为什么要使用单例?
单例设计模式(Singleton Design Pattern)理解起来非常简单。一个类只允许创建一个对象(或者实例),那这个类就是一个单例类,这种设计模式就叫作单例设计模式,简称单例模式。
实战案例一:处理资源访问冲突
在这个例子中,我们自定义实现了一个往文件中打印日志的 Logger 类。具体的代码实现如下所示:
1 | public class Logger |
在上面的代码中,我们注意到,所有的日志都写入到同一个文件 /Users/wangzheng/log.txt 中。在 UserController 和 OrderController 中,我们分别创建两个 Logger 对象。在 Web 容器的 Servlet 多线程环境下,如果两个 Servlet 线程同时分别执行 login() 和 create() 两个函数,并且同时写日志到 log.txt 文件中,那就有可能存在日志信息互相覆盖的情况。
那如何来解决这个问题呢?我们最先想到的就是通过加锁的方式:给 log() 函数加互斥锁(Java 中可以通过 synchronized 的关键字),同一时刻只允许一个线程调用执行 log() 函数。具体的代码实现如下所示:
1 | public class Logger |
不过,你仔细想想,这真的能解决多线程写入日志时互相覆盖的问题吗?答案是否定的。这是因为,这种锁是一个对象级别的锁,一个对象在不同的线程下同时调用 log() 函数,会被强制要求顺序执行。但是,不同的对象之间并不共享同一把锁。在不同的线程下,通过不同的对象调用执行 log() 函数,锁并不会起作用,仍然有可能存在写入日志互相覆盖的问题: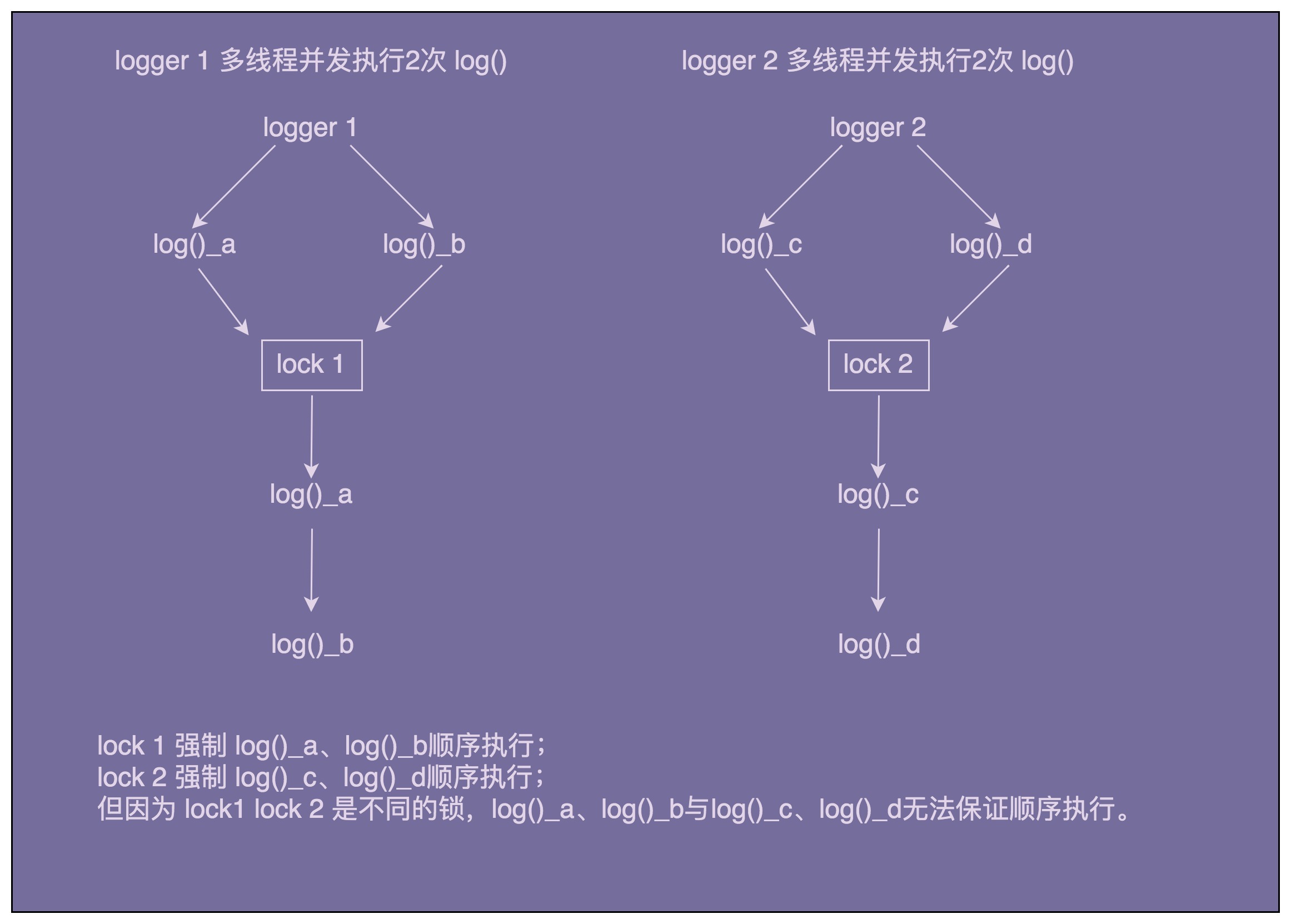
我这里稍微补充一下,在刚刚的讲解和给出的代码中,我故意“隐瞒”了一个事实:我们给 log() 函数加不加对象级别的锁,其实都没有关系。因为 FileWriter 本身就是线程安全的,它的内部实现中本身就加了对象级别的锁,因此,在外层调用 write() 函数的时候,再加对象级别的锁实际上是多此一举。
那我们该怎么解决这个问题呢?实际上,要想解决这个问题也不难,我们只需要把对象级别的锁,换成类级别的锁就可以了。让所有的对象都共享同一把锁。这样就避免了不同对象之间同时调用 log() 函数,而导致的日志覆盖问题。具体的代码实现如下所示:
1 | public class Logger |
除了使用类级别锁之外,实际上,解决资源竞争问题的办法还有很多,分布式锁是最常听到的一种解决方案。不过,实现一个安全可靠、无 bug、高性能的分布式锁,并不是件容易的事情。除此之外,并发队列(比如 Java 中的 BlockingQueue)也可以解决这个问题:多个线程同时往并发队列里写日志,一个单独的线程负责将并发队列中的数据,写入到日志文件。这种方式实现起来也稍微有点复杂。
相对于这两种解决方案,单例模式的解决思路就简单一些了。单例模式相对于之前类级别锁的好处是,不用创建那么多 Logger 对象,一方面节省内存空间,另一方面节省系统文件句柄(对于操作系统来说,文件句柄也是一种资源,不能随便浪费)。
我们将 Logger 设计成一个单例类,程序中只允许创建一个 Logger 对象,所有的线程共享使用的这一个 Logger 对象,共享一个 FileWriter 对象,而 FileWriter 本身是对象级别线程安全的,也就避免了多线程情况下写日志会互相覆盖的问题:
1 | public class Logger |
实战案例二:表示全局唯一类
从业务概念上,如果有些数据在系统中只应保存一份,那就比较适合设计为单例类。
比如,配置信息类。在系统中,我们只有一个配置文件,当配置文件被加载到内存之后,以对象的形式存在,也理所应当只有一份。再比如,唯一递增 ID 号码生成器。如果程序中有两个对象,那就会存在生成重复 ID 的情况,所以,我们应该将 ID 生成器类设计为单例:
1 | import java.util.concurrent.atomic.AtomicLong; |
如何实现一个单例?
概括起来,要实现一个单例,我们需要关注的点无外乎下面几个:
- 构造函数需要是 private 访问权限的,这样才能避免外部通过 new 创建实例;
- 考虑对象创建时的线程安全问题;
- 考虑是否支持延迟加载;
- 考虑 getInstance() 性能是否高(是否加锁);
饿汉式
饿汉式的实现方式比较简单。在类加载的时候,instance 静态实例就已经创建并初始化好了,所以,instance 实例的创建过程是线程安全的。不过,这样的实现方式不支持延迟加载(在真正用到 IdGenerator 的时候,再创建实例),从名字中我们也可以看出这一点。具体的代码实现如下所示:
1 | public class IdGenerator |
有人觉得这种实现方式不好,因为不支持延迟加载,如果实例占用资源多(比如占用内存多)或初始化耗时长(比如需要加载各种配置文件),提前初始化实例是一种浪费资源的行为。最好的方法应该在用到的时候再去初始化。不过,我个人并不认同这样的观点。
如果初始化耗时长,那我们最好不要等到真正要用它的时候,才去执行这个耗时长的初始化过程,这会影响到系统的性能(比如,在响应客户端接口请求的时候,做这个初始化操作,会导致此请求的响应时间变长,甚至超时)。采用饿汉式实现方式,将耗时的初始化操作,提前到程序启动的时候完成,这样就能避免在程序运行的时候,再去初始化导致的性能问题。
如果实例占用资源多,按照 fail-fast 的设计原则,那我们也希望在程序启动时就将这个实例初始化好。如果资源不够,就会在程序启动的时候触发报错(比如 Java 中的 PermGen Space OOM),我们可以立即去修复。这样也能避免在程序运行一段时间后,突然因为初始化这个实例占用资源过多,导致系统崩溃,影响系统的可用性。
懒汉式
懒汉式相对于饿汉式的优势是支持延迟加载。具体的代码实现如下所示:
1 | public class IdGenerator |
不过懒汉式的缺点也很明显,我们给 getInstance() 这个方法加了一把大锁(synchronized),导致这个函数的并发度很低。量化一下的话,并发度是 1,也就相当于串行操作了。而这个函数是在单例使用期间,一直会被调用。如果这个单例类偶尔会被用到,那这种实现方式还可以接受。但是,如果频繁地用到,那频繁加锁、释放锁及并发度低等问题,会导致性能瓶颈,这种实现方式就不可取了。
双重检测
饿汉式不支持延迟加载,懒汉式有性能问题,不支持高并发。那我们再来看一种既支持延迟加载、又支持高并发的单例实现方式,也就是双重检测实现方式。在这种实现方式中,只要 instance 被创建之后,即便再调用 getInstance() 函数也不会再进入到加锁逻辑中了。所以,这种实现方式解决了懒汉式并发度低的问题。具体的代码实现如下所示:
1 | public class IdGenerator |
网上有人说,这种实现方式有些问题。因为指令重排序,可能会导致 IdGenerator 对象被 new 出来,并且赋值给 instance 之后,还没来得及初始化(执行构造函数中的代码逻辑),就被另一个线程使用了。我们现在用的高版本的 Java 已经在 JDK 内部实现中解决了这个问题(解决的方法很简单,只要把对象 new 操作和初始化操作设计为原子操作,就自然能禁止重排序)。
静态内部类
我们再来看一种比双重检测更加简单的实现方法,那就是利用 Java 的静态内部类。它有点类似饿汉式,但又能做到了延迟加载:
1 | public class IdGenerator |
SingletonHolder 是一个静态内部类,当外部类 IdGenerator 被加载的时候,并不会创建 SingletonHolder 实例对象。只有当调用 getInstance() 方法时,SingletonHolder 才会被加载,这个时候才会创建 instance。instance 的唯一性、创建过程的线程安全性,都由 JVM 来保证。所以,这种实现方法既保证了线程安全,又能做到延迟加载。
枚举
我们介绍一种最简单的实现方式,基于枚举类型的单例实现。这种实现方式通过 Java 枚举类型本身的特性,保证了实例创建的线程安全性和实例的唯一性。具体的代码如下所示:
1 | public enum IdGenerator |
单例存在哪些问题?
大部分情况下,我们在项目中使用单例,都是用它来表示一些全局唯一类,比如配置信息类、连接池类、ID 生成器类。单例模式书写简洁、使用方便,在代码中,我们不需要创建对象,直接通过类似 IdGenerator.getInstance().getId() 这样的方法来调用就可以了。但是,这种使用方法有点类似 hard code,会带来诸多问题。
单例对 OOP 特性的支持不友好
我们知道,OOP 的四大特性是封装、抽象、继承、多态。单例这种设计模式对于其中的抽象、继承、多态都支持得不好:
1 | public class Order |
IdGenerator 的使用方式违背了基于接口而非实现的设计原则,也就违背了广义上理解的 OOP 的抽象特性。如果未来某一天,我们希望针对不同的业务采用不同的 ID 生成算法。比如,订单 ID 和用户 ID 采用不同的 ID 生成器来生成。为了应对这个需求变化,我们需要修改所有用到 IdGenerator 类的地方:
1 | public class Order |
除此之外,单例对继承、多态特性的支持也不友好。这里我之所以会用“不友好”这个词,而非“完全不支持”,是因为从理论上来讲,单例类也可以被继承、也可以实现多态,只是实现起来会非常奇怪,会导致代码的可读性变差。不明白设计意图的人,看到这样的设计,会觉得莫名其妙。所以,一旦你选择将某个类设计成到单例类,也就意味着放弃了继承和多态这两个强有力的面向对象特性,也就相当于损失了可以应对未来需求变化的扩展性。
单例会隐藏类之间的依赖关系
我们知道,代码的可读性非常重要。在阅读代码的时候,我们希望一眼就能看出类与类之间的依赖关系,搞清楚这个类依赖了哪些外部类。
通过构造函数、参数传递等方式声明的类之间的依赖关系,我们通过查看函数的定义,就能很容易识别出来。但是,单例类不需要显示创建、不需要依赖参数传递,在函数中直接调用就可以了。如果代码比较复杂,这种调用关系就会非常隐蔽。在阅读代码的时候,我们就需要仔细查看每个函数的代码实现,才能知道这个类到底依赖了哪些单例类。
单例对代码的扩展性不友好
我们知道,单例类只能有一个对象实例。如果未来某一天,我们需要在代码中创建两个实例或多个实例,那就要对代码有比较大的改动。我们拿数据库连接池来举例解释一下,在系统设计初期,我们觉得系统中只应该有一个数据库连接池,这样能方便我们控制对数据库连接资源的消耗。所以,我们把数据库连接池类设计成了单例类。但之后我们发现,系统中有些 SQL 语句运行得非常慢。这些 SQL 语句在执行的时候,长时间占用数据库连接资源,导致其他 SQL 请求无法响应。
为了解决这个问题,我们希望将慢 SQL 与其他 SQL 隔离开来执行。为了实现这样的目的,我们可以在系统中创建两个数据库连接池,慢 SQL 独享一个数据库连接池,其他 SQL 独享另外一个数据库连接池,这样就能避免慢 SQL 影响到其他 SQL 的执行。如果我们将数据库连接池设计成单例类,显然就无法适应这样的需求变更,也就是说,单例类在某些情况下会影响代码的扩展性、灵活性。所以,数据库连接池、线程池这类的资源池,最好还是不要设计成单例类。
单例对代码的可测试性不友好
单例模式的使用会影响到代码的可测试性。如果单例类依赖比较重的外部资源,比如 DB,我们在写单元测试的时候,希望能通过 mock 的方式将它替换掉。而单例类这种硬编码式的使用方式,导致无法实现 mock 替换。
除此之外,如果单例类持有成员变量(比如 IdGenerator 中的 id 成员变量),那它实际上相当于一种全局变量,被所有的代码共享。如果这个全局变量是一个可变全局变量,也就是说,它的成员变量是可以被修改的,那我们在编写单元测试的时候,还需要注意不同测试用例之间,修改了单例类中的同一个成员变量的值,从而导致测试结果互相影响的问题。
单例不支持有参数的构造函数
单例不支持有参数的构造函数,比如我们创建一个连接池的单例对象,我们没法通过参数来指定连接池的大小。针对这个问题,我们来看下都有哪些解决方案。
创建完实例之后,再调用 init() 函数传递参数。需要注意的是,我们在使用这个单例类的时候,要先调用 init() 方法,然后才能调用 getInstance() 方法,否则代码会抛出异常。具体的代码实现如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34public class Singleton
{
private static Singleton instance = null;
private final int paramA;
private final int paramB;
private Singleton(int paramA, int paramB)
{
this.paramA = paramA;
this.paramB = paramB;
}
public static Singleton getInstance()
{
if (instance == null)
{
throw new RuntimeException("Run init() first.");
}
return instance;
}
public synchronized static Singleton init(int paramA, int paramB)
{
if (instance != null)
{
throw new RuntimeException("Singleton has been created!");
}
instance = new Singleton(paramA, paramB);
return instance;
}
}
Singleton.init(10, 50); // 先 init,再使用
Singleton singleton = Singleton.getInstance();将参数放到 getInstance() 方法中。具体的代码实现如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public class Singleton
{
private static Singleton instance = null;
private final int paramA;
private final int paramB;
private Singleton(int paramA, int paramB)
{
this.paramA = paramA;
this.paramB = paramB;
}
public synchronized static Singleton getInstance(int paramA, int paramB)
{
if (instance == null)
{
instance = new Singleton(paramA, paramB);
}
return instance;
}
}
Singleton singleton = Singleton.getInstance(10, 50);不知道你有没有发现,上面的代码实现稍微有点问题。如果我们如下两次执行 getInstance() 方法,那获取到的 singleton1 和 singleton2 的 paramA 和 paramB 都是 10 和 50。也就是说,第二次的参数(20,30)没有起作用,而构建的过程也没有给与提示,这样就会误导用户:
1
2Singleton singleton1 = Singleton.getInstance(10, 50);
Singleton singleton2 = Singleton.getInstance(20, 30);将参数放到另外一个全局变量中。具体的代码实现如下。Config 是一个存储了 paramA 和 paramB 值的全局变量。里面的值既可以通过静态常量来定义,也可以从配置文件中加载得到。实际上,这种方式是最值得推荐的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27public class Config
{
public static final int PARAM_A = 123;
public static final int PARAM_B = 245;
}
public class Singleton
{
private static Singleton instance = null;
private final int paramA;
private final int paramB;
private Singleton()
{
this.paramA = Config.PARAM_A;
this.paramB = Config.PARAM_B;
}
public synchronized static Singleton getInstance()
{
if (instance == null)
{
instance = new Singleton();
}
return instance;
}
}
有何替代解决方案?
为了保证全局唯一,除了使用单例,我们还可以用静态方法来实现。这也是项目开发中经常用到的一种实现思路:
1 | // 静态方法实现方式 |
不过,静态方法这种实现思路,并不能解决我们之前提到的问题。实际上,它比单例更加不灵活,比如,它无法支持延迟加载。实际上,单例除了我们之前讲到的使用方法之外,还有另外一种使用方法:
1 | // 1. 老的使用方式 |
基于新的使用方式,我们将单例生成的对象,作为参数传递给函数(也可以通过构造函数传递给类的成员变量),可以解决单例隐藏类之间依赖关系的问题。不过,对于单例存在的其他问题,比如对 OOP 特性、扩展性、可测性不友好等问题,还是无法解决。
实际上,类对象的全局唯一性可以通过多种不同的方式来保证。我们既可以通过单例模式来强制保证,也可以通过工厂模式、IoC 容器(比如 Spring IoC 容器)来保证,还可以通过程序员自己来保证(自己在编写代码的时候自己保证不要创建两个类对象)。这就类似 Java 中内存对象的释放由 JVM 来负责,而 C++ 中由程序员自己负责,道理是一样的。
如何理解单例模式中的唯一性?
我们编写的代码,通过编译、链接,组织在一起,就构成了一个操作系统可以执行的文件,也就是我们平时所说的“可执行文件”(比如 Windows 下的 exe 文件)。可执行文件实际上就是代码被翻译成操作系统可理解的一组指令,你完全可以简单地理解为就是代码本身。
当我们使用命令行或者双击运行这个可执行文件的时候,操作系统会启动一个进程,将这个执行文件从磁盘加载到自己的进程地址空间(可以理解操作系统为进程分配的内存存储区,用来存储代码和数据)。接着,进程就一条一条地执行可执行文件中包含的代码。比如,当进程读到代码中的 User user = new User(); 这条语句的时候,它就在自己的地址空间中创建一个 user 临时变量和一个 User 对象。
进程之间是不共享地址空间的,如果我们在一个进程中创建另外一个进程(比如,代码中有一个 fork() 语句,进程执行到这条语句的时候会创建一个新的进程),操作系统会给新进程分配新的地址空间,并且将老进程地址空间的所有内容,重新拷贝一份到新进程的地址空间中,这些内容包括代码、数据(比如 user 临时变量、User 对象)。
所以,单例类在老进程中存在且只能存在一个对象,在新进程中也会存在且只能存在一个对象。而且,这两个对象并不是同一个对象,这也就说,单例类中对象的唯一性的作用范围是进程内的,在进程间是不唯一的。
如何实现线程唯一的单例?
“进程唯一”指的是进程内唯一,进程间不唯一。类比一下,“线程唯一”指的是线程内唯一,线程间可以不唯一。实际上,“进程唯一”还代表了线程内、线程间都唯一,这也是“进程唯一”和“线程唯一”的区别之处。
假设 IdGenerator 是一个线程唯一的单例类。在线程 A 内,我们可以创建一个单例对象 a。因为线程内唯一,在线程 A 内就不能再创建新的 IdGenerator 对象了,而线程间可以不唯一,所以,在另外一个线程 B 内,我们还可以重新创建一个新的单例对象 b。
线程唯一单例的代码实现很简单,如下所示。在代码中,我们通过一个 HashMap 来存储对象,其中 key 是线程 ID,value 是对象。这样我们就可以做到,不同的线程对应不同的对象,同一个线程只能对应一个对象。实际上,Java 语言本身提供了 ThreadLocal 工具类,可以更加轻松地实现线程唯一单例(底层实现原理也是基于 HashMap):
1 | public class IdGenerator |
如何实现集群环境下的单例?
集群相当于多个进程构成的一个集合,“集群唯一”就相当于是进程内唯一、进程间也唯一。也就是说,不同的进程间共享同一个对象,不能创建同一个类的多个对象。
具体来说,我们需要把这个单例对象序列化并存储到外部共享存储区(比如文件)。进程在使用这个单例对象的时候,需要先从外部共享存储区中将它读取到内存,并反序列化成对象,然后再使用,使用完成之后还需要再存储回外部共享存储区。
为了保证任何时刻,在进程间都只有一份对象存在,一个进程在获取到对象之后,需要对对象加锁,避免其他进程再将其获取。在进程使用完这个对象之后,还需要显式地将对象从内存中删除,并且释放对对象的加锁:
1 | public class IdGenerator |
如何实现一个多例模式?
“单例”指的是,一个类只能创建一个对象。对应地,“多例”指的就是,一个类可以创建多个对象,但是个数是有限制的,比如只能创建 3 个对象:
1 | public class BackendServer |
实际上,对于多例模式,还有一种理解方式:同一类型的只能创建一个对象,不同类型的可以创建多个对象。在代码中,loggerName 就是刚刚说的“类型”,同一个 loggerName 获取到的对象实例是相同的,不同的 loggerName 获取到的对象实例是不同的:
1 | public class Logger |
这种多例模式的理解方式有点类似工厂模式。它跟工厂模式的不同之处是,多例模式创建的对象都是同一个类的对象,而工厂模式创建的是不同子类的对象。除此之外,枚举类型也相当于多例模式,一个类型只能对应一个对象,一个类可以创建多个对象。