函数
Python 是一门支持面向对象的编程语言,但除此之外,Python 对函数的支持也毫不逊色。函数在 Python 中是一等对象,这意味着我们可以把函数自身作为函数参数来使用。
函数参数的常用技巧
参数(Parameter)是函数的重要组成部分,它是函数最主要的输入源,决定了调用方使用函数时的体验。Python 函数的参数默认值只会在函数定义阶段被创建一次,别将可变类型作为参数默认值,使用 None 来替代:
1 | def append_value(value, items=[]): |
1 | def append_value(value, items=None): |
定义一个特殊对象(标记变量)作为参数默认值,严格区分调用方是不是真的提供了这个默认参数:
1 | # object 通常不会单独使用,但是拿来做这种标记变量刚刚好 |
More than three (polyadic) requires very special justification -- and then shouldn’t be used anyway.
-- Clean Code
Python 里的函数不光支持通过有序位置参数(Positional Argument)调用,还能指定参数名,通过关键字参数(Keyword Argument)的方式调用。当你要调用参数超过 3 个的函数时,使用关键字参数模式可以大大提高代码的可读性,通过在参数列表中插入 * 符号,该符号后的所有参数都变成了仅限关键字参数:
1 | def query_users(limit, offset, *, min_followers_count, include_profile): |
1 | >>> query_users(20, 0, min_followers_count=100, include_profile=True) |
函数返回的常见模式
好的函数设计一定是简单的,这种简单体现在各个方面,返回多种类型明显违反了简单原则。这种做法不光会给函数本身增加不必要的复杂度,还会提高用户理解和使用函数的成本,尽量只返回一种类型。
适合返回 None 的函数需要满足以下两个特点:
- 函数的名称和参数必须表达结果可能缺失的意思;
- 操作类函数不需要任何返回值时,通常会返回 None(默认);
除了搜索、查询几个场景外,对绝大部分函数而言,返回 None 并不是一个好的做法。用抛出异常来替代返回 None 会更为合理,调用方可以从异常对象里获取错误原因。
对于读代码的人来说,return 是一种有效的思维减负工具。因此,在编写函数时,请不要纠结函数是不是应该只有一个 return,只要尽早返回结果可以提升代码可读性,那就多多返回吧:
1 | def user_get_tweets(user): |
1 | def user_get_tweets(user): |
常用函数模块:functools
functools 模块提供的高阶函数(High-order Function)partial 的调用方式为:partial(func, *args, **kwargs):
- func 是完成具体功能的原函数;
- *args/**kwargs 是可选位置与关键字参数,必须是原函数 func 所接收的合法参数;
首先有一个接收许多参数的函数 a,然后额外定义一个接收更少参数的函数 b,通过在 b 内部补充一些预设参数,最后返回调用 a 函数的结果:
1 | def multiply(x, y): |
1 | from functools import partial |
在缓存方面,functools 模块为我们提供了一个开箱即用的工具:lru_cache(),它可以传入一个可选的 maxsize 参数,该参数代表当前函数最多可以保存多少个缓存结果。如果你把 maxsize 设置为 None,函数就会保存每一个执行结果,不再剔除任何旧缓存,这时如果被缓存的内容太多,就会有占用过多内存的风险。
编程建议
在函数式编程(Functional Programming)领域,纯函数(Pure Function)是一种无状态的函数。相比有状态函数,无状态函数的逻辑通常更容易理解;在并发编程时,无状态函数也有着无须处理状态相关问题的天然优势。
That said, if you want to write routines longer than about 200 lines, be careful.
-- Code Complete
假如你的函数超过 65 行,很大概率代表函数已经过于复杂,承担了太多职责,请考虑将它拆分为多个小而简单的子函数(类)吧;圈复杂度(Cyclomatic Complexity)是一个正整数,代表程序内线性独立路径的数量,如果某个函数的圈复杂度超过 10,就代表它已经太复杂了,代码编写者应该想办法简化。我们一般不会在每次写完代码后,都手动执行一次 radon 命令,而会将这种检查配置到开发或部署流程中自动执行。
通用领域的抽象,是指在面对复杂事物(或概念)时,主动过滤掉不需要的细节,只关注与当前目的有关的信息的过程。在计算机科学领域,分层思想就是其中最重要的概念之一,低级的抽象层里包含较多的实现细节,随着层级变高,细节越来越少,越接近我们想要解决的实际问题: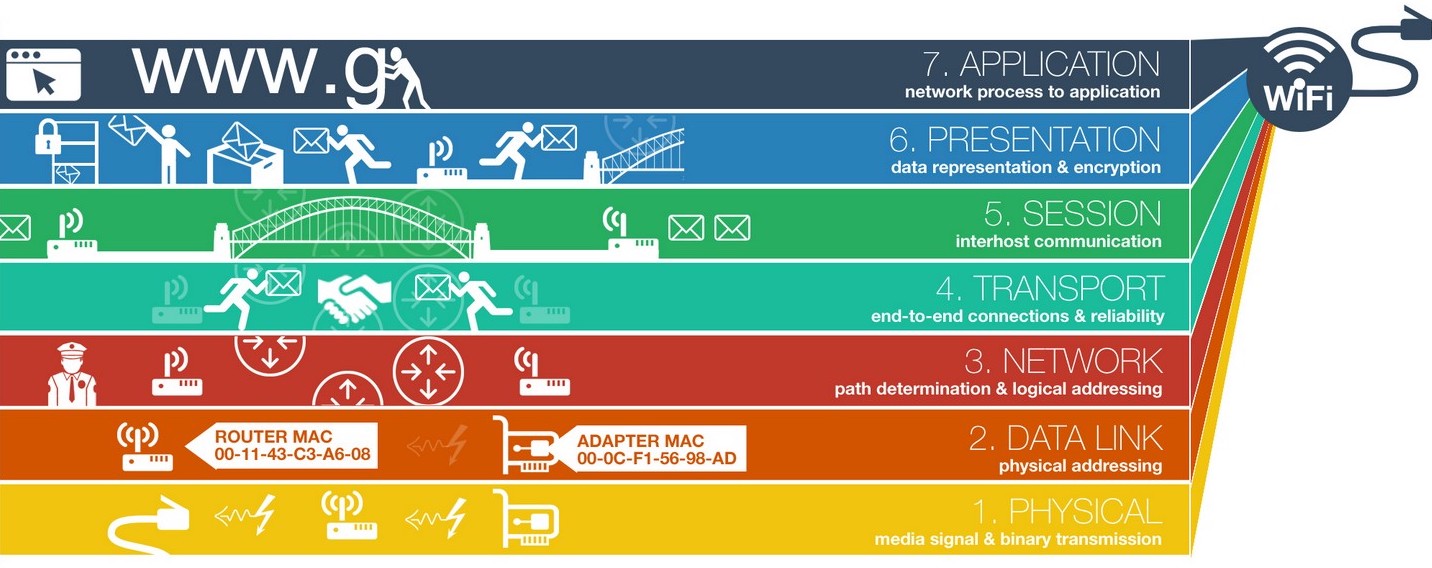
在这种分层结构下,每一层抽象都只依赖比它抽象级别更低的层,同时对比它抽象级别更高的层一无所知。因此,每层都可以脱离更高级别的层独立工作,假如一个函数内同时包含了多个抽象级别的内容,就会引发一系列的问题。
如果你想在 Python 中实践函数式编程,最常用的几个工具如下所示:
- map(func, iterable):遍历并执行 func 获取结果,迭代返回新结果;
- filter(func, iterable):遍历并使用 func 测试成员,仅当结果为真时返回;
- lambda:定义一个一次性使用的匿名函数;
在大多数情况下,相比函数式编程,使用列表推导式的代码通常更短,而且描述性更强:
1 | points = list(map(query_points, filter(lambda user: user.is_active(), users))) |
1 | points = [query_points(user) for user in users if user.is_active()] |
Python 中的匿名函数只是一颗简单的语法糖,lambda 最常见的用途就是作为 sorted() 函数的排序参数使用。它的许多使用场景,要么本身就不存在,要么更适合用 operator 模块来满足,没有什么特殊功能是 lambda 能做而普通函数做不到的。
在编程语言领域,为了避免递归调用栈过深,占用过多资源,不少编程语言使用一种被称为尾调用优化(Tail Call Optimization)的技术。Python 没有这种技术,只要用 @lru_cache 添加缓存,就可以极大地提升性能;但如果输入数字过大,函数执行时还是会超过最大递归深度限制,对于任何递归代码来说,一劳永逸的办法是将其改写成循环:
1 | from functools import lru_cache |
1 | def fib(n): |
虽然函数可以消除重复代码,但绝不能只把它看成一种复用代码的工具,函数最重要的价值其实是创建抽象,而提供复用价值甚至可以算成抽象所带来的一种副作用。
装饰器
在日常工作中,如果你掌握了如何编写装饰器,并在恰当的时机使用装饰器,就可以写出更易复用、更好扩展的代码。假如没有装饰器,我们也可以在完成函数定义后,手动做一次包装和重新赋值:
1 |
|
1 | function = cache(function) |
装饰器基础
装饰器(Decorator)是一种通过包装目标函数修改其行为的特殊高阶函数,绝大多数装饰器是利用函数的闭包原理实现的:
1 | def timer(func): |
在写装饰器时,我们一般把 decorated 叫包装函数,这些包装函数通常接收任意数目的可变参数 (*args, **kwargs),主要通过调用原始函数 func 来完成工作,在包装函数内部,常会增加一些额外步骤,比如打印信息、修改参数等。假如你想实现一个接收参数的装饰器,代码会更复杂一些:
1 | def timer(print_args=False): |
在应用有参数装饰器时,一共要做两次函数调用,所以装饰器总共得包含三层嵌套函数:
1 |
|
1 | decorated = timer(print_args=True) |
使用 functools.warps() 修饰包装函数
在编写装饰器时,切记使用 @functools.wraps() 来修饰包装函数:
- 首先会基于原函数 func 来更新包装函数 decorated 的名称、文档等内置属性;
- 之后会将 func 的所有额外属性赋值到 decorated 上;
1 | from functools import wraps |
实现可选参数装饰器
把参数变为可选能有效降低使用者的心智负担,让装饰器变得更易用,利用仅限关键字参数,可以很方便地做到这一点:
1 | def delayed_start(func=None, *, duration=1): |
用类来实现装饰器
事实上,某个对象是否能通过装饰器(@decorator)的形式使用只有一条判断标准,那就是 decorator 是不是一个可调用的对象。使用 callable() 内置函数可以判断某个对象是否可调用,__call__ 魔法方法是用来实现可调用对象的关键方法。
函数替换
函数替换装饰器虽然是基于类实现的,但用来替换原函数的对象,仍然是一个处在 __call__ 方法里的闭包函数 decorated。这种技术最适合用来实现接收参数的装饰器:
1 | class timer: |
通过类实现的装饰器,其实就是把原本的两次函数调用替换成了类和实例的调用,相比三层嵌套的闭包函数装饰器,代码更清晰一些:
- 第一次调用:decorated = timer(print_args=True) 实际上是在初始化一个 timer 实例;
- 第二次调用:func = decorated(func) 是在调用 timer 实例,触发 __call__ 方法;
实例替换
实例替换装饰器的主要优势在于,你可以更方便地管理装饰器的内部状态,同时也可以更自然地为被装饰对象追加额外的方法和属性。
实现无参数装饰器
被装饰的函数 func 会作为唯一的初始化参数传递到类的实例化方法 __init__ 中,同时,类的实例化结果会作为包装对象替换原始函数:
1 | from functools import update_wrapper |
实现有参数装饰器
我们需要先修改类的实例化方法,增加额外的参数,再定义一个新函数,由它负责基于类创建新的可调用对象,这个新函数同时也是会被实际使用的装饰器:
1 | from functools import update_wrapper, partial |
使用 wrapt 模块助力装饰器编写
类方法(Method)和函数(Function)在工作机制上有细微的区别,当类实例方法被调用时,第一个位置参数总是当前绑定的类实例 self 对象。使用 wrapt 模块编写的装饰器,可以解决类方法的兼容问题,代码嵌套层级也比普通装饰器更少,变得更扁平、更易读:
1 | def provide_number(min_num, max_num): |
1 | import wrapt |
编程建议
装饰器的优势并不在于它提供了动态修改函数的能力,而在于它把影响函数的装饰行为移到了函数头部,降低了代码的阅读与理解成本。为了充分发挥这个优势,装饰器特别适合用来实现以下功能:
- 运行时校验:在执行阶段进行特定校验,当校验不通过时终止执行:
- 适合原因:装饰器可以方便地在函数执行前介入,并且可以读取所有参数辅助校验;
- 代表样例:Django 框架中的用户登陆态校验装饰器 @login_required;
- 注入额外参数:在函数被调用时自动注入额外的调用参数:
- 适合原因:装饰器的位置在函数头部,非常靠近参数被定义的位置,关联性强;
- 代表样例:unittest.mock 模块的装饰器 @patch;
- 缓存执行结果:通过调用参数等输入信息,直接缓存函数执行结果:
- 适合原因:添加缓存不需要侵入函数内部逻辑,并且功能非常独立和通用;
- 代表样例:functools 模块的缓存装饰器 @lru_cache;
- 注册函数:将被装饰函数注册为某个外部流程的一部分:
- 适合原因:在定义函数时可以完成注册,关联性强;
- 代表样例:Flask 框架的路由注册装饰器 @app.route;
- 替换为复杂对象:将原函数(方法)替换为更复杂的对象,比如类实例或特殊的描述符对象:
- 适合原因:在执行替换操作时,装饰器语法天然比重新赋值的写法要直观得多;
- 代表样例:静态类方法装饰器 @staticmethod;
归根结底,装饰器其实只是一类特殊的 API,一种提供服务的方式,比起把所有核心逻辑都放在装饰器内,不如让装饰器里只有一层浅浅的包装层,而把更多的实现细节放在其他函数或类中。发挥想象力,同时保持克制,也许这就是设计出人人喜爱的装饰器的秘诀。