图像处理算法
预处理
在获取到上传的血常规化验单图片后,项目中对其进行了预处理,作用主要是为了减小噪声,为后边的识别算法服务,在这里主要用到了以下两个方法:
高斯平滑
1
img_gb = cv2.GaussianBlur(img_gray, (gb_param, gb_param), 0)
腐蚀、膨胀
1
2closed = cv2.morphologyEx(img_gb, cv2.MORPH_CLOSE, kernel)
opened = cv2.morphologyEx(closed, cv2.MORPH_OPEN, kernel)
线段检测
为了对图片各个数值所在的区域进行定位,这里需要检测出图片中比较明显的标识,3 条黑线,然后利用这三条线对整张图片进行标定。主要用到了以下 3 个步骤:
Canny 边缘检测
1
edges = cv2.Canny(opened, canny_param_lower, canny_param_upper)
轮廓提取
1
contours, hierarchy = cv2.findContours(edges, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
求最小外接矩形
1
2
3
4
5def getbox(i):
rect = cv2.minAreaRect(contours[i])
box = cv2.cv.BoxPoints(rect)
box = np.int0(box)
return box
OCR
这里主要利用 OCR 对血常规报告中的字符进行识别,得到具体的数值,用于后续的预测。其中步骤主要是根据上边求得的三条线段对图片进行透射变换,根据标定好的像素位置,利用 pytesseract 进行字符识别。
透射变换:
1 | points = np.array([[line_upper[0][0], line_upper[0][1]], [line_upper[1][0], line_upper[1][1]],[line_lower[0][0], line_lower[0][1]], [line_lower[1][0], line_lower[1][1]]], np.float32) |
截图:
1 | def autocut(self, num, param=default): |
pytesseract:
1 | for i in range(num): |
机器学习算法
工业革命让人造机器取代人类完成了大部分的体力劳动,随着机器学习能力的不断提升人类有望可以将部分脑力劳动也交给机器完成。深度学习通过模拟生物神经网络来构建学习框架(人造神经网络),每个人造神经元使用激活函数来非线性地编码数据,不同层级的人造神经元间依靠权重值来传输数据,最终整个人造神经网络就会像人类的大脑一样拥有学习的能力(目前人造神经网络的复杂度还远不及生物,仅拥有很基本的学习能力)。深度学习可以让机器以目前最接近生物思考的方法进行运转,进而可能代替人类完成一部分脑力劳动。
深度学习跟传统的机器学习相比最大的优势在于不需要人工进行特征采集。传统的机器学习需要专业人士在特定数据中发现其特征,而深度学习能够通过算法自动完成这一过程,我们只需要构建一个通用的框架,然后提供数据和所想要的结果,最后通过不断地训练框架及优化其参数就可以获得具备某项能力的机器。
生物神经网络主要由很多神经元相互连接而成,人造神经网络也一样由人造神经元互联而成,如下图所示。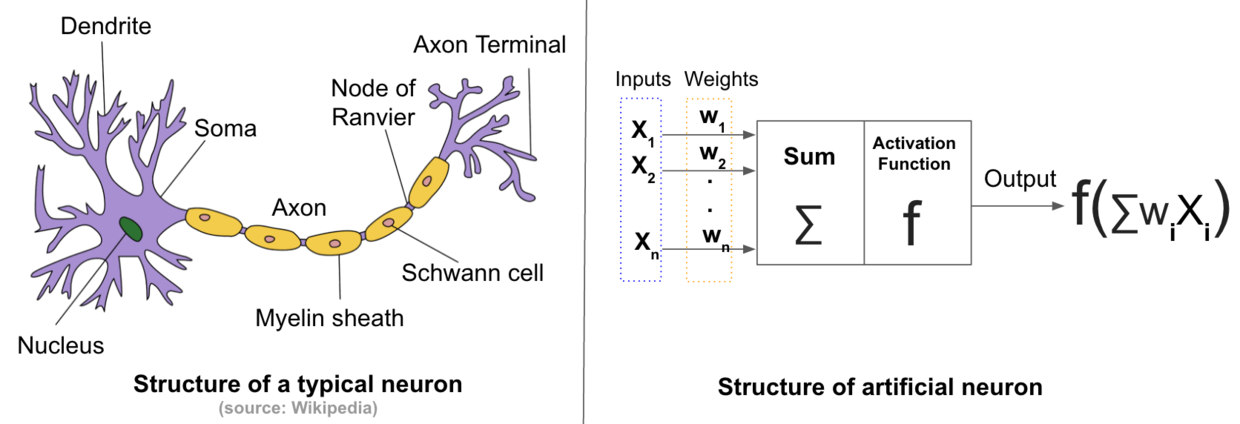
一个人造神经元有一定数量的输入接口,每个输入都拥有一个对应的权重值,数据通过输入进入后要通过一个激活函数才能输出,这个函数需要是非线性的(模拟生物神经元),常见的激活函数包括 Sigmoid, Tanh 以及 ReLU ,如下图所示,其中 ReLU 是深度学习中最常用的。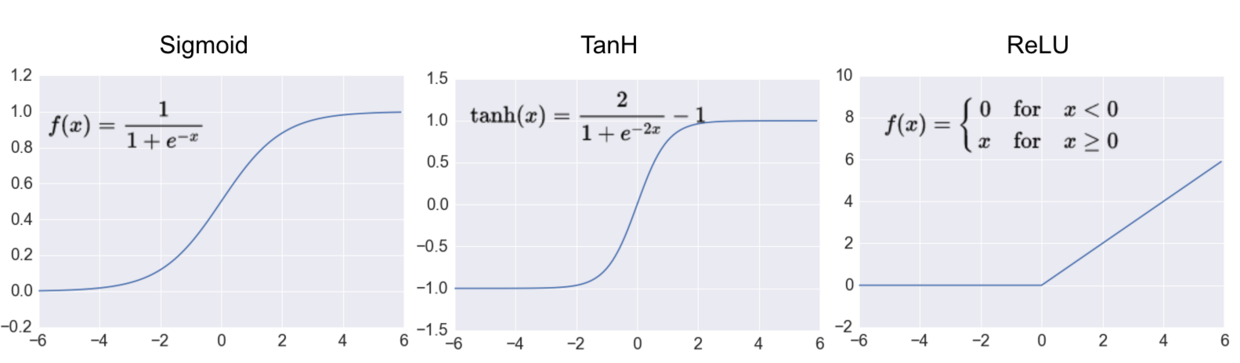
一个人造神经元的输出可能是另一个的输入,如此不断连接在一起便构成了人造神经网络,如下图所示。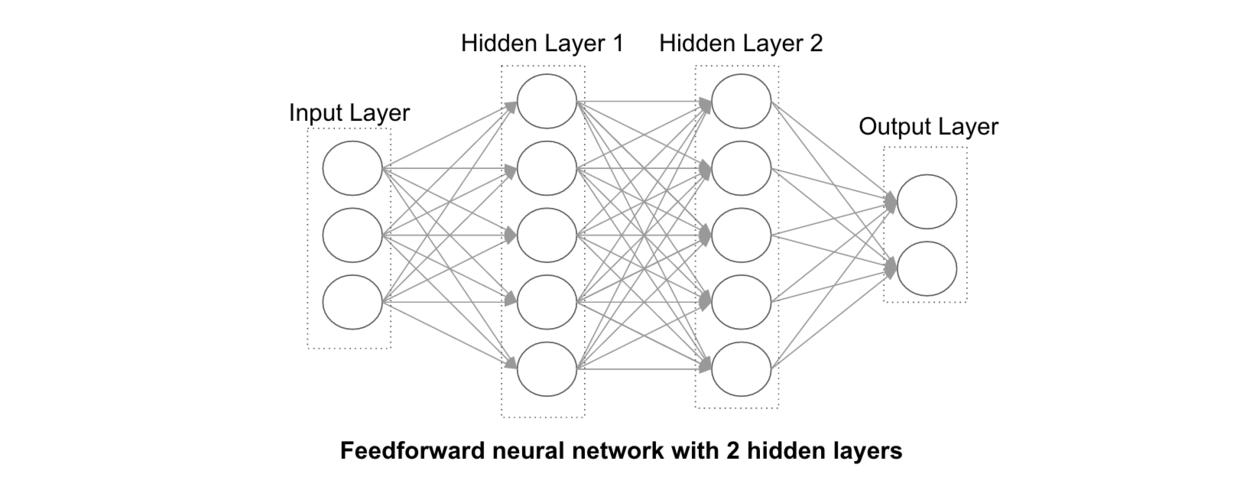
一个特定的人造神经网络可以解决一类特定的问题,要获得一个解决特定问题的人造神经网络需要使用相关数据对其进行训练,训练使用结合梯度检验的反向传导算法进行。通过大量相关数据的训练人造神经元的权重值会越来越接近真实的范围,其人造神经网络也就越来越成熟。
数据预处理
为了提高机器学习的准确程度,避免由于数据本身的数值不统一等对学习结果造成影响,需要对样本集进行一定的预处理。在本门课程中,我用到的预处理方法主要是去均值与归一化。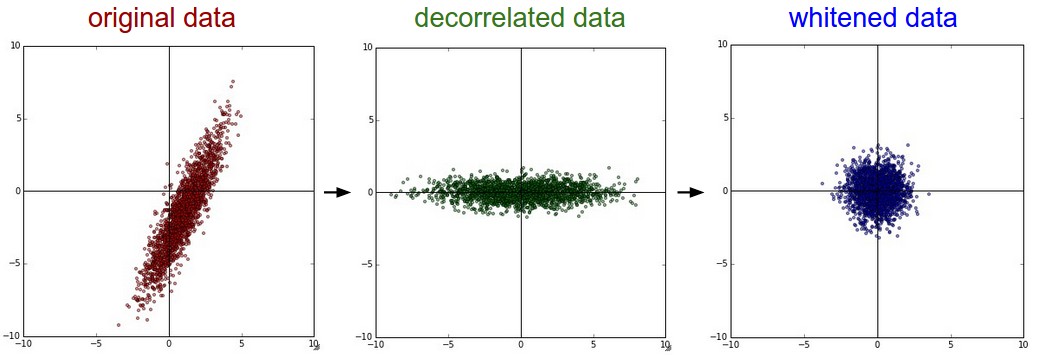
去均值:
去均值的具体做法是在每个样本上减去数据的统计平均值,去均值的意义主要在于扩大分类的效果。查看 TensorFlow 的 MNIST 源码时可以看到,程序中对每个像素点的像素值都减去了 128,这就是去均值操作。
归一化:
数据尺度归一化的原因是:数据中每个维度表示的意义不同,所以有可能导致该维度的变化范围不同,因此有必要将他们都归一化到一个固定的范围,一般情况下是归一化到 [0 1] 或者 [-1 1]。同样在 TensorFlow 的 MNIST 源码中可以看到,去均值后,会将每点的像素值除以 128,进行了归一化操作。
下边是我在本门课程中写的去均值与归一化代码,a 是训练集,b 是需要预测的一组样本。返回结果是去均值与归一化之后的样本 b。
1 | def normalized(a,b): |
深度学习平台
为了实现上述的机器学习算法,需要选择一个深度学习的平台。在这里我选择的是 TensorFlow。对于我们学习来说,TensorFlow 的主要优点是文档齐全,更容易找到相关的 demo 和出现 bug 的解决方法。
在本课程中,学习了 TensorFlow 的基本使用,基本的使用流程如下:
读取数据为 ndarray 类型
1
2
3
4
5
6
7data = np.loadtxt(open("./data.csv","rb"),delimiter=",",skiprows=0)
tmp = normalized(data[:,2:])
tmp_label_sex = one_hot(data[:,0:1],data.shape[0])
train_label_sex = tmp_label_sex[:1858, :]
test_label_sex = tmp_label_sex[1858:, :]
train_data = tmp[:1858,:]
test_data = tmp[1858:,:]定义模型(各层结构,损失,优化方法)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25x = tf.placeholder("float", [None, n_input])
y = tf.placeholder("float", [None, n_classes])
keep_prob = tf.placeholder("float")
def multilayer_perceptron(x, weights, biases):
layer_1 = tf.add(tf.matmul(x, weights['h1']), biases['b1'])
layer_1 = tf.nn.relu(layer_1)
layer_2 = tf.add(tf.matmul(layer_1, weights['h2']), biases['b2'])
layer_2 = tf.nn.relu(layer_2)
out_layer = tf.matmul(layer_2, weights['out']) + biases['out']
return out_layer
weights =
{
'h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_hidden_2, n_classes]))
}
biases =
{
'b1': tf.Variable(tf.random_normal([n_hidden_1])),
'b2': tf.Variable(tf.random_normal([n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
pred = multilayer_perceptron(x, weights, biases)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)训练
1
2
3
4with tf.Session() as sess:
sess.run(init)
for epoch in range(2000):
_, c = sess.run([optimizer, cost], feed_dict={x: train_data, y: train_label_sex})保存模型
1
2saver = tf.train.Saver()
save_path = saver.save(sess, "./model_sex/sex.ckpt", write_meta_graph=None)恢复模型
1
saver.restore(sess1, "./model_sex/sex.ckpt")
预测
1
p = sess1.run(pred, feed_dict={x: data_predict})
Web 相关
这门课程名为《网络程序设计》,目标是完成一个 Web 系统,所以在这之中,除了项目的关注点机器学习,我还学到了一部分 Web 相关的知识。
Vue.js
Vue.js 的目标是通过尽可能简单的 API 实现响应的数据绑定和组合的视图组件。
Vue.js 自身不是一个全能框架——它只聚焦于视图层。因此它非常容易学习,非常容易与其它库或已有项目整合。另一方面,在与相关工具和支持库一起使用时,Vue.js 也能完美地驱动复杂的单页应用。
在本项目中,利用 Vue.js 对数据进行绑定,以表格的左半边为例:
1 | data: |
1 | for (var i = 0; i < json_data["bloodtest"].length; i++) |
1 | <table id= "table_left" class="table table-inverse table-hover table-bordered"> |
然后当用户在界面修改后,因为已经绑定,只需要直接调用 data,即可获取到相关值:
1 | data[i] = Number(this.report_items_left[i].value); |
Flask
Flask 是 Python 下的一个轻量级 Web 框架,主要用于处理前端的 http 请求。
首先在运行时启动服务器:
1 | app = Flask(__name__, static_url_path="") |
然后在前端利用 Ajax 就可以访问到后端的对应函数:
1 | url = 'report/' + url.split('/')[2]; |
在后端接受前端的 http 访问请求:
1 | @app.route('/report/<fid>') |
MongoDB
在本课程中,用到的数据库是 MongoDB,主要用于将矫正后的图片与 OCR 识别结果存入数据库中。
首先是打开服务器的时候连接数据库:
1 | db = MongoClient(app.config['DB_HOST'], app.config['DB_PORT']).test |
在上传图片后,将校正后的图片以及识别到的各项数值存入数据库中:
1 | c = dict |
也可利用 fid,进行结果查询:
1 | try: |
版本库 URL
GitHub - necusjz/np2106: 对血常规检验报告的OCR识别、深度学习与分析。
安装运行方法
运行环境
1 | sudo apt-get install python-numpy |
运行
1 | cd BloodTestReportOCR |
Demo 过程截图
首先定位到 BloodTestReportOCR 中,输入 python view.py: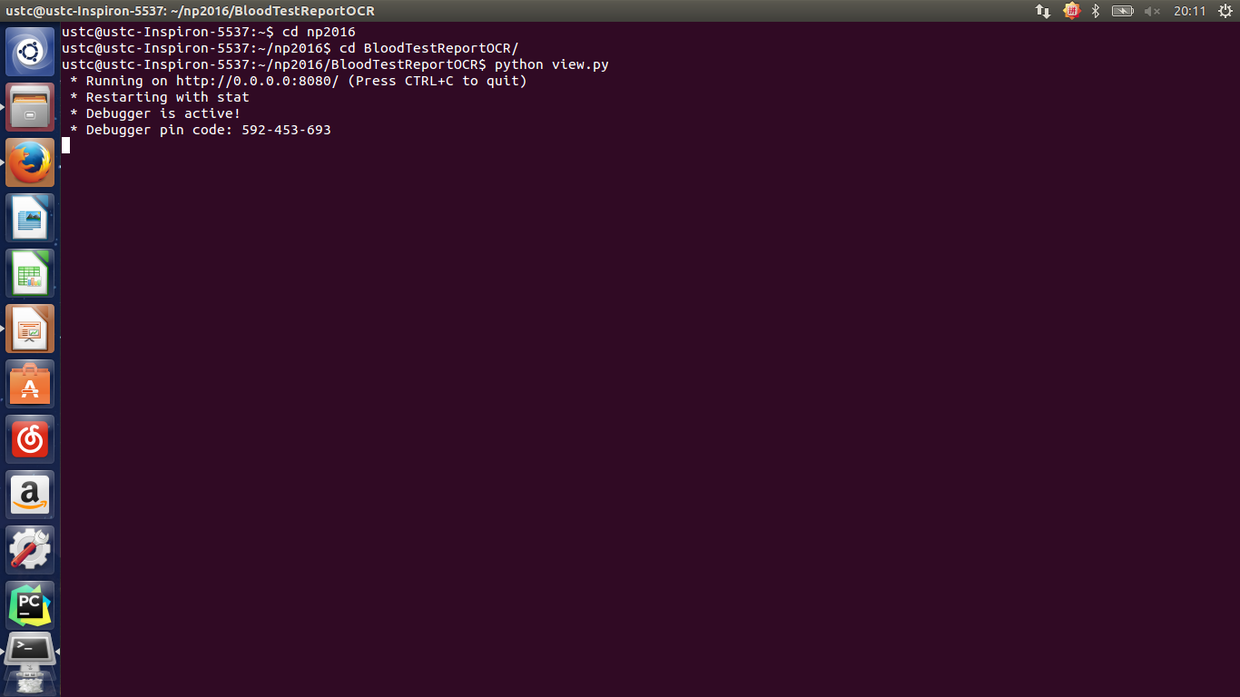
然后打开浏览器,输入 localhost:8080: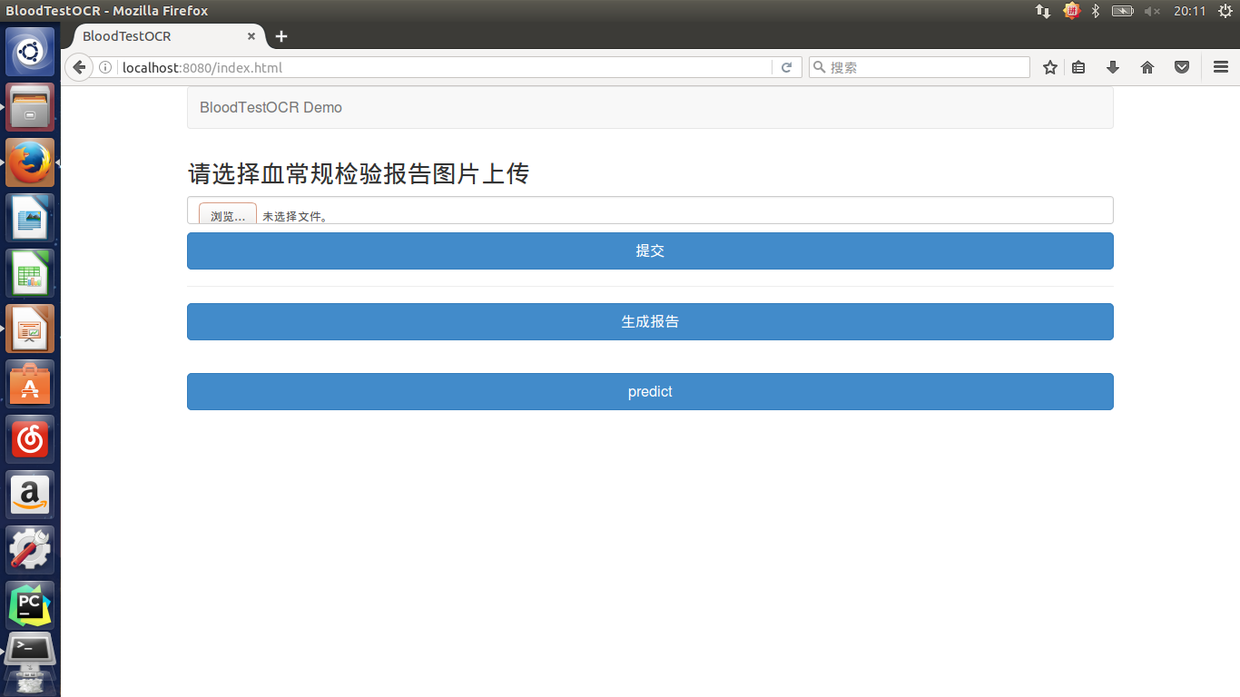
上传图片后得到矫正后的图片: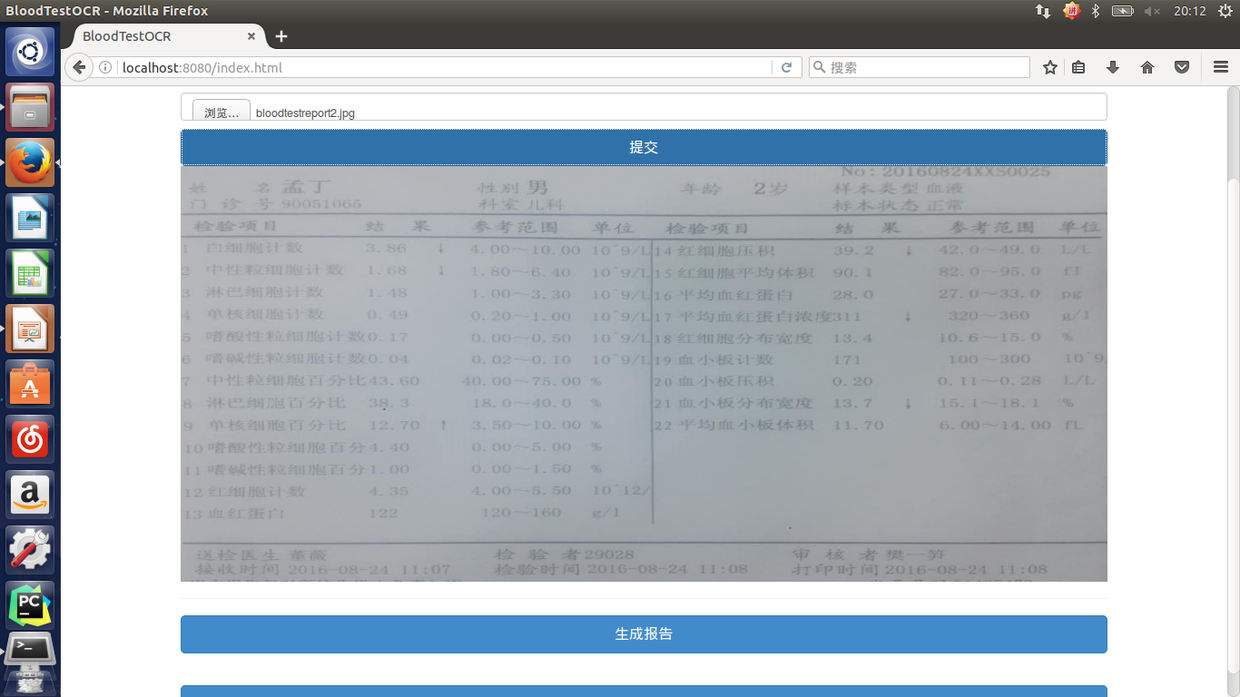
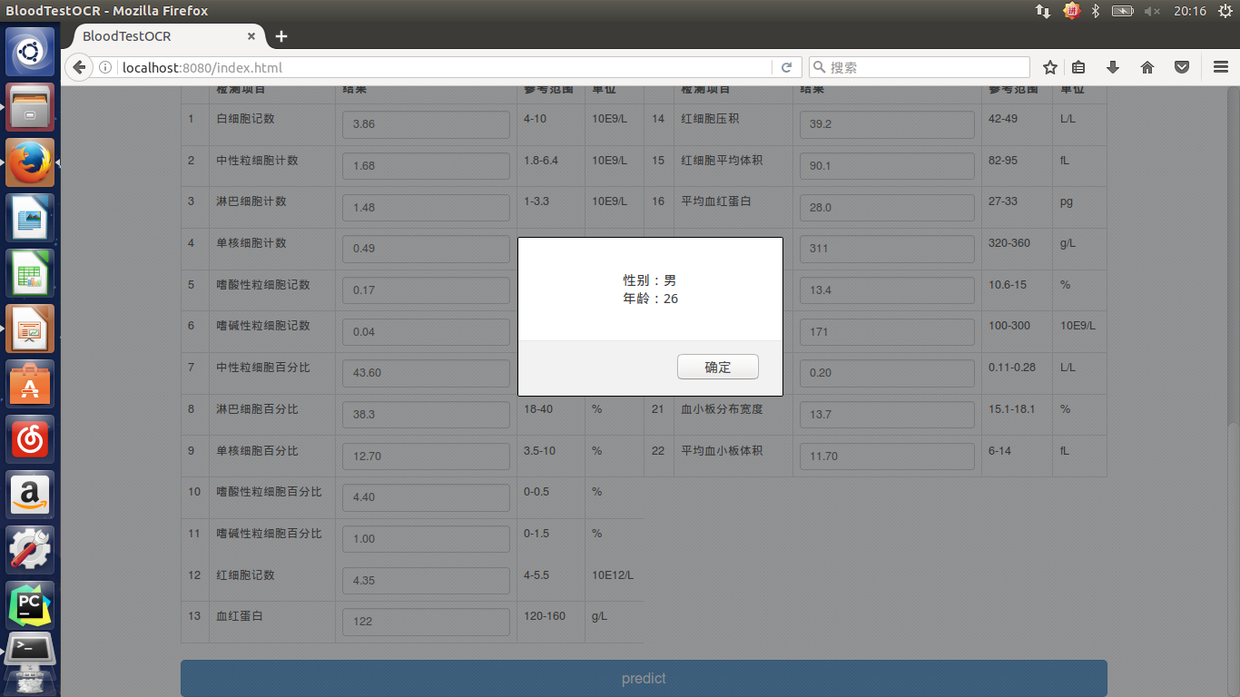
点击“生成报告”,得到 OCR 的结果: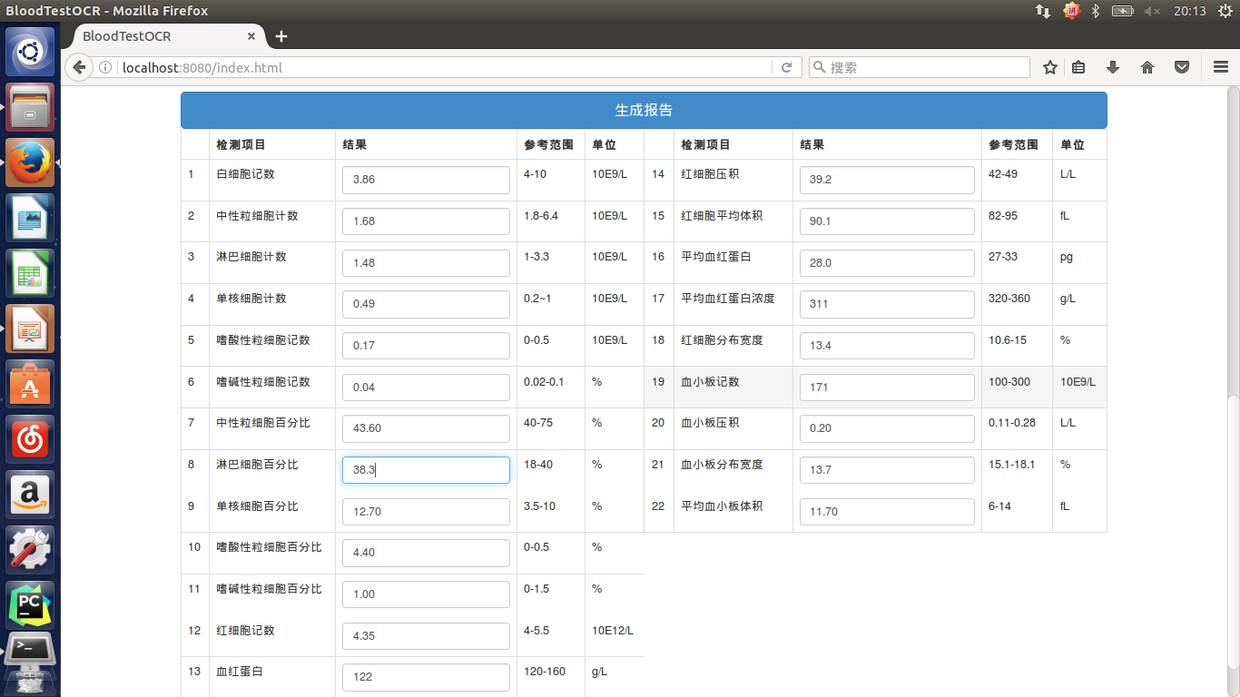
点击“predict”,得到预测结果: