分布式系统和大数据处理平台是目前业界关注的热门技术。三大重量级武器:Hadoop、Spark、Storm,以及新一代的数据采集和分析引擎 Elasticsearch。
实际上,摩尔定律的失效,必将导致越来越多的复杂任务必须采用分布式架构进行处理。已有的开源平台提供了很好的实现参考,方便用户将更多的精力放到核心业务的维护上。
Hadoop
Hadoop 是 Apache 软件基金会旗下的一个开源分布式计算平台,基于 Java 语言实现,由三个核心子系统组成:HDFS、YARN、MapReduce。其中,HDFS 是一套分布式文件系统;YARN 是资源管理系统,MapReduce 是运行在 YARN 上的应用,负责分布式处理管理。
核心子系统说明如下:
- HDFS:一个高度容错性的分布式文件系统,适合部署在大量廉价的机器上,提供高吞吐量的数据访问;
- YARN:资源管理器,可为上层应用提供统一的资源管理和调度,兼容多计算框架;
- MapReduce:是一种分布式编程模型,把大规模数据集的处理,
分发(Map)给网络上的多个节点,之后收集处理结果进行规约(Reduce)。
Hadoop 还包括 HBase(列数据库)、Cassandra(分布式数据库)、Hive(支持 SQL 语句)、Pig(流处理引擎)、Zookeeper(分布式应用协调服务)等相关项目,其生态系统如下: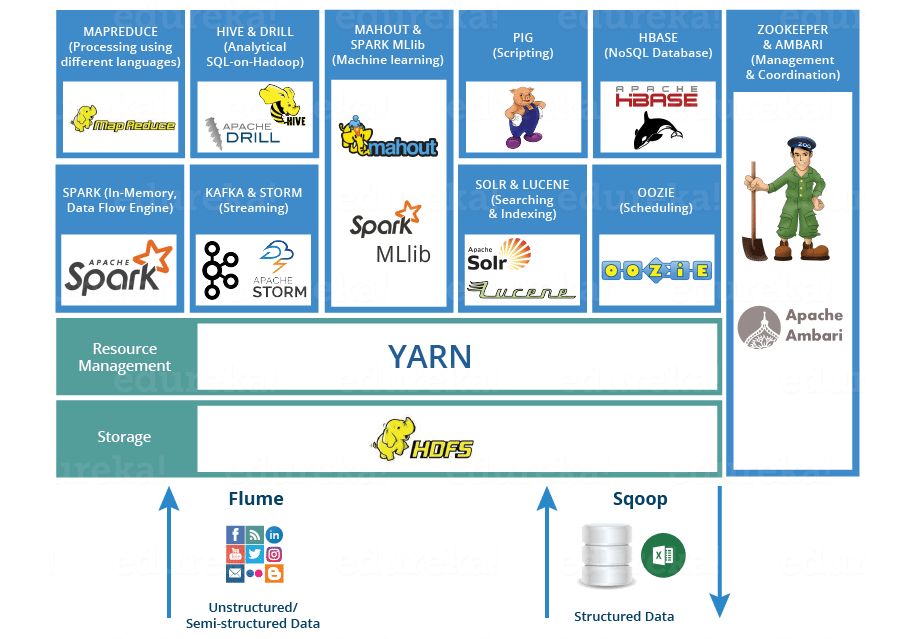
Spark
Apache Spark 是一个围绕速度、易用性和复杂分析构建的大数据处理框架,基于 Scala 开发。
除了 Spark 核心 API 之外,Spark 生态系统中还包括其他附加库,可以在大数据分析和机器学习领域提供更多的能力。这些库包括:Spark Streaming(用于构建弹性容错的流处理 App)、Spark SQL(支持 SQL 语句以及结构化数据处理)、Spark MLlib(用于机器学习)、Spark GraphX(用于图数据处理)。
包括三个主要组件:驱动程序、集群管理器、工作者节点: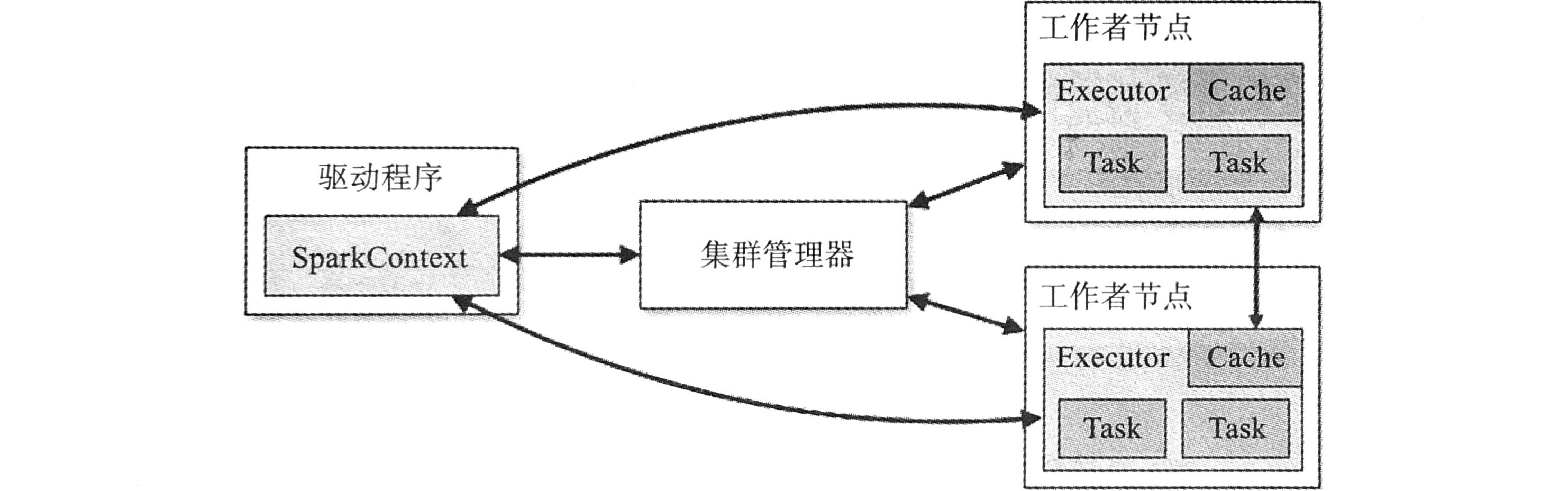
Storm
Apache Storm 是一个实时流计算框架,由 Twitter 在 2014 年正式开源,基于 Clojure 语言实现。
与 Hadoop 集群在工作方式上十分相似:
- Hadoop 上运行的是 MapReduce 任务,完成处理即会结束;
- Storm 上运行的是 topology,永远在等待消息并处理。
Storm 集群中有两种节点:主节点和工作节点:
- 主节点运行一个叫
Nimbus的守护进程,负责向集群中分发代码,向各机器分配任务,以及监测故障; - 工作节点运行
Supervisor守护进程,负责监听 Nimbus 指派到机器的任务,根据指派信息来管理工作者进程,执行一个 topology 的任务子集。
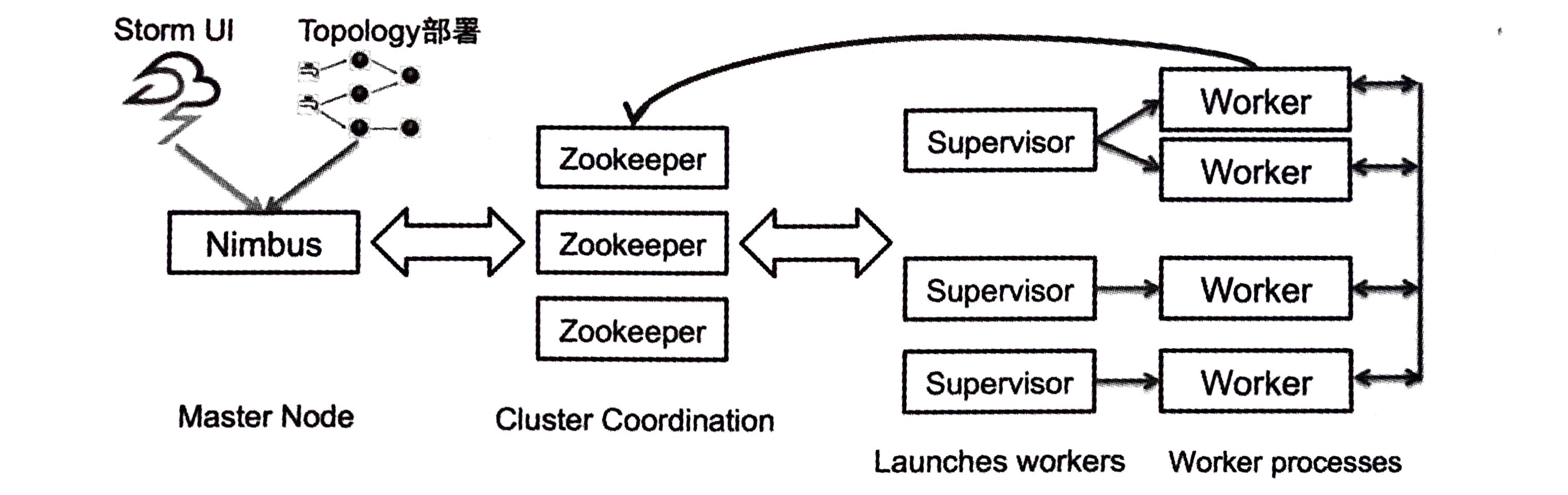
Nimbus 和 Supervisors 之间的所有协调调度通过 Zookeeper 集群来完成。另外,Nimbus 和 Supervisor 都是快速失败和无状态的,实现极高的稳定度。
Elasticsearch
Elasticsearch 是基于 Java 的分布式、多租户的全文搜索引擎,支持 RESTful 接口。
支持实时分布式数据存储和分析查询功能,可以轻松扩展到上百万台服务器,同时支持处理 PB 级结构化或非结构化数据。