基于循环队列的生产者-消费者模型
非循环的顺序队列在添加、删除数据的工程中,会涉及数据的搬移操作,导致性能变差。而循环队列正好可以解决这个数据搬移的问题,所以,性能更加好。所以,大部分用到顺序队列的场景中,我们都选择用顺序队列中的循环队列。实际上,循环队列这种数据结构,就是我们今天要讲的内存消息队列的雏形。我借助循环队列,实现了一个最简单的生产者-消费者模型。为了方便你理解,对于生产者和消费者之间操作的同步,我并没有用到线程相关的操作。而是采用了“当队列满了之后,生产者就轮训等待;当队列空了之后,消费者就轮训等待”这样的措施:
1 | public class Queue { |
基于加锁的并发生产者-消费者模型
如果我们只有一个生产者往队列中写数据,一个消费者从队列中读取数据,那上面的代码是没有问题的。但是,如果有多个生产者在并发地往队列中写入数据,或者多个消费者并发地从队列中消费数据,那上面的代码就不能正确工作了。在多个生产者或者多个消费者并发操作队列的情况下,刚刚的代码主要会有下面两个问题:
- 多个生产者写入的数据可能会互相覆盖;
- 多个消费者可能会读取重复的数据;
两个线程同时往队列中添加数据,也就相当于两个线程同时执行类 Queue 中的 add() 函数。我们假设队列的大小 size 是 10,当前的 tail 指向下标 7,head 指向下标 3,也就是说,队列中还有空闲空间。这个时候,线程 1 调用 add() 函数,往队列中添加一个值为 12 的数据;线程 2 调用 add() 函数,往队列中添加一个值为 15 的数据。在极端情况下,本来是往队列中添加了两个数据(12 和 15),最终可能只有一个数据添加成功,另一个数据会被覆盖: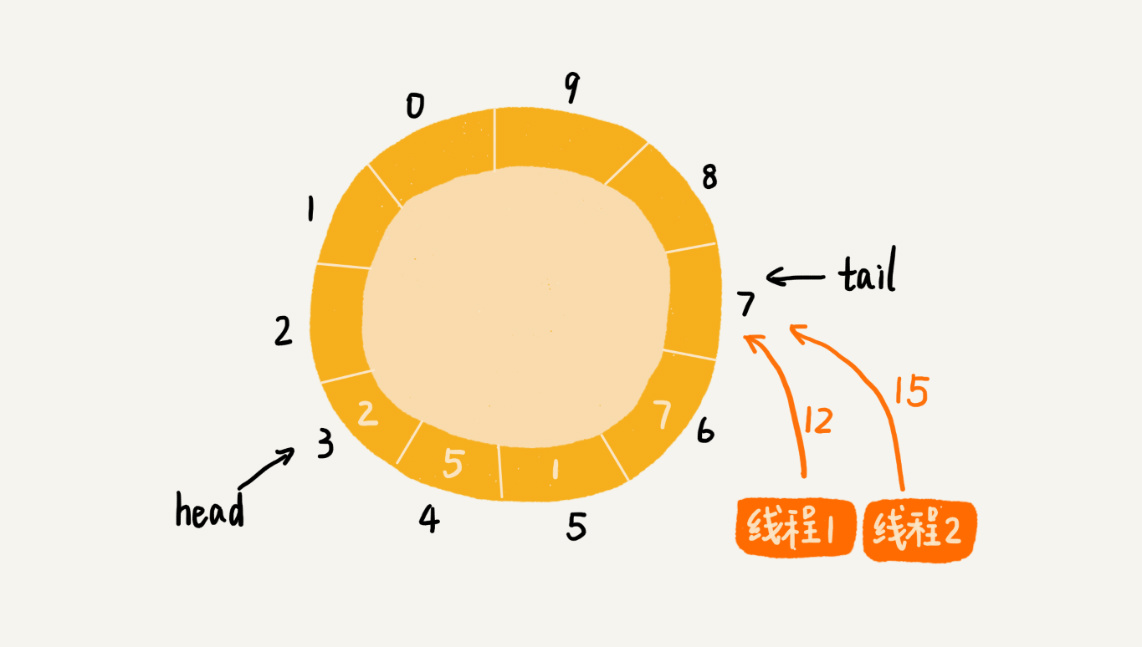
那如何解决这种线程并发往队列中添加数据时,导致的数据覆盖、运行不正确问题呢?最简单的处理方法就是给这段代码加锁,同一时间只允许一个线程执行 add() 函数。这就相当于将这段代码的执行,由并行改成了串行,也就不存在我们刚刚说的问题了。不过,天下没有免费的午餐,加锁将并行改成串行,必然导致多个生产者同时生产数据的时候,执行效率的下降。当然,我们可以继续优化代码,用 CAS(Compare-And-Swap)操作等减少加锁的粒度。
基于无锁的并发生产者-消费者模型
之前的实现思路中,队列只支持两个操作,添加数据和读取并移除数据,分别对应代码中的 add() 函数和 poll() 函数,而 Disruptor 采用了另一种实现思路。对于生产者来说,它往队列中添加数据之前,先申请可用空闲存储单元,并且是批量地申请连续的 n 个(n >= 1)存储单元。当申请到这组连续的存储单元之后,后续往队列中添加元素,就可以不用加锁了,因为这组存储单元是这个线程独享的。不过,从刚刚的描述中,我们可以看出,申请存储单元的过程是需要加锁的。对于消费者来说,处理的过程跟生产者是类似的。它先去申请一批连续可读的存储单元(这个申请的过程也是需要加锁的),当申请到这批存储单元之后,后续的读取操作就可以不用加锁了。
不过,还有一个需要特别注意的地方,那就是,如果生产者 A 申请到了一组连续的存储单元,假设是下标为 3 到 6 的存储单元,生产者 B 紧跟着申请到了下标是 7 到 9 的存储单元,那在 3 到 6 没有完全写入数据之前,7 到 9 的数据是无法读取的。这个也是 Disruptor 实现思路的一个弊端: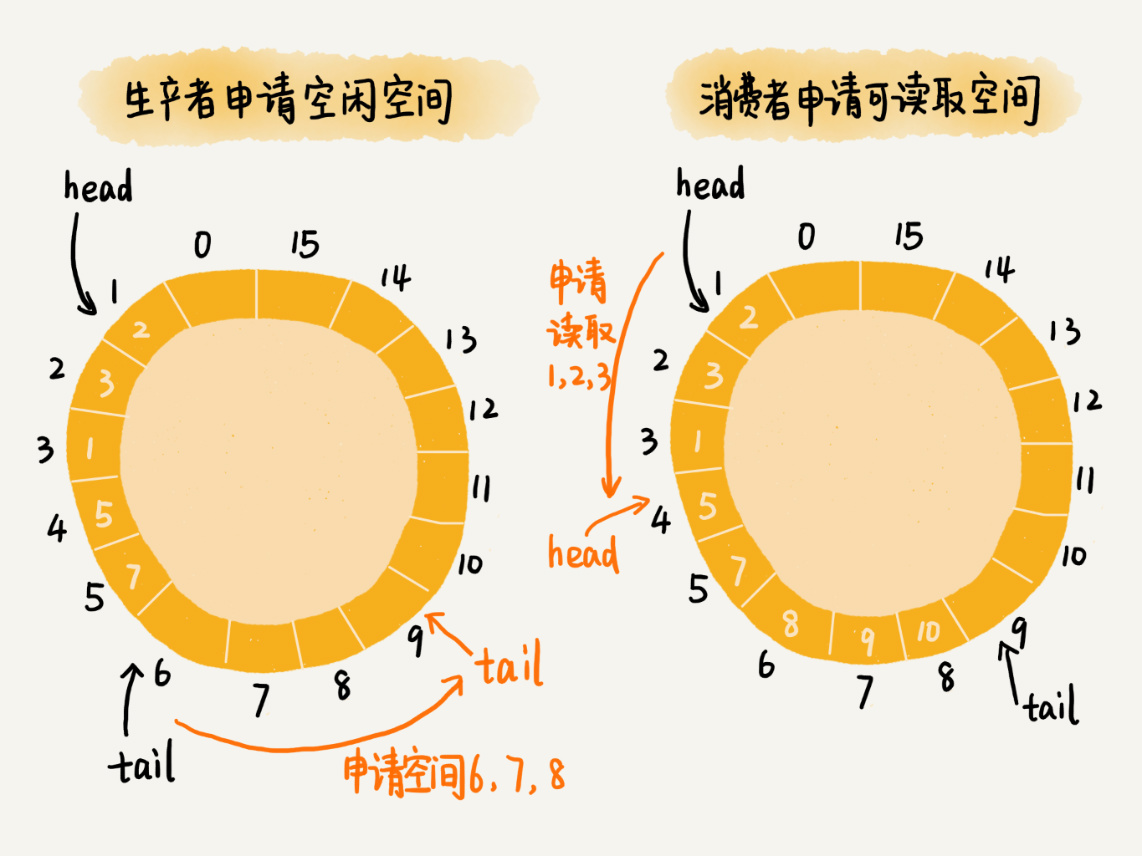
实际上,Disruptor 采用的是 RingBuffer 和 AvailableBuffer 这两个结构,来实现我刚刚讲的功能。不过,因为我们主要聚焦在数据结构和算法上,所以我对这两种结构做了简化,但是基本思想是一致的。