串的一个重要的用途就是使程序能够接收到从命令行传递来的信息。
当你输入命令 java 和一个库名以及一系列字符串之后,Java 系统会调用库的 main() 方法并将那一系列字符串变成一个数组作为参数传递给它。
字符串的用法是现代程序中的重要部分。
输入输出
我们的标准输入、输出和绘图库的作用是建立一个 Java 程序和外界交流的简易模型。默认情况下,命令行参数、标准输入和标准输出是和应用程序绑定的,而应用程序是由能够接受命令输入的操作系统或是开发环境所支持。
我们笼统地用终端来指代这个应用程序提供的供输入和显示的窗口。
命令和参数
Java 类都会包含一个静态方法 main(),它有一个 String 数组类型的参数 args[]。这个数组的内容就是我们输入的命令行参数,操作系统会将它传递给 Java。
标准输出
一般来说,系统会将标准输出打印到终端窗口:
- print() 方法会将它的参数放到标准输出中;
- pirntln() 方法会附加一个换行符;
- pirntf() 方法能够格式化输出;
格式化输出
printf() 方法接受两个参数。第一个参数是一个格式字符串,描述了第二个参数应该如何在输出中被转换为一个字符串。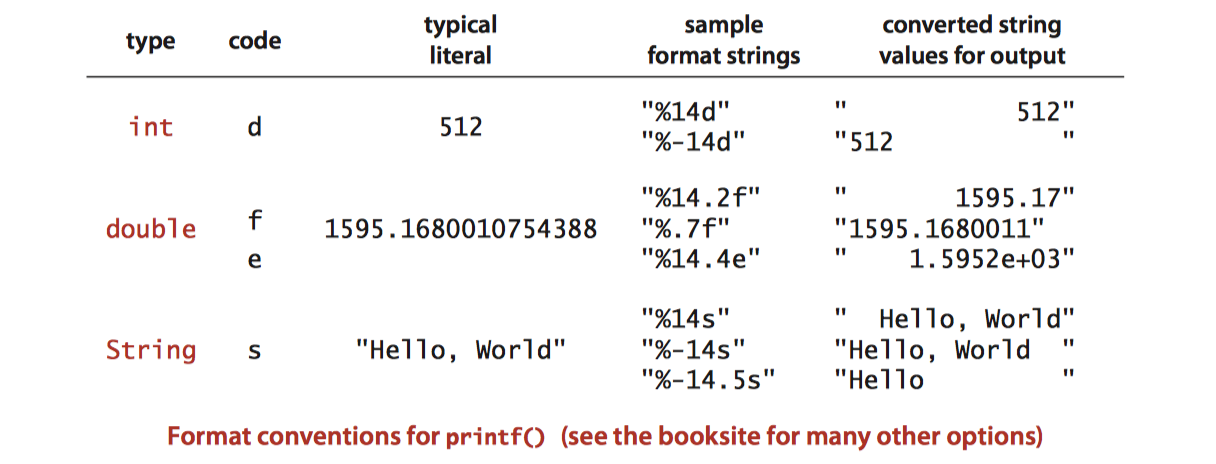
标准输入
StdIn 库从标准输入流中获取数据,这些数据可能为空也可能是一系列由空白字符分隔的值(空格、制表符、换行符等)。默认状态下,系统会将标准输出定向到终端窗口——你输入的内容就是输入流(由 <ctrl+d> 结束)。
只要程序读取了一个值,它就不能回退并再次读取它。这个特点产生了一些限制,但它反映了一些输入设备的物理特性并简化了对这些设备的抽象。
重定向与管道
标准输入输出使我们能够利用许多操作系统都支持的命令行的扩展功能。
向启动程序的命令中加入一个简单的提示符,就可以将它的标准输出重定向至一个文件:
1 | $ java RandomSep 1000 100.0 200.0 > data.txt |
我们可以重定向标准输入以使 StdIn 从文件而不是终端应用程序中读取数据:
1 | $ java Average < data.txt |
将这些结合起来,将一个程序的输出重定向为另一个程序的输入叫做管道:
1 | $ java RandomSep 1000 100.0 200.0 | java Average |
突破了我们能够处理的输入输出流的长度限制。我们的程序不再需要担心细节,因为它们只会和标准输入和标准输出的抽象打交道。
基于文件的输入输出
In 和 Out 两个库也实现了一些数据类型和它们的实例方法,这使我们能够将多个文件作为输入输出流并将网页作为输入流(name 参数可以是文件或网页):
标准绘图库(基本方法)
我们要介绍一个产生图像输出的抽象层。这个库的使用非常简单并且允许我们利用可视化的方式处理比文字丰富得多的信息:
标准绘图库(控制方法)
标准绘图库中还包含了一些方法来改变画布的大小和比例、直线的颜色和宽度、文本字体、绘图时间等:
绘图库支持动画,我们会在数据分析和算法的可视化中使用 StdDraw。
二分查找
展示学习新算法的基本方法。
二分查找
1 | import java.util.Arrays |
这段程序接受一个白名单文件作为参数,并会过滤掉标准输入中的所有存在于白名单中的条目,仅将不在白名单上的整数打印到标准输出中。
开发用例
对于每个算法的实现,我们都会开发一个用例 main() 函数,并提供一个示例输入文件来辅助学习该算法并检测它的性能。
白名单过滤
如果可能,我们的测试用例都会通过模拟实际情况来展示当前算法的必要性。这里该过程被称为白名单过滤。
性能
一个程序只是可用往往是不够的。没有如二分查找或者归并排序这样的高效算法,解决大规模的白名单问题是不可能的。良好的性能常常是极为重要的。
基础编程模型的目标是:确保你能够在计算机上运行类似于 BinarySearch 的代码,使用它处理我们的测试数据并为适应各种情况修改它,以完全理解它的可应用性。
展望
现代编程技术已经更进一步,前进的这一步被称为数据抽象,有时也被称为面向对象编程。简单地说,数据抽象的主要思想是鼓励程序定义自己的数据类型,而不仅仅是那些操作预定义的数据类型的静态方法。
“拥抱”数据抽象的原因主要有三:
- 它允许我们通过模块化编程复用代码;
- 它使我们可以轻易构造出多种所谓的
链式数据结构,它们比数组更灵活,在许多情况下都是高效算法的基础; - 借助它我们可以准确地定义所面对的算法问题;