其实,只要讲到数据结构与算法,就一定离不开时间、空间复杂度分析。而且,我个人认为,复杂度分析是整个算法学习的精髓,只要掌握了它,数据结构和算法的内容基本上就掌握了一半。
为什么需要复杂度分析?
首先,我可以肯定地说,你这种评估算法执行效率的方法是正确的。很多数据结构和算法书籍还给这种方法起了一个名字,叫事后统计法。但是,这种统计方法有非常大的局限性。
测试结果非常依赖测试环境
测试环境中硬件的不同会对测试结果有很大的影响。比如,我们拿同样一段代码,分别用 Intel Core i9 处理器和 Intel Core i3 处理器来运行,不用说,i9 处理器要比 i3 处理器执行的速度快很多。还有,比如原本在这台机器上 a 代码执行的速度比 b 代码要快,等我们换到另一台机器上时,可能会有截然相反的结果。
测试结果受数据规模的影响很大
后面我们会讲排序算法,我们先拿它举个例子。对同一个排序算法,待排序数据的有序度不一样,排序的执行时间就会有很大的差别。极端情况下,如果数据已经是有序的,那排序算法不需要做任何操作,执行时间就会非常短。除此之外,如果测试数据规模太小,测试结果可能无法真实地反映算法的性能。比如,对于小规模的数据排序,插入排序可能反倒会比快速排序要快!
我们需要一个不用具体的测试数据来测试,就可以粗略地估计算法的执行效率的方法。
大 O 复杂度表示法
这里有段非常简单的代码,求 1, 2, 3, …, n 的累加和。现在,我就带你一块来估算一下这段代码的执行时间:
1 | int calc(int n) { |
从 CPU 的角度来看,这段代码的每一行都执行着类似的操作:读数据 -> 运算 -> 写数据。尽管每行代码对应的 CPU 执行的个数、执行的时间都不一样,但是,我们这里只是粗略估计,所以可以假设每行代码执行的时间都一样,为 unit_time。在这个假设的基础之上,这段代码的总执行时间是多少呢?
第 2、3 行代码分别需要 1 个 unit_time 的执行时间,第 4、5 行都运行了 n 遍,所以需要 2n*unit_time 的执行时间,所以这段代码总的执行时间就是 (2n+2)*unit_time。可以看出来,所有代码的执行时间 T(n) 与每行代码的执行次数成正比。
按照这个分析思路,我们再来看这段代码:
1 | int calc(int n) { |
第 2、3、4 行代码,每行都需要 1 个 unit_time 的执行时间,第 5、6 行代码循环执行了 n 遍,需要 2n*unit_time 的执行时间,第 7、8 行代码循环执行了 n^2 遍,所以需要 2n^2*unit_time 的执行时间。所以,整段代码总的执行时间 T(n) = (2n^2+2n+3)*unit_time。
我们可以把这个规律总结成一个公式: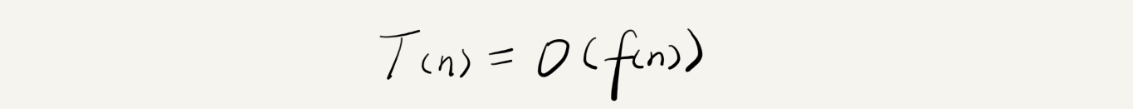
我来具体解释一下这个公式。其中,T(n) 我们已经讲过了,它表示代码执行的时间;f(n) 表示每行代码执行的次数总和。公式中的 O,表示代码的执行时间 T(n) 与 f(n) 表达式成正比。
大 O 时间复杂度实际上并不具体表示代码真正的执行时间,而是表示代码执行时间随数据规模增长的变化趋势,所以,也叫作渐进时间复杂度(Asymptotic Time Complexity),简称时间复杂度。
我们只需要记录一个最大量级就可以了,如果用大 O 表示法表示刚讲的那两段代码的时间复杂度,就可以记为:T(n) = O(n);T(n) = O(n^2)。
时间复杂度分析
三个比较实用的方法:
- 只关注循环执行次数最多的一段代码:
大 O 这种复杂度表示方法只是表示一种变化趋势。我们通常会忽略掉公式中的常量、低阶、系数,只需要记录一个最大阶的量级就可以了。所以,我们在分析一个算法、一段代码的时间复杂度的时候,也只关注循环执行次数最多的那一段代码就可以了; - 加法法则:总复杂度等于量级最大的那段代码的复杂度
我们将这个规律抽象成公式就是:如果 T1(n)=O(f(n)),T2(n)=O(g(n));那么 T(n)=T1(n)+T2(n)=max(O(f(n)), O(g(n))) =O(max(f(n), g(n))); - 乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积:
假设 T1(n)=O(n),T2(n)=O(n^2),则 T1(n)*T2(n) = O(n^3);
几种常见时间复杂度实例分析
虽然代码千差万别,但是常见的复杂度量级并不多:
对于刚罗列的复杂度量级,我们可以粗略地分为两类,多项式量级和非多项式量级。其中,非多项式量级只有两个:O(2^n) 和 O(n!)。我们把时间复杂度为非多项式量级的算法问题叫作 NP(Non-Deterministic Polynomial,非确定多项式)问题。当数据规模 n 越来越大时,非多项式量级算法的执行时间会急剧增加,求解问题的执行时间会无限增长。
O(1)
只要代码的执行时间不随 n 的增大而增长,这样代码的时间复杂度我们都记作 O(1)。或者说,一般情况下,只要算法中不存在循环语句、递归语句,即使有成千上万行的代码,其时间复杂度也是Ο(1)。
O(logn)、O(nlogn)
对数阶时间复杂度非常常见,同时也是最难分析的一种时间复杂度。如果一段代码的时间复杂度是 O(logn),我们循环执行 n 遍,时间复杂度就是 O(nlogn) 了。而且,O(nlogn) 也是一种非常常见的算法时间复杂度。比如,归并排序、快速排序的时间复杂度都是 O(nlogn)。
O(m+n)、O(m*n)
我们再来讲一种跟前面都不一样的时间复杂度,代码的复杂度由两个数据的规模来决定。我们无法事先评估 m 和 n 谁的量级大,所以我们在表示复杂度的时候,就不能简单地利用加法法则,省略掉其中一个。所以,上面代码的时间复杂度就是 O(m+n)。
空间复杂度分析
类比时间复杂度,空间复杂度全称就是渐进空间复杂度(Asymptotic Space Complexity),表示算法的存储空间与数据规模之间的增长关系。我们常见的空间复杂度就是 O(1)、O(n)、O(n^2)。
最好、最坏情况时间复杂度
你可以用我上节教你的分析技巧,自己先试着分析一下这段代码的时间复杂度:
1 | // n 表示数组 array 的长度 |
如果数组中第一个元素正好是要查找的变量 x,那就不需要继续遍历剩下的 n-1 个数据了,那时间复杂度就是 O(1)。但如果数组中不存在变量 x,那我们就需要把整个数组都遍历一遍,时间复杂度就成了 O(n)。所以,不同的情况下,这段代码的时间复杂度是不一样的。
顾名思义,最好情况时间复杂度就是,在最理想的情况下,执行这段代码的时间复杂度。就像我们刚刚讲到的,在最理想的情况下,要查找的变量 x 正好是数组的第一个元素,这个时候对应的时间复杂度就是最好情况时间复杂度。
同理,最坏情况时间复杂度就是,在最糟糕的情况下,执行这段代码的时间复杂度。就像刚举的那个例子,如果数组中没有要查找的变量 x,我们需要把整个数组都遍历一遍才行,所以这种最糟糕情况下对应的时间复杂度就是最坏情况时间复杂度。
平均时间复杂度
我们知道,要查找的变量 x,要么在数组里,要么就不在数组里。这两种情况对应的概率统计起来很麻烦,为了方便你理解,我们假设在数组中与不在数组中的概率都为 1/2。另外,要查找的数据出现在 0~n-1 这 n 个位置的概率也是一样的,为 1/n。
如果我们把每种情况发生的概率也考虑进去,那平均时间复杂度的计算过程就变成了这样: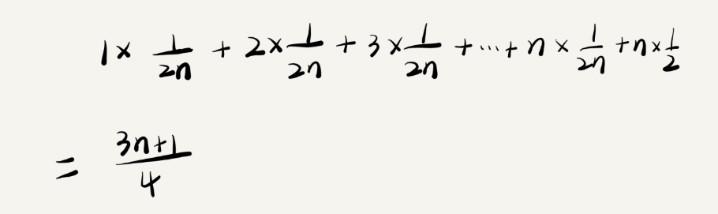
引入概率之后,前面那段代码的加权平均值为 (3n+1)/4。用大 O 表示法来表示,去掉系数和常量,这段代码的加权平均时间复杂度仍然是 O(n)。
实际上,在大多数情况下,我们并不需要区分最好、最坏、平均时间复杂度三种情况。只有同一块代码在不同的情况下,时间复杂度有量级的差距,我们才会使用这三种复杂度表示法来区分。
均摊时间复杂度
老规矩,我还是借助一个具体的例子来帮助你理解:
1 | // array 表示一个长度为n的数组 |
我先来解释一下这段代码。这段代码实现了一个往数组中插入数据的功能。当数组满了之后,也就是代码中的 count == array.length 时,我们用 for 循环遍历数组求和,并清空数组,将求和之后的 sum 值放到数组的第一个位置,然后再将新的数据插入。但如果数组一开始就有空闲空间,则直接将数据插入数组。
假设数组的长度是 n,根据数据插入的位置的不同,我们可以分为 n 种情况,每种情况的时间复杂度是 O(1)。除此之外,还有一种“额外”的情况,就是在数组没有空闲空间时插入一个数据,这个时候的时间复杂度是 O(n)。而且,这 n+1 种情况发生的概率一样,都是 1/(n+1)。所以,根据加权平均的计算方法,我们求得的平均时间复杂度就是: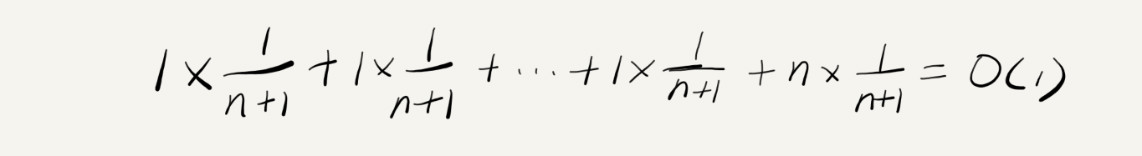
针对这种特殊的场景,我们引入了一种更加简单的分析方法:摊还分析法,通过摊还分析得到的时间复杂度我们起了一个名字,叫均摊时间复杂度。
对一个数据结构进行一组连续操作中,大部分情况下时间复杂度都很低,只有个别情况下时间复杂度比较高,而且这些操作之间存在前后连贯的时序关系,这个时候,我们就可以将这一组操作放在一块儿分析,看是否能将较高时间复杂度那次操作的耗时,平摊到其他那些时间复杂度比较低的操作上。而且,在能够应用均摊时间复杂度分析的场合,一般均摊时间复杂度就等于最好情况时间复杂度。
均摊时间复杂度就是一种特殊的平均时间复杂度