基于单模式串和 Trie 树实现的敏感词过滤
单模式串匹配算法,是在一个模式串和一个主串之间进行匹配,也就是说,在一个主串中查找一个模式串。多模式串匹配算法,就是在多个模式串和一个主串之间做匹配,也就是说,在一个主串中查找多个模式串。尽管,单模式串匹配算法也能完成多模式串的匹配工作。但是,这样做的话,每个匹配过程都需要扫描一遍用户输入的内容,整个过程下来就要扫描很多遍用户输入的内容。如果敏感词很多,比如几千个,并且用户输入的内容很长,假如有上千个字符,那我们就需要扫描几千遍这样的输入内容。很显然,这种处理思路比较低效。
与单模式匹配算法相比,多模式匹配算法在这个问题的处理上就很高效了。它只需要扫描一遍主串,就能在主串中一次性查找多个模式串是否存在,从而大大提高匹配效率。我们可以对敏感词字典进行预处理,构建成 Trie 树结构。这个预处理的操作只需要做一次,如果敏感词字典动态更新了,比如删除、添加了一个敏感词,那我们只需要动态更新一下 Trie 树就可以了。
当用户输入一个文本内容后,我们把用户输入的内容作为主串,从第一个字符(假设是字符 C)开始,在 Trie 树中匹配。当匹配到 Trie 树的叶子节点,或者中途遇到不匹配字符的时候,我们将主串的开始匹配位置后移一位,也就是从字符 C 的下一个字符开始,重新在 Trie 树中匹配。基于 Trie 树的这种处理方法,有点类似单模式串匹配的 BF 算法。
经典的多模式串匹配算法:AC 自动机
AC 自动机算法,全称是 Aho-Corasick 算法。其实,Trie 树跟 AC 自动机之间的关系,就像单串匹配中朴素的串匹配算法,跟 KMP 算法之间的关系一样,只不过前者针对的是多模式串而已。所以,AC 自动机实际上就是在 Trie 树之上,加了类似 KMP 的 next 数组,只不过此处的 next 数组是构建在树上罢了:
1 | public class AcNode |
所以,AC 自动机的构建,包含两个操作:
- 将多个模式串构建成 Trie 树;
- 在 Trie 树上构建失败指针(相当于 KMP 中的失效函数 next 数组);
构建好 Trie 树之后,如何在它之上构建失败指针?这里有 4 个模式串,分别是 c, bc, bcd, abcd;主串是 abcd: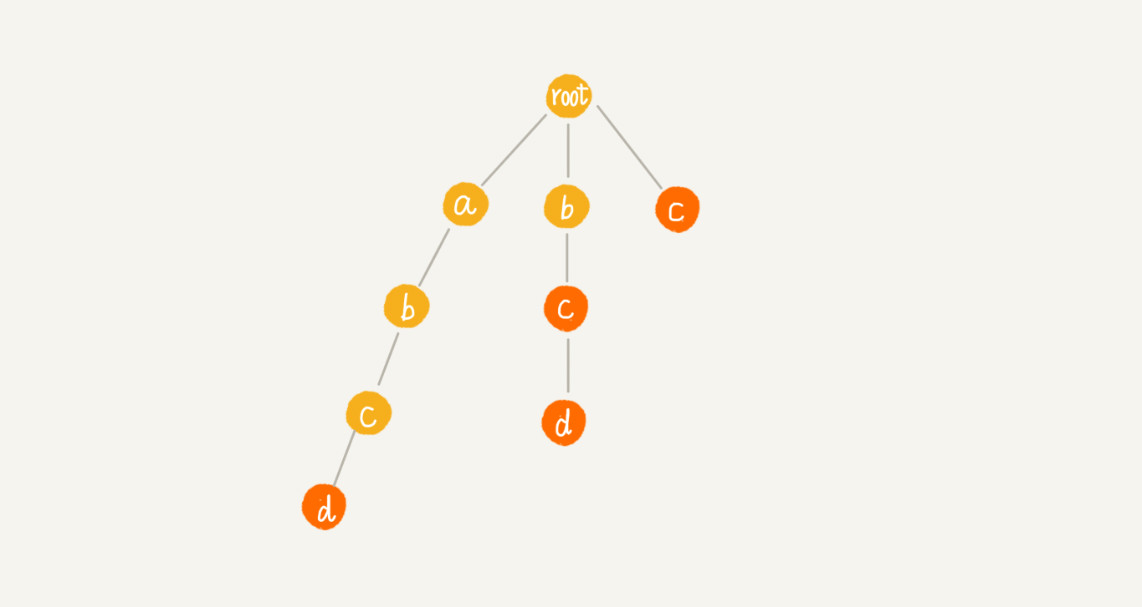
假设我们沿 Trie 树走到 p 节点,也就是下图中的紫色节点,那 p 的失败指针就是从 root 走到紫色节点形成的字符串 abc,跟所有模式串前缀匹配的最长可匹配后缀子串,就是箭头指的 bc 模式串。我们将 p 节点的失败指针指向那个最长匹配后缀子串对应的模式串的前缀的最后一个节点,就是下图中箭头指向的节点: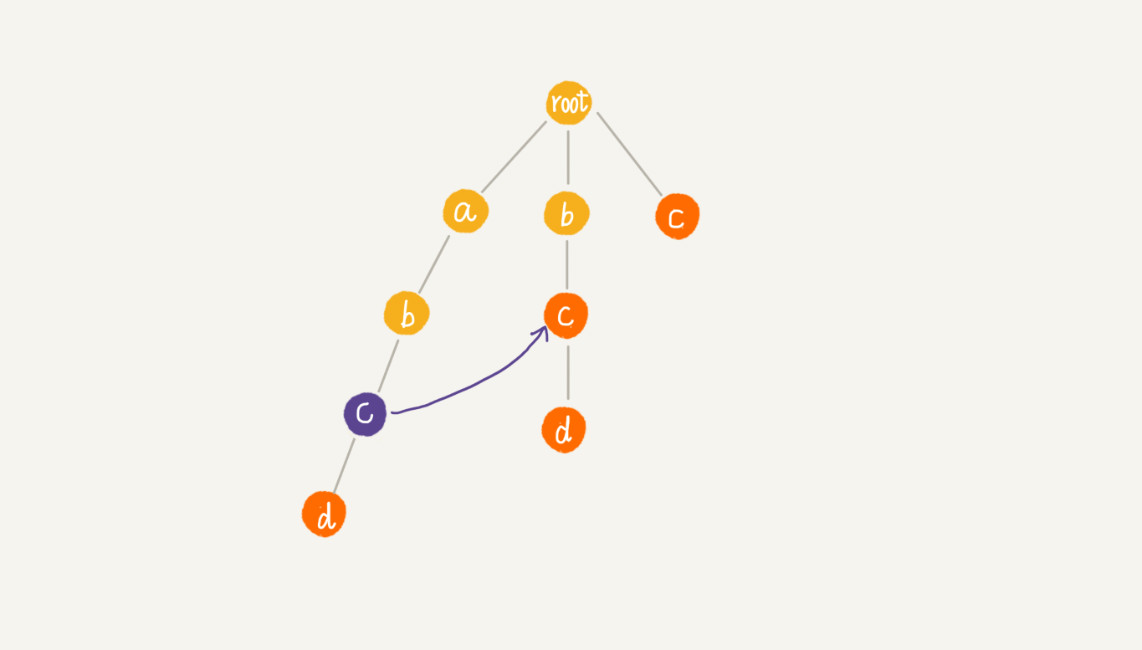
其实,如果我们把树中相同深度的节点放到同一层,那么某个节点的失败指针只有可能出现在它所在层的上一层。我们可以像 KMP 算法那样,当我们要求某个节点的失败指针的时候,我们通过已经求得的、深度更小的那些节点的失败指针来推导。也就是说,我们可以逐层依次来求解每个节点的失败指针。所以,失败指针的构建过程,是一个按层遍历树的过程。
我们假设节点 p 的失败指针指向节点 q,我们看节点 p 的子节点 pc 对应的字符,是否也可以在节点 q 的子节点中找到。如果找到了节点 q 的一个子节点 qc,对应的字符跟节点 pc 对应的字符相同,则将节点 pc 的失败指针指向节点 qc: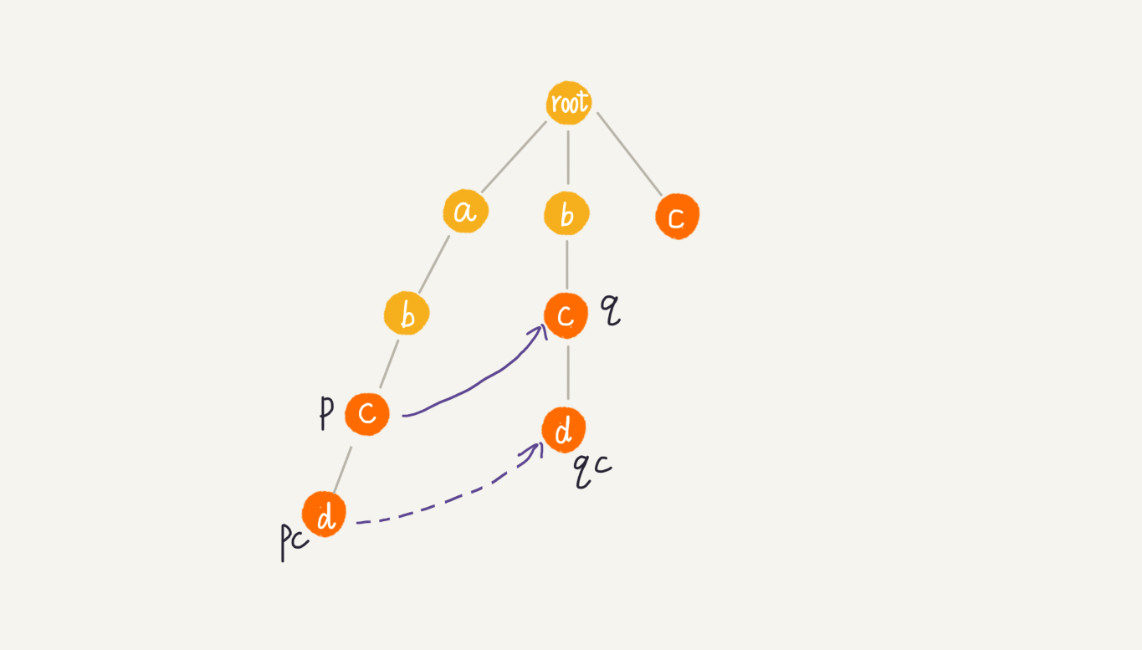
如果节点 q 中没有子节点的字符等于节点 pc 包含的字符,则令 q=q->fail,继续上面的查找,直到 q 是 root 为止,如果还没有找到相同字符的子节点,就让节点 pc 的失败指针指向 root: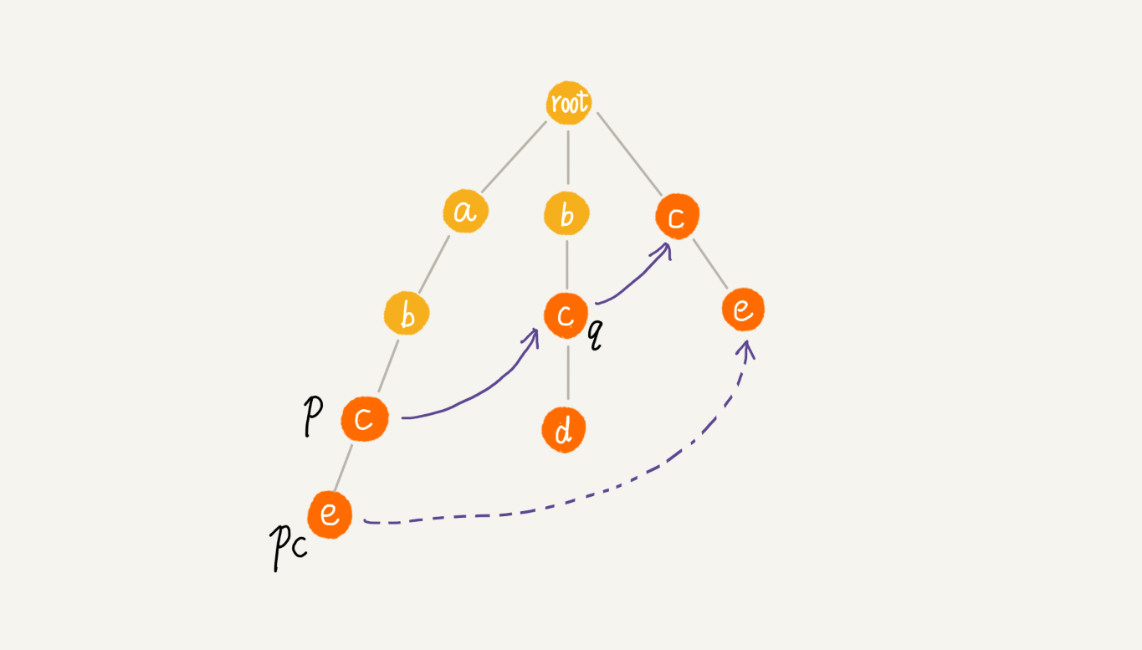
我将构建失败指针的代码贴在这里,你可以对照着讲解一块看下,应该更容易理解:
1 | public void buildFailurePointer() |
通过按层来计算每个节点的子节点的失效指针,刚刚举的那个例子,最后构建完成之后的 AC 自动机就是下面这个样子: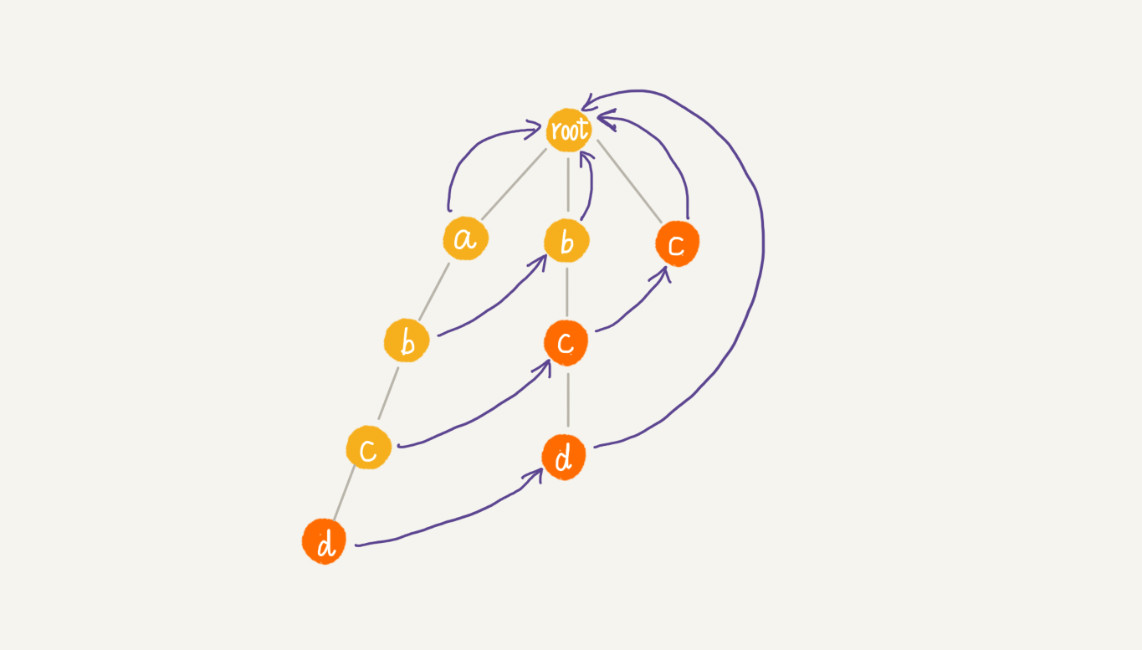
在匹配过程中,主串从 i=0 开始,AC 自动机从指针 p=root 开始,假设模式串是 b,主串是 a:
- 如果 p 指向的节点有一个等于 b[i]的子节点 x,我们就更新 p 指向 x,这个时候我们需要通过失败指针,检测一系列失败指针为结尾的路径是否是模式串。这一句不好理解,你可以结合代码看。处理完之后 i+1,继续这两个过程;
- 如果 p 指向的节点没有等于 b[i]的子节点,那失败指针就派上用场了,我们让 p=p->fail,然后继续这两个过程;
关于匹配的这部分,文字描述不如代码看得清楚,所以我把代码贴了出来,非常简短。这段代码输出的就是,在主串中每个可以匹配的模式串出现的位置:
1 | public void match(char[] text) |
如何实现高性能的敏感词过滤功能
实际上,我上面贴出来的代码,已经是一个敏感词过滤的原型代码了。它可以找到所有敏感词出现的位置(在用户输入的文本中的起始下标)。你只需要稍加改造,再遍历一遍文本内容(主串),就可以将文本中的所有敏感词替换成“***”。
AC 自动机实现的敏感词过滤系统,是否比单模式串匹配方法更高效:
- 将多个模式串构建成 AC 自动机:
AC 自动机的构建过程都是预先处理好的,构建好之后,并不会频繁地更新,所以不会影响到敏感词过滤的运行效率。- 将模式串构建成 Trie 树:
- 在 Trie 树上构建失败指针:
假设 Trie 树中总的节点个数是 k,每个节点构建失败指针的时候,最耗时的环节是 while 循环中的 q=q->fail,每运行一次这个语句,q 指向节点的深度都会减少 1,而树的高度最高也不会超过 len,所以每个节点构建失败指针的时间复杂度是 O(len)。整个失败指针的构建过程就是 O(k*len);
- 在 AC 自动机中匹配主串:
跟刚刚构建失败指针的分析类似,for 循环依次遍历主串中的每个字符,for 循环内部最耗时的部分也是 while 循环,而这一部分的时间复杂度也是 O(len),所以总的匹配的时间复杂度就是 O(n*len)。因为敏感词并不会很长,而且这个时间复杂度只是一个非常宽泛的上限,实际情况下,可能近似于 O(n),所以 AC 自动机做敏感词过滤,性能非常高;
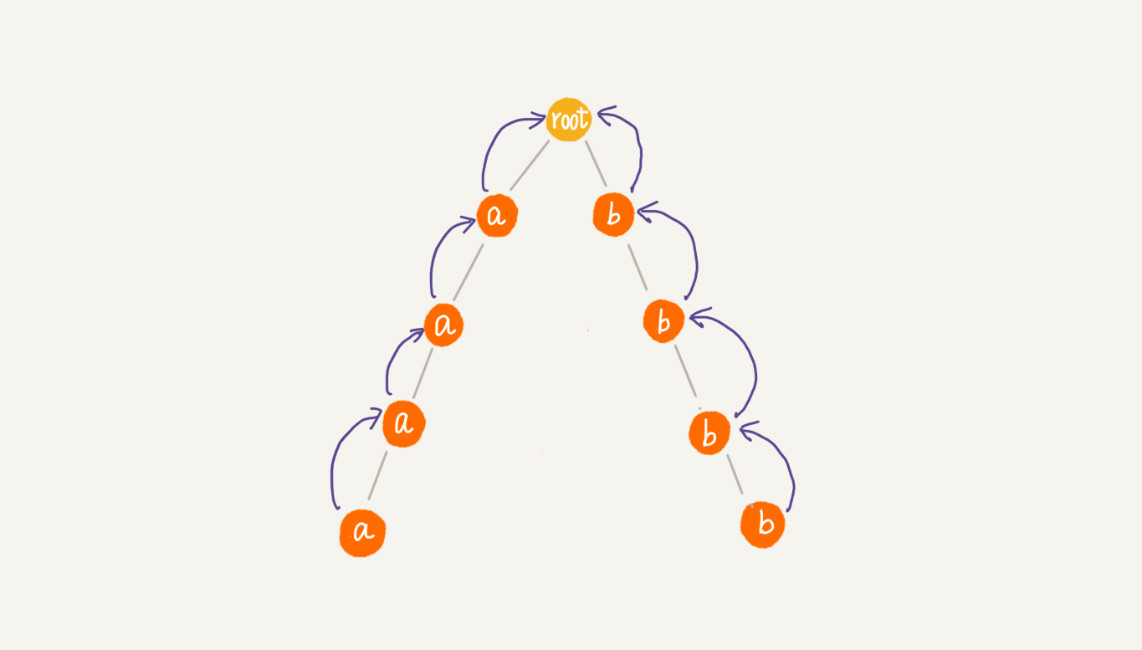
实际上,因为失效指针可能大部分情况下都指向 root 节点,所以绝大部分情况下,在 AC 自动机上做匹配的效率要远高于刚刚计算出的比较宽泛的时间复杂度。只有在极端情况下,如图所示,AC 自动机的性能才会退化的跟 Trie 树一样: