Kubernetes 是 Google 团队发起并维护的开源容器集群管理系统,底层基于 Docker、rkt 等容器技术,提供强大的应用管理和资源调度能力。
简介
Kubernetes 是 Google 公司于 2014 年开源的容器集群管理项目。该项目基于 Go 语言实现,遵守 Apache v2 许可,试图为基于容器的应用部署和生产管理打造一套强大并且易用的操作平台。
目前被云原生计算基金会(Cloud Native Computing Foundation,CNCF)管理,以开源项目形式持续演化。
Kubernetes 拥有鲜明的技术优势:
- 优秀的 API 设计,以及简洁高效的架构设计;
- 基于微服务模式的多层资源抽象模型,兼顾灵活性与可操作性;
- 可拓展性好,模块化容易替换,伸缩能力极佳;
- 自动化程度高,真正实现
所得即所用; - 部署支持多种环境,包括虚拟机、裸机部署,还很好支持常见云平台;
- 支持丰富的运维和配置工具,方便用户对集群进行性能测试、问题检查和状态监控;
- 自带控制台、客户端命令等工具。
核心概念
要想深入理解 Kubernetes 的特性和工作机制,首先要掌握 Kubernetes 模型中的核心概念。这些核心概念反映了 Kubernetes 设计过程中,对应用容器集群的认知模型。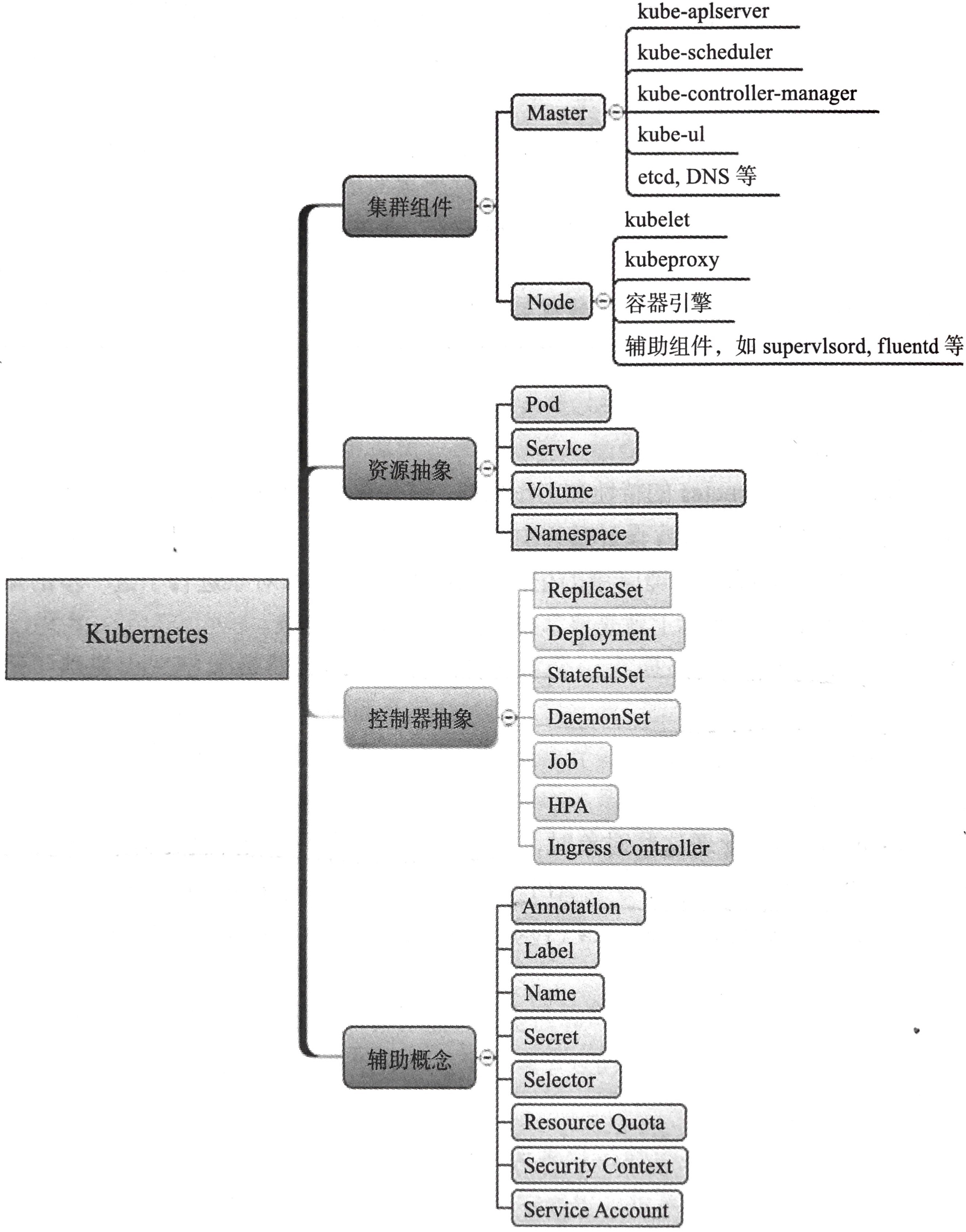
Kubernetes 中每种对象都拥有一个对应的声明式 API。对象包括三大属性:元数据(metadata)、规范(spec)和状态(status)。
每个对象可以使用一个外部的 JSON 或 YAML 模板文件来定义,通过参数传递给命令或 API。
基础的操作对象,主要是指资源抽象对象,包括:
- 容器组(Pod):Kubernetes 中最小的资源单位。由位于同一节点上的若干容器组成,彼此共享网络命名空间和存储卷。Pod 是短暂的,随时可变的,通常不带有状态;除了应用容器外,还包括一个初始的
Pause 容器,完成网络和存储空间的初始化; - 服务(Service):对外提供某个特定功能的一组 Pod 和所关联的访问配置。Kubernetes 通过服务提供唯一固定的访问地址,不随后面的 Pod 改变而变化;
- 存储卷(Volume):提供数据的持久化存储,并支持更高级的生命周期管理和参数指定功能,支持多种本地和云存储类型;
- 命名空间(Namespace):Kubernetes 通过命名空间来实现虚拟化,将同一组物理资源虚拟为不同的抽象集群,避免不同租户的资源发生命名冲突。
为了方便操作这些基础对象,Kubernetes 还引入了高级抽象概念——控制器(Controller)。这些控制器面向特定场景提供了自动管理 Pod 功能:
- 副本集(ReplicaSet):使用它可以让集群中始终维持某个 Pod 的指定副本数的健康实例。副本集中的 Pod 相互并无差异,可以彼此替换;
- 部署(Deployments):比副本集更高级的抽象,可以管理 Pod 或副本集,并且支持升级操作;
- 状态集(StatefulSets):管理带有状态的应用,可以为 Pod 分配独一无二的身份,确保在重新调配等操作时也不会相互替换;
- Daemon 集(DaemonSet):确保节点上肯定运行某个 Pod,一般用来采集日志(logstash)、监控节点(collectd)或提供存储(glusterd)使用;
- 任务(Job):适用于短期处理场景;
- 横向 Pod 扩展器(Horizontal Pod Autoscaler,HPA):根据 Pod 的使用率自动调整一个部署里面 Pod 的个数,保障服务可用性;
- 入口控制器(Ingress Controller):定义外部访问集群中资源的一组规则,用来提供七层代理和负载均衡服务。
此外,还有一些管理资源相关的辅助概念:
- 标签(Label):键值对,用来对资源进行分类和筛选;
- 选择器(Selector):正则表达式,可通过标签来筛选出一组资源;
- 注解(Annotation):键值对,用来添加对资源对象的详细说明,可供其他工具处理;
- 秘密数据(Secret):存放敏感数据;
- 名字(Name):用户提供给资源的别名;
- 服务账号(Service Accounts):操作资源的用户账号。
- 持久化存储(Persistent Volumes):确保数据不会丢失;
- 安全上下文(Security Context):应用到容器上的系统安全配置;
- 资源限额(Resource Quotas):用来限制某个命名空间下对资源的使用;
资源抽象对象
Kubernetes 对集群中的资源进行了不同级别的抽象,每个资源都是一个 REST 对象,通过 API 进行操作,通过 JSON 或 YAML 格式的模版文件进行定义。
在使用 k8s 的过程中,要注意积累这些模版文件。
容器组
Kubernetes 并不直接操作容器,最小的管理单位是容器组(Pod)。同一个容器组中,各个容器共享命名空间、cgroups 限制和存储卷。
可以简单地将一个 Pod 当作是一个抽象的虚拟机,里面运行若干个不同的进程,每个进程实际上就是一个容器。
实现上,先创建一个 pause 容器,创建相关命名空间,然后创建 Pod 中的其他应用容器,并共享 pause 容器的命名空间。
组成容器组的若干容器往往是存在共同的应用目的,彼此关联十分紧密。经典应用场景包括:
- 内容管理,文件和数据加载,缓存管理等;
- 日志处理,状态快照等;
- 监控代理,消息发布等;
- 代理机制,网桥、网卡等;
- 控制器、管理器、配置以及更新等。
容器组既保持了容器轻量解耦的特性,又提供了调度操作的便利性,在实践中提供了比单个容器更为灵活和更有意义的抽象。Pod 生命周期的五种状态值:
- 待定(Pending):已经被系统接受,但容器镜像还未就绪;
- 运行(Running):分配到节点,所有容器都被创建,至少一个容器在运行中;
- 成功(Succeeded):所有容器都正常退出,不需要重启,任务完成;
- 失败(Failed):所有容器都退出,至少一个容器是非正常退出;
- 未知(Unknown):未知状态,例如所在节点无法汇报状态。
服务
Service 的提出,主要是解决 Pod 地址可变的问题,分配不随 Pod 位置变化而改变的虚拟访问地址,符合微服务的理念,跟负载均衡器实现的功能很相似。
组成一个服务的 Pod 可能是属于不同复制控制器的,但服务自身是不知道复制控制器的存在的。
每个节点上都会运行一个 kube-proxy 进程,负责将到某个 Service 的访问,代理或者均衡到具体的 Pod 上去;同时,会为每一个服务创建环境变量。
Service 支持进行不同类型的健康检查(通过容器 spec 中的 LivenessProbe 或 ReadinessProbe 字段定义):
- 通过 HTTP 获取资源是否成功;
- 在容器中执行指定命令,返回值是否为 0;
- 打开给定 Socket 端口是否成功。
存储卷
Volume 跟 Pod 有一致的生命周期,Pod 生存过程中,数据卷跟着存在;Pod 退出,则数据卷跟着退出。
比较常见的数据卷类型包括:emptyDir、hostPath、gcePersistentDisk、awsElasticBlockStore、nfs、gitRepo、secret 等。
持久化的存储以插件的形式提供为 PersistentVolume 资源,用户通过请求某个类型的 PersistentVolumeClaim 资源,来从匹配的持久化存储卷上,获取绑定的存储。
控制器抽象对象
控制器抽象对象是对所操控对象的进一步抽象,附加了各种资源的管理功能,包括副本集、部署、状态集、Daemon 集、任务等。
副本集和部署
ReplicaSet 和 Deployment 都适合长期运行的应用类型。即使 Pod 份数是 1,也要使用复制控制器来创建,而不是直接创建 Pod。
Pod 资源是可能随时发生故障的,并不需要保证 Pod 的运行,而是在发生失败后重新生成。
可以将副本集类比为进程的监管者(supervisor)的角色,只不过它不光能保持 Pod 的持续运行,还能保持集群中给定类型 Pod,同时运行的个数为指定值。部署代表用户对集群中应用的一次更新操作。
状态集
无状态的应用,关心的主要是副本的个数,而不关心名称、位置等;与此对应,某些应用需要关心 Pod 的状态,挂载独立的存储。
StatefulSet 正是针对这种需求而设计的,提供比副本集和部署更稳定可靠的运行支持。
Daemon 集
DaemonSet 适合于长期运行在后台的伺服类型应用,例如对节点的日志采集或状态监控等后台支持服务。
任务
Job 代表批处理类型的应用,任务中应用完成某一类处理即可退出,有头有尾。
横向 Pod 扩展器
Horizontal Pod Autoscaler(HPA)解决应用波动的情况,根据 Pod 的使用率,自动调整部署里面 Pod 的个数,保障服务在不同压力情况下,保证平滑的输出效果。
控制管理器会定期检查性能指标,在满足条件时触发横向伸缩。
其他抽象对象
标签
Label 是一组键值对,用来标记所绑定的对象(典型的就是 Pod)的识别属性,进而可以分类。
Label 键支持通过“/”来添加前缀,可以用来标注资源的组织名称等,标签所定义的属性是不唯一的,这意味着不同资源可能带有相同的标签键值对。
注解
Annotation 跟标签很相似,也是键值对。不同的是,注解并不是为了分类资源对象,而是为了给对象增加丰富的描述信息。
信息是任意的,数据量可以很大。包括结构化、非结构化数据。
选择器
Selector 可以通过指定标签键值对,来过滤出一组特定的资源对象。支持的语法包括基于等式(Equality-based)的,和基于集合(Set-based)的。
秘密数据
Secret 资源用来保存一些敏感的数据,这些数据往往不希望别的用户看到,但是在启动某个资源(例如 Pod)的时候需要提供。
通常,秘密数据不要超过 1MB。在整个过程中,只有秘密数据的所有人和最终运行的容器,能获取原始敏感数据。
UID 和名字
UID 是全局唯一的,并且不能复用;名字仅仅要求,在同一个命名空间内是唯一的,并且当某个资源移除后,其名字可以被新的资源复用。
命名空间
Namespace 用来隔离不同用户的资源,类似租户或项目的概念,相同命名空间中的对象,具有相同的访问控制策略。
用户在创建资源的时候,可以通过 –namespace=
- default:资源未指定命名空间情况下,默认属于该空间;
- kube-system:由 Kubernetes 系统自身创建的资源。
污点和容忍
Taint 和 Toleration 用于辅助管理 Pod 到工作节点的调度过程。
可以为一个工作节点注明若干污点,只有对这些污点容忍的 Pod,才可以被调度到这些具有污点的节点上。
重要组件
从头设计一套容器集群管理平台,需要考虑如下几个方面的需求:
- 要采用分布式架构,保证良好的可扩展性;
- 控制平面要实现逻辑上的集中,数据平面要实现物理上的分布;
- 得有一套资源调度系统,负责所有的资源调度工作,要容易插拔;
- 对资源对象要进行抽象,所有资源要能实现高可用性。
从架构上看,Kubernetes 集群采用了典型的主从架构:一个集群主要由管理节点(Master)和工作节点(Node)组件构成。Master 节点负责控制,Node 节点负责干活,各自又通过若干组件来实现:
- etcd:作为数据库,存放所有集群状态和配置相关的数据;
- kube-apiserver:Kubernetes 系统的对外接口,提供 RESTful API 供客户端和其他组件调用,支持水平扩展;
- kube-scheduler:负责对资源进行调度,具体负责分配某个请求的 Pod 到某个节点上;
- controller-manager:对不同资源的管理器,维护集群的状态,包括故障检测、自动扩展、滚动更新等;
- kube-ui:可选,自带的一套用来查看集群状态的 Web 界面;
- kube-dns:可选,记录启动的 Pod 和服务地址。
这些组件可以任意部署在相同或不同机器上,只要可以通过标准的 HTTP 接口,相互访问到即可。
Node 节点是实际工作的计算实例,可以是虚拟机或物理机器,Node 上至少包括:
- 容器引擎:本地的容器依赖,目前支持 Docker 和 rkt;
- kubelet:跟 Master 节点通信,节点上最主要的工作代理,汇报节点状态并实现容器组的生命周期管理;
- kube-proxy:负责网络相关功能,代理对抽象应用地址的访问,负责匹配正确的服务发现、负载均衡转发规则;
- 辅助组件:可选,Supervisord 用来保持 kubelet 和 docker 进程运行,Fluentd 用来转发日志等。
Node 节点有几个重要属性:
地址信息(Address):
- 主机名(HostName):节点所在的系统的主机别名,一般不会用到;
- 外部地址(ExternalIP):集群外部客户端可以通过该地址访问到节点;
- 内部地址(InternalIP):集群内可访问的地址,外部往往无法通过该地址访问节点。
状态(Condition):
- 磁盘不足(OutOfDisk);
- 就绪(Ready);
- 空余内存过低(MemoryPressure);
- 空余磁盘过低(DiskPressure)。
资源容量(Capacity):
- CPU;
- 内存;
- 最多存放的 Pod 个数。
节点信息(Info):
- 操作系统内核信息;
- Kubernetes 版本信息;
- Docker 引擎版本信息。
网络设计
网络是集群十分关键的功能,k8s 在设计上考虑了对网络的需求和模型设计,但自身并没有重新实现,而是可以另外嵌入现有的网络管理方案。
Kubernetes 通过
插件化的形式,采用 Container Networking Interface(CNI)规范,所有支持 k8s 的网络插件都要遵循该规范。
场景分析
对于 k8s 集群来说,典型的要考虑如下四种通信场景:
- Pod 内(容器之间):因为容器共享了网络命名空间,可以通过
lo直接通信,无须额外支持; - Pod 之间:
- 同一节点:通过本地网桥通信即可;
- 不同节点:在各自绑定的网桥之间通信。
- Pod 和服务之间:因为服务是虚拟的 IP,需要在节点上配置代理机制(例如基于 iptables)来映射到后端的 Pod;
- 外部访问服务:要从外部访问服务,必须经过负载均衡器,通过外部可用的地址映射到内部的服务上。
k8s 在网络方面的设计理念,包括如下几点:
- 所有容器之间不使用
NAT就可以互相通信; - 所有节点跟容器之间不使用 NAT 就可以互相通信;
- 容器自己看到的地址,和其他人访问自己使用的地址是一样的。
这个设计理念与云平台里面的虚拟机网络十分类似,意味着基于虚拟机云的项目可以方便地迁移到 Kubernetes 平台上。
现代云计算领域常见的网络实现方式:直接路由和 Overlay 网络。
直接路由
这种实现的最大优势是简洁,可以直接服用底层的物理设备。目前,GCE 和 Azure 都支持这种模式。
Overlay 路由
Overlay 网络相对要复杂一些,支持底层更灵活的转发。目前包括 Flannel、Open vSwitch、Weave、Calico 等一系列方案都能实现用 Overlay 网络来联通不同节点上的 Pod。
虽然 Kubernetes 自身并没有提出 Paas 或者 DevOps 的理念,但它提供的资源抽象接口和生命周期管理概念,让用户可以很方便地进行二次开发,打造生产级别的应用系统。