项目背景
文本分析、情感分析和社交分析帮助你在一定规模上转化成客户、病人、公众以及市场的“声音”。这项技术目前大量地应用于一系列的工业产品中,从医疗健康到金融、媒体、甚至客户市场。它们从线上、社交网络、企业数据源中提取商业洞察力。
本次项目通过对爬取的用户评论数据进行分析,对各个不同的电影进行相关的预测。关键的分类部分是基于有监督的机器学习,以不同机器学习算法为基础构建分类器对文本分类。
总体设计
本课题采用有监督的机器学习方法。对初始数据处理后,通过人工标注、特征选取、降维、训练,最终得到准确度高的分类器对所有数据进行输出。
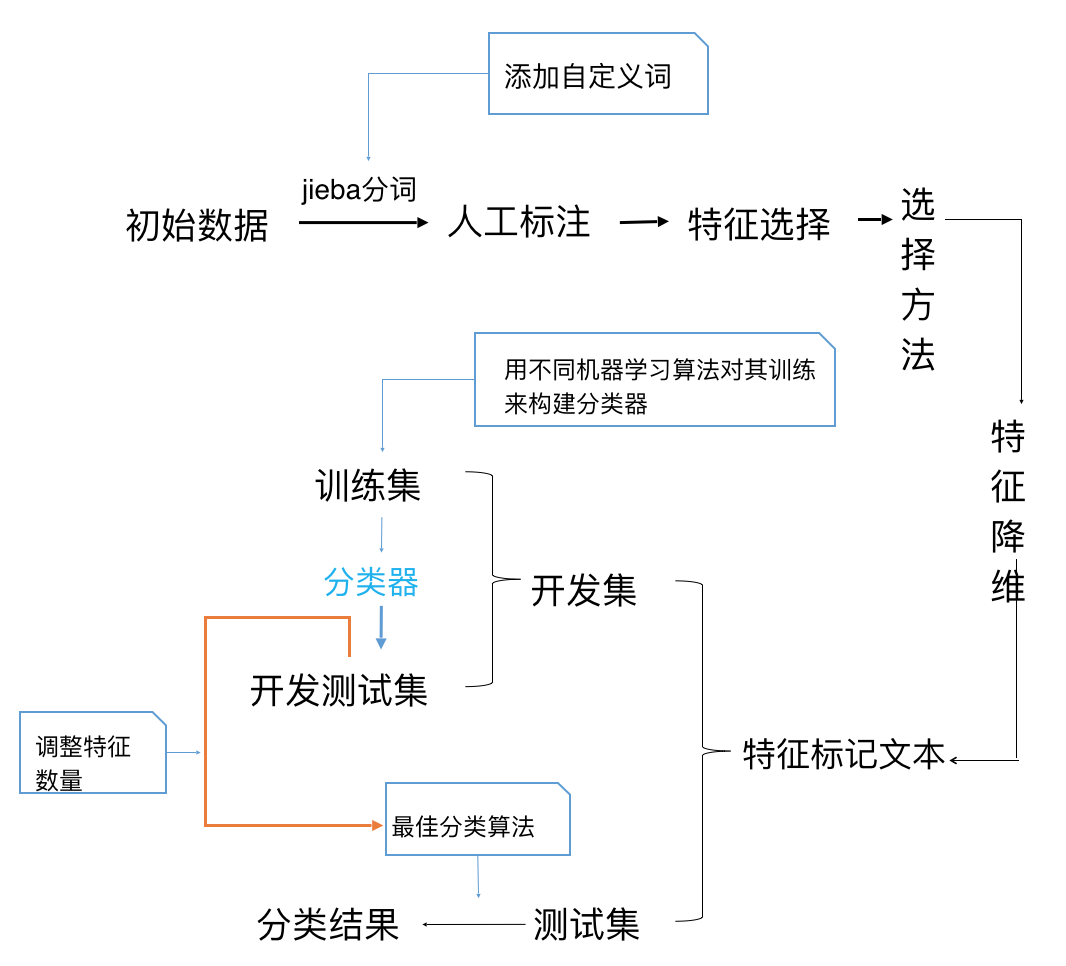
第一步,就是确定一个词是积极还是消极,是主观还是客观。
这一步主要依靠词典,英文已经有伟大词典资源:SentiWordNet。 无论积极消极、主观客观,还有词语的情感强度值都一并拿下。在中文领域,判断积极和消极已经有不少词典资源,如:Hownet、NTUSD 等。
第二步,就是识别一个句子是积极还是消极,是主观还是客观。
有词典的时候,好办。直接去匹配看一个句子有什么词典里面的词,然后加总就可以计算出句子的情感分值。中文领域的难度:还是词典太差。还有就是用机器学习方法判断主客观非常麻烦,一般需要人工标注。
第三步,情感挖掘就升级到意见挖掘(Opinion Mining)了。
这就需要在情感分析的基础上,先挖掘出产品的属性,再分析对应属性的情感。分析完每一条评论的所有属性的情感后,就可以汇总起来,形成消费者对一款产品各个部分的评价。
详细设计
源文件处理
源文件保存在 excel 中,由于本项目使用有监督的机器学习算法,因此需要对文件进行类别的标注,以备接下来使用。
评论录入与分词
评论是存放在 excel 格式的文件中,这可以由 python 提供的有关 excel 操作的 xlrd 库来进行读取。分词则是由 jieba 分词模块进行。
统计
加载文件之后调用相关统计模块:包含分词,统计词频等。

文本表示
经第三步之后,进入文本分析,权重分析并记录。
机器学习
在权重计算和文本表示之后,就可以进行机器学习了,首先分集合,之后进行机器学习训练,预测,得出结果。
划分:
划分训练集和测试集用于机器学习
训练:
将权重列表作为参数进行训练
预测:
输入测试用例进行预测
结果:
得到概率,计算得出分数。
成果展示
标记展示
相关 excel 文件的标记展示,标记阶段尽量保证两类的数量要基本一致。
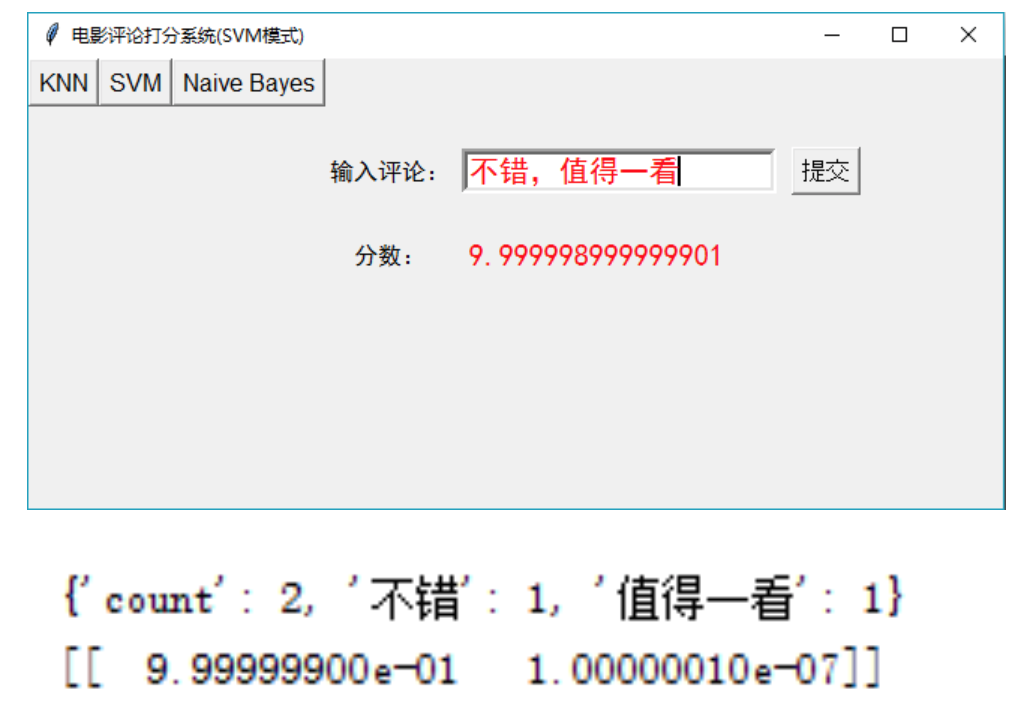
界面展示
界面设计由 python 的 tkinter 库参考设计。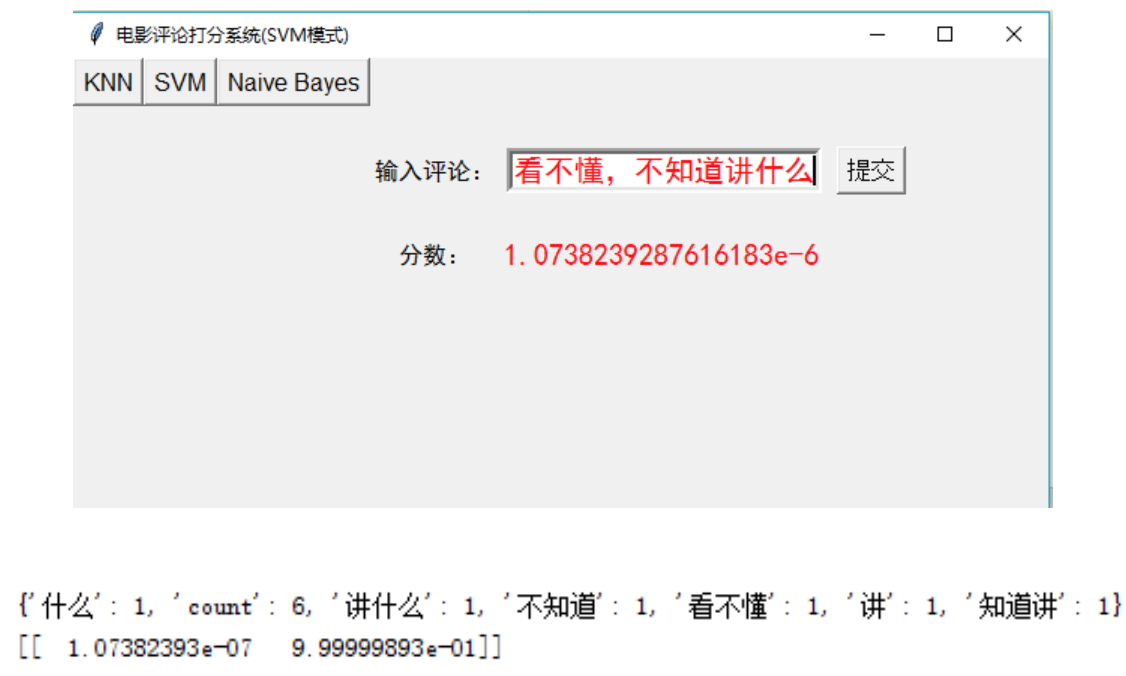
操作流程
准备好 PyCharm和JDK 1.8
安装 Homebrew
在终端输入:
1 | /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" |
安装 Python 3.x
1 | brew install python3 |
安装 numpy、scipy、scikit-learn 库
1 | sudo pip3 install numpy |
1 | sudo pip3 install scipy |
1 | sudo pip3 install scikit-learn |
安装 jieba、xlrd 库
jieba:
1 | git clone https://github.com/fxsjy/jieba.git |
1 | git checkout jieba3k |
1 | cd your-jieba-site |
1 | python3 setup.py install |
xlrd:
下载xlrd
1 | cd your-xlrd-site |
1 | python3 setup.py install |
运行程序
用 PyCharm 导入 natural_language.py、tkTest.py 并运行后者即可看见结果。