函数和递归
自定义函数和结构体
函数可以定义成:
1 | 返回类型 函数名(参数列表) |
函数体的最后一条语句,应该是“return 表达式”;
参数和返回值最好是“一等公民”;
执行过程中,碰到了 return 语句,将直接退出这个函数,不去执行后面的语句;
始终没有 return 语句,则会返回一个不确定的值。
定义结构体的方法为:
1 | struct 结构体名称 |
函数和递归
函数可以定义成:
1 | 返回类型 函数名(参数列表) |
函数体的最后一条语句,应该是“return 表达式”;
参数和返回值最好是“一等公民”;
执行过程中,碰到了 return 语句,将直接退出这个函数,不去执行后面的语句;
始终没有 return 语句,则会返回一个不确定的值。
定义结构体的方法为:
1 | struct 结构体名称 |
基本概念、面向对象技术
能够直接反应现实生活中的对象。
由于 Java 为解释型语言,编译器会把 Java 代码变成中间代码,然后在 JVM 上解释执行。
中间代码与平台无关,可以很好地跨平台执行,具有很好的可移植性。
简化了开发人员的程序设计工作,同时缩短了项目开发的时间。
对多线程的支持、对网络通讯的支持、垃圾回收器。
常常得先把那些乱七八糟的数据,处理成漂亮点的结构化形式。
一次执行一条语句。
“>>>”是提示符,可以在那里输入表达式。
重视可读性、简洁性、明确性,可执行的伪代码。
通过空白符(4 个空格)来组织代码。
冒号表示一段缩进代码块的开始,其后必须缩进相同的量,直到代码块结束为止:
决策过程中提出的每个判定问题都是对某个属性的测试
考虑范围在上一次决策结果的限定范围之内
决策树学习的目的是为了,产生一棵处理未见示例能力强的决策树。
遵循简单且直观的分而治之(divide-and-comquer)策略。
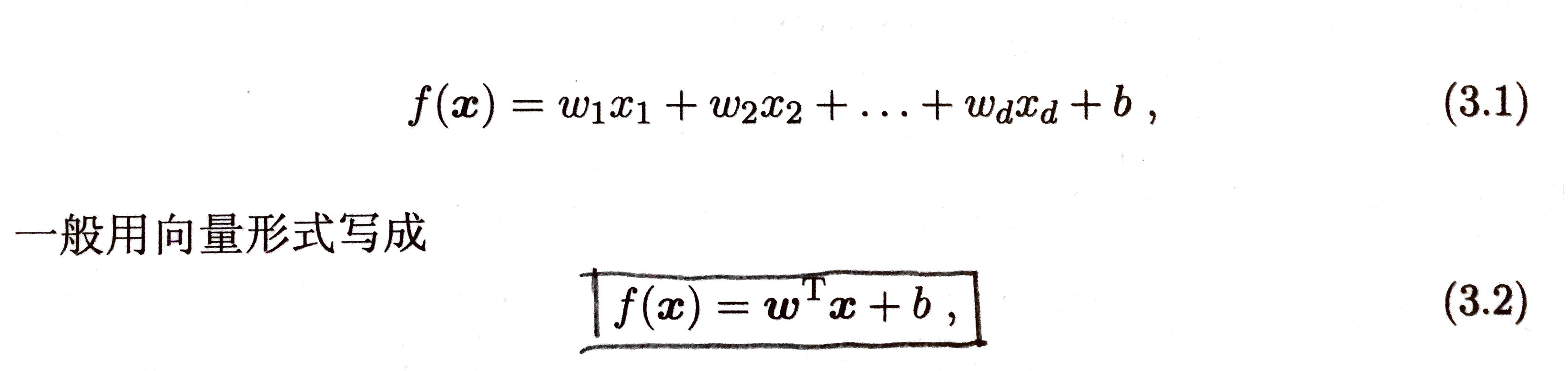
xi 是 x 在第 i 个属性上的取值。
w 和 b 学得之后,模型就得以确定。
许多功能更为强大的非线性模型(nolinear model)可在线性模型的基础上,通过引入层级结构或高维映射而得。
w 直观表达了各属性在预测中的重要性,因此线性模型有很好的可解释性(comprehensibility)。