二分查找(Binary Search)算法,也叫折半查找算法。二分查找的思想非常简单,很多非计算机专业的同学很容易就能理解,但是看似越简单的东西往往越难掌握好,想要灵活应用就更加困难。
无处不在的二分思想
我们现在来做一个猜字游戏:我随机写一个 0 到 99 之间的数字,然后你来猜我写的是什么。猜的过程中,你每猜一次,我就会告诉你猜的大了还是小了,直到猜中为止。假设我写的数字是 23,你可以按照下面的步骤来试一试: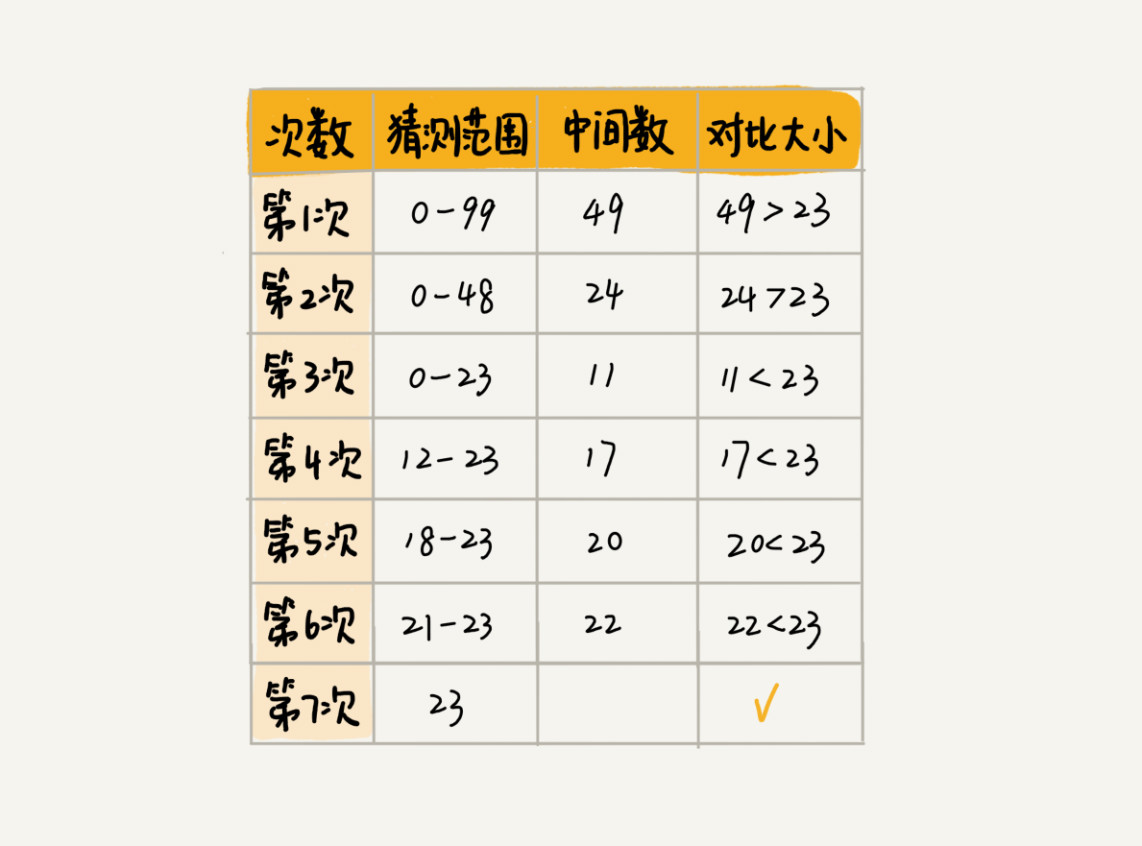
假设有 1000 条订单数据,已经按照订单金额从小到大排序,每个订单金额都不同,并且最小单位是元。我们现在想知道是否存在金额等于 19 元的订单。如果存在,则返回订单数据,如果不存在则返回 null。为了方便讲解,我们假设只有 10 个订单,订单金额分别是:8, 11, 19, 23, 27, 33, 45, 55, 67, 98。还是利用二分思想,每次都与区间的中间数据比对大小,缩小查找区间的范围。为了更加直观,我画了一张查找过程的图。其中,low 和 high 表示待查找区间的下标,mid 表示待查找区间的中间元素下标: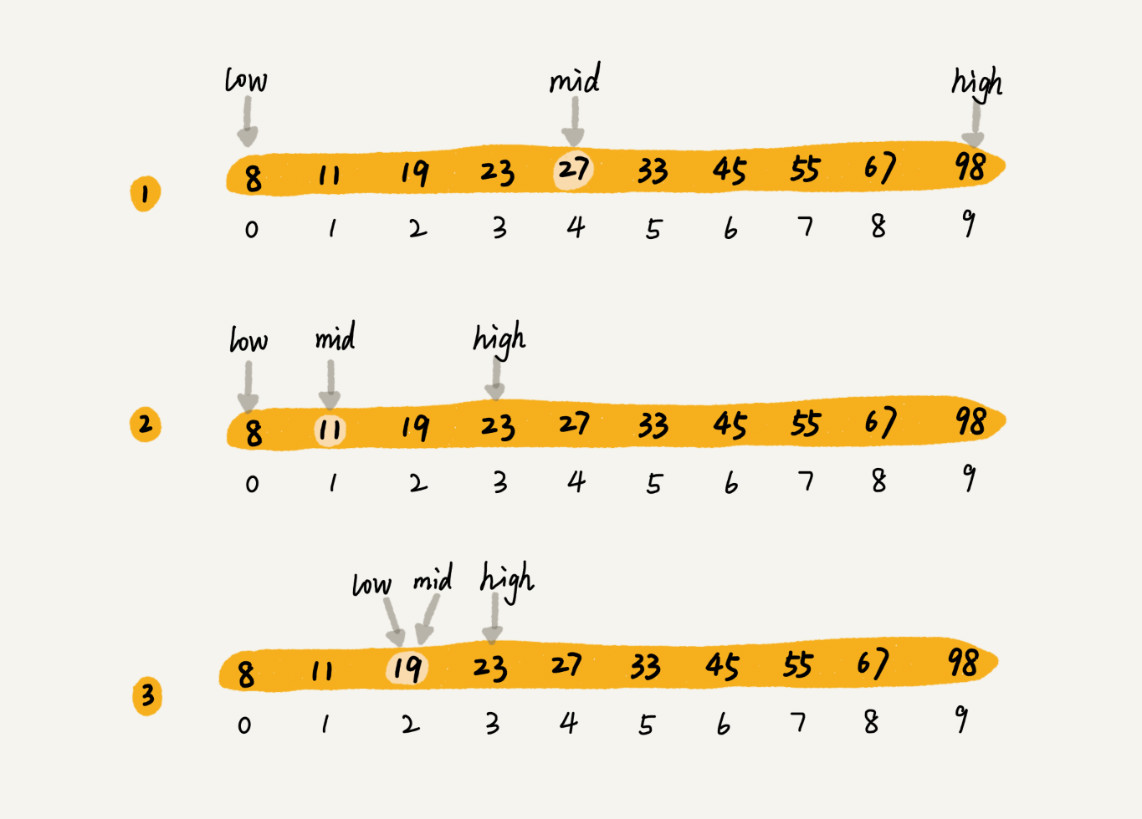
二分查找针对的是一个有序的数据集合,查找思想有点类似分治思想。每次都通过跟区间的中间元素对比,将待查找的区间缩小为之前的一半,直到找到要查找的元素,或者区间被缩小为 0。
O(logn) 惊人的查找速度
我们假设数据大小是 n,每次查找后数据都会缩小为原来的一半,也就是会除以 2。最坏情况下,直到查找区间被缩小为空,才停止:
可以看出来,这是一个等比数列。其中 n/2^k=1 时,k 的值就是总共缩小的次数。而每一次缩小操作只涉及两个数据的大小比较,所以,经过了 k 次区间缩小操作,时间复杂度就是 O(k)。通过 n/2^k=1,我们可以求得 k=log2n,所以时间复杂度就是 O(logn)。
logn 是一个非常恐怖的数量级,即便 n 非常非常大,对应的 logn 也很小。比如 n 等于 2 的 32 次方,这个数很大了吧?大约是 42 亿。也就是说,如果我们在 42 亿个数据中用二分查找一个数据,最多需要比较 32 次。我们前面讲过,用大 O 标记法表示时间复杂度的时候,会省略掉常数、系数和低阶。对于常量级时间复杂度的算法来说,O(1) 有可能表示的是一个非常大的常量值,比如 O(1000)、O(10000)。所以,常量级时间复杂度的算法有时候可能还没有 O(logn) 的算法执行效率高。
指数时间复杂度的算法在大规模数据面前是无效的
二分查找的递归与非递归实现
最简单的情况就是有序数组中不存在重复元素,我们在其中用二分查找值等于给定值的数据:
1 | public int bsearch(int[] a, int n, int value) { |
这个代码我稍微解释一下,low、high、mid 都是指数组下标,其中 low 和 high 表示当前查找的区间范围,初始 low=0, high=n-1。mid 表示 [low, high] 的中间位置。我们通过对比 a[mid] 与 value 的大小,来更新接下来要查找的区间范围,直到找到或者区间缩小为 0,就退出。
现在,我就着重强调一下容易出错的 3 个地方:
- 循环退出条件:
注意是 low<=high,而不是 low<high; - mid 的取值:
实际上,mid=(low+high)/2 这种写法是有问题的。因为如果 low 和 high 比较大的话,两者之和就有可能会溢出。改进的方法是将 mid 的计算方式写成 low+(high-low)/2。更进一步,如果要将性能优化到极致的话,我们可以将这里的除以 2 操作转化成位运算 low+((high-low)>>1)。因为相比除法运算来说,计算机处理位运算要快得多; - low 和 high 的更新:
low=mid+1,high=mid-1。注意这里的 +1 和 -1,如果直接写成 low=mid 或者 high=mid,就可能会发生死循环。比如,当 high=3,low=3 时,如果 a[3]不等于 value,就会导致一直循环不退出;
实际上,二分查找除了用循环来实现,还可以用递归来实现,过程也非常简单:
1 | // 二分查找的递归实现 |
二分查找应用场景的局限性
前面我们分析过,二分查找的时间复杂度是 O(logn),查找数据的效率非常高。不过,并不是什么情况下都可以用二分查找,它的应用场景是有很大局限性的:
- 二分查找依赖的是顺序表结构,简单点说就是数组:
数组按照下标随机访问数据的时间复杂度是 O(1),而链表随机访问的时间复杂度是 O(n)。所以,如果数据使用链表存储,二分查找的时间复杂就会变得很高。二分查找只能用在数据是通过顺序表来存储的数据结构上。如果你的数据是通过其他数据结构存储的,则无法应用二分查找; - 二分查找针对的是有序数据:
如果数据没有序,我们需要先排序。前面章节里我们讲到,排序的时间复杂度最低是 O(nlogn)。所以,如果我们针对的是一组静态的数据,没有频繁地插入、删除,我们可以进行一次排序,多次二分查找。这样排序的成本可被均摊,二分查找的边际成本就会比较低。所以,二分查找只能用在插入、删除操作不频繁,一次排序多次查找的场景中。针对动态变化的数据集合,二分查找将不再适用; - 数据量太小不适合二分查找:
如果要处理的数据量很小,完全没有必要用二分查找,顺序遍历就足够了。比如我们在一个大小为 10 的数组中查找一个元素,不管用二分查找还是顺序遍历,查找速度都差不多。只有数据量比较大的时候,二分查找的优势才会比较明显; - 数据量太大也不适合二分查找:
二分查找的底层需要依赖数组这种数据结构,而数组为了支持随机访问的特性,要求内存空间连续,对内存的要求比较苛刻。比如,我们有 1GB 大小的数据,如果希望用数组来存储,那就需要 1GB 的连续内存空间。所以,太大的数据用数组存储就比较吃力了,也就不能用二分查找了;
如何在 1000 万个整数中快速查找某个整数
这个问题并不难。我们的内存限制是 100MB,每个数据大小是 8 字节,最简单的办法就是将数据存储在数组中,内存占用差不多是 80MB,符合内存的限制。我们可以先对这 1000 万数据从小到大排序,然后再利用二分查找算法,就可以快速地查找想要的数据了。
虽然大部分情况下,用二分查找可以解决的问题,用散列表、二叉树都可以解决。但是,不管是散列表还是二叉树,都会需要比较多的额外的内存空间。如果用散列表或者二叉树来存储这 1000 万的数据,用 100MB 的内存肯定是存不下的。而二分查找底层依赖的是数组,除了数据本身之外,不需要额外存储其他信息,是最省内存空间的存储方式,所以刚好能在限定的内存大小下解决这个问题。
变体一:查找第一个值等于给定值的元素
我们将问题稍微修改下,有序数据集合中存在重复的数据,我们希望找到第一个值等于给定值的数据。比如下面这样一个有序数组,其中,a[5],a[6],a[7] 的值都等于 8,是重复的数据。我们希望查找第一个等于 8 的数据,也就是下标是 5 的元素: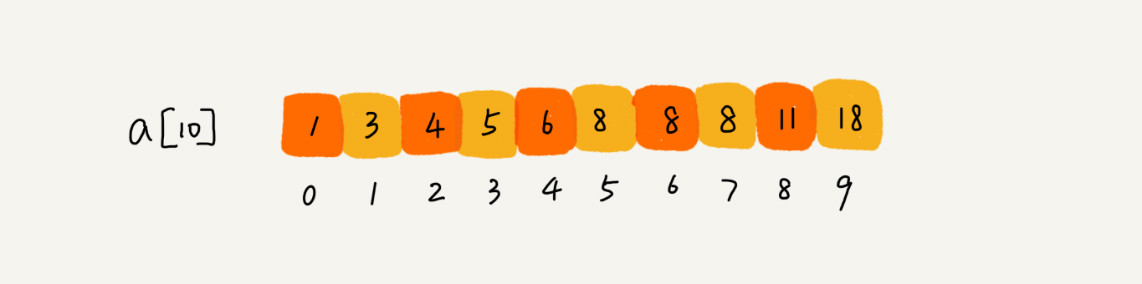
如果我们用上一节课讲的二分查找的代码实现,首先拿 8 与区间的中间值 a[4] 比较,8 比 6 大,于是在下标 5 到 9 之间继续查找。下标 5 和 9 的中间位置是下标 7,a[7] 正好等于 8,所以代码就返回了。尽管 a[7] 也等于 8,但它并不是我们想要找的第一个等于 8 的元素,因为第一个值等于 8 的元素是数组下标为 5 的元素。所以,我换了一种实现方法:
1 | public int bsearch(int[] a, int n, int value) { |
我们重点看第 13 行代码。如果 mid 等于 0,那这个元素已经是数组的第一个元素,那它肯定是我们要找的;如果 mid 不等于 0,但 a[mid] 的前一个元素 a[mid-1] 不等于 value,那也说明 a[mid] 就是我们要找的第一个值等于给定值的元素;如果经过检查之后发现 a[mid] 前面的一个元素 a[mid-1] 也等于 value,那说明此时的 a[mid] 肯定不是我们要查找的第一个值等于给定值的元素。那我们就更新 high=mid-1,因为要找的元素肯定出现在 [low, mid-1] 之间。
实际上,很多人都觉得变形的二分查找很难写,主要原因是太追求完美、简洁的写法。而对于我们做工程开发的人来说,代码易读懂、没 bug,其实更重要。
变体二:查找最后一个值等于给定值的元素
我现在把问题稍微改一下,查找最后一个值等于给定值的元素。如果你掌握了前面的写法,那这个问题你应该很轻松就能解决:
1 | public int bsearch(int[] a, int n, int value) { |
变体三:查找第一个大于等于给定值的元素
现在我们再来看另外一类变形问题。在有序数组中,查找第一个大于等于给定值的元素。比如,数组中存储的这样一个序列:3, 4, 6, 7, 10。如果查找第一个大于等于 5 的元素,那就是 6。实际上,实现的思路跟前面的那两种变形问题的实现思路类似:
1 | public int bsearch(int[] a, int n, int value) |
如果 a[mid] 小于要查找的值 value,那要查找的值肯定在 [mid+1, high] 之间,所以,我们更新 low=mid+1。对于 a[mid] 大于等于给定值 value 的情况,我们要先看下这个 a[mid] 是不是我们要找的第一个值大于等于给定值的元素。如果 a[mid] 前面已经没有元素,或者前面一个元素小于要查找的值 value,那 a[mid] 就是我们要找的元素;如果 a[mid-1] 也大于等于要查找的值 value,那说明要查找的元素在 [low, mid-1] 之间,所以,我们将 high 更新为 mid-1。
变体四:查找最后一个小于等于给定值的元素
现在,我们来看最后一种二分查找的变形问题,查找最后一个小于等于给定值的元素。比如,数组中存储了这样一组数据:3, 5, 6, 8, 9, 10。最后一个小于等于 7 的元素就是 6。实际上,实现思路也是一样的:
1 | public int bsearch7(int[] a, int n, int value) { |
如何快速定位出一个 IP 地址的归属地
当我们想要查询 202.102.133.13 这个 IP 地址的归属地时,我们就在地址库中搜索,发现这个 IP 地址落在 [202.102.133.0, 202.102.133.255] 这个地址范围内,那我们就可以将这个 IP 地址范围对应的归属地“山东东营市”显示给用户了:
1 | [202.102.133.0, 202.102.133.255] 山东东营市 |
现在这个问题应该很简单了。如果 IP 区间与归属地的对应关系不经常更新,我们可以先预处理这 12 万条数据,让其按照起始 IP 从小到大排序。如何来排序呢?我们知道,IP 地址可以转化为 32 位的整型数。所以,我们可以将起始地址,按照对应的整型值的大小关系,从小到大进行排序。
然后,这个问题就可以转化为我刚讲的第四种变形问题“在有序数组中,查找最后一个小于等于某个给定值的元素”了。当我们要查询某个 IP 归属地时,我们可以先通过二分查找,找到最后一个起始 IP 小于等于这个 IP 的 IP 区间,然后,检查这个 IP 是否在这个 IP 区间内,如果在,我们就取出对应的归属地显示;如果不在,就返回未查找到。