Spring 框架简单介绍
我们常说的 Spring 框架,是指 Spring Framework 基础框架。Spring Framework 是整个 Spring 生态(也被称作 Spring 全家桶)的基石。除了 Spring Framework,Spring 全家桶中还有更多基于 Spring Framework 开发出来的、整合更多功能的框架,比如 Spring Boot、Spring Cloud。在 Spring 全家桶中,Spring Framework 是最基础、最底层的一部分。它提供了最基础、最核心的 IoC 和 AOP 功能。当然,它包含的功能还不仅如此,还有其他比如事务管理(Transactions)、MVC 框架(Spring MVC)等很多功能: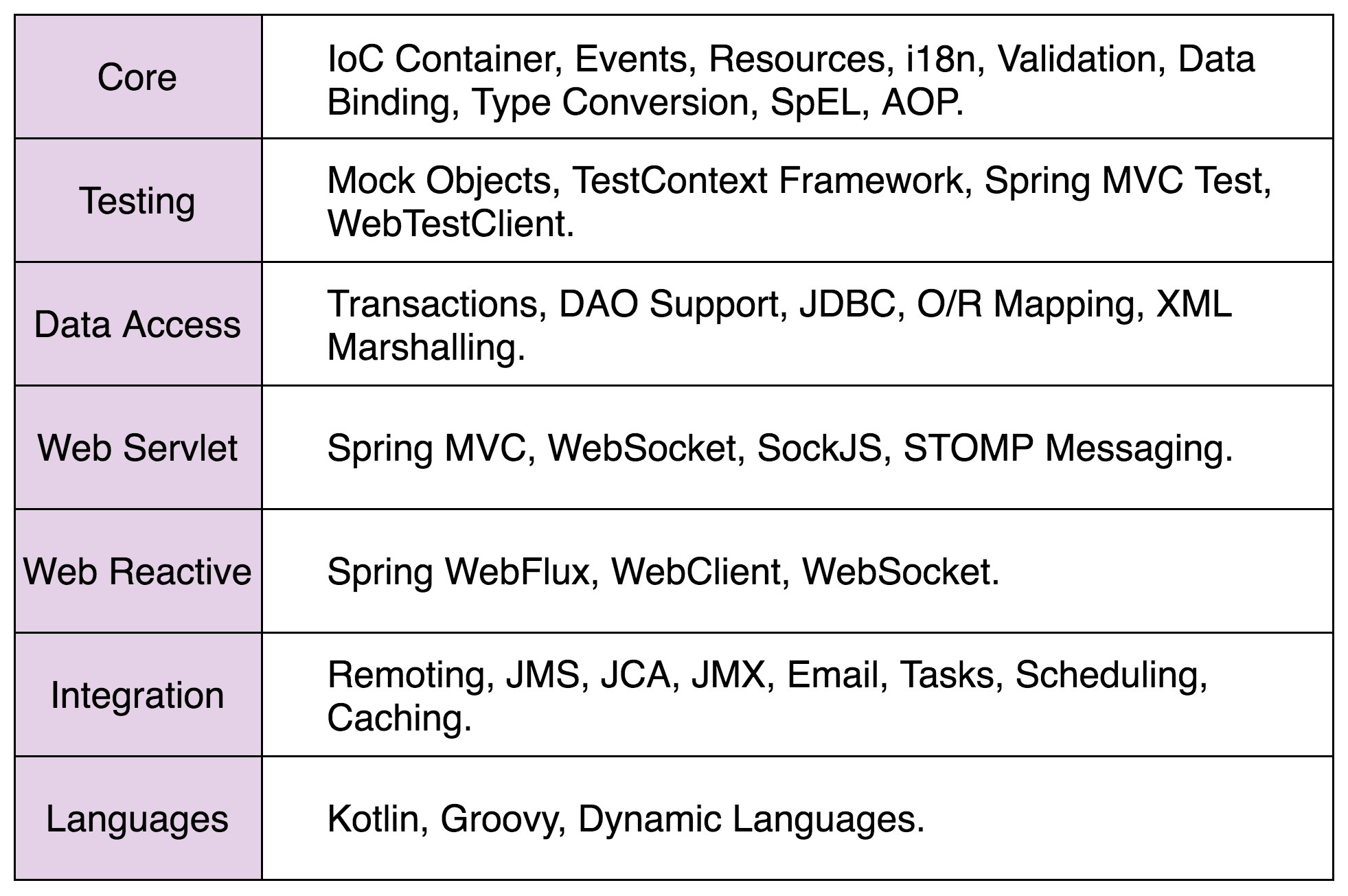
在 Spring Framework 中,Spring MVC 出镜率很高,经常被单独拎出来使用。它是支持 Web 开发的 MVC 框架,提供了 URL 路由、Session 管理、模板引擎等跟 Web 开发相关的一系列功能;Spring Boot 是基于 Spring Framework 开发的,它更加专注于微服务开发。之所以名字里带有“Boot”一词,跟它的设计初衷有关,Spring Boot 的设计初衷是快速启动一个项目,利用它可以快速地实现一个项目的开发、部署和运行。Spring Boot 支持的所有功能都是围绕着这个初衷设计的,比如:集成很多第三方开发包、简化配置(比如,规约优于配置)、集成内嵌 Web 容器(比如,Tomcat、Jetty)等;单个的微服务开发,使用 Spring Boot 就足够了,但是,如果要构建整个微服务集群,就需要用到 Spring Cloud 了。Spring Cloud 主要负责微服务集群的服务治理工作,包含很多独立的功能组件,比如 Spring Cloud Sleuth 调用链追踪、Spring Cloud Config 配置中心等。
从 Spring 看框架的作用
利用框架的好处有:解耦业务和非业务开发,让程序员聚焦在业务开发上;隐藏复杂实现细节、降低开发难度、减少代码 Bug;实现代码复用、节省开发时间;规范化标准化项目开发、降低学习和维护成本等等。相比单纯的 CRUD 业务代码开发,非业务代码开发要更难一些。所以,将一些非业务的通用代码开发为框架,在项目中复用,除了节省开发时间之外,也降低了项目开发的难度。除此之外,框架经过多个项目的多次验证,比起每个项目都重新开发,代码的 Bug 会相对少一些。而且,不同的项目使用相同的框架,对于研发人员来说,从一个项目切换到另一个项目的学习成本,也会降低很多。
通过在项目中引入 Spring MVC 开发框架,开发一个 Web 应用,我们只需要创建 Controller、Service、Repository 三层类,在其中填写相应的业务代码,然后做些简单的配置,告知框架 Controller、Service、Repository 类之间的调用关系,剩下的非业务相关的工作,比如,对象的创建、组装、管理,请求的解析、封装,URL 与 Controller 之间的映射,都由框架来完成。不仅如此,如果我们直接引入功能更强大的 Spring Boot,那将应用部署到 Web 容器的工作都省掉了。Spring Boot 内嵌了 Tomcat、Jetty 等 Web 容器。在编写完代码之后,我们用一条命令就能完成项目的部署、运行。
Spring 框架蕴含的设计思想
我们剖析一下 Spring 框架背后的一些经典设计思想(或开发技巧)。这些设计思想并非 Spring 独有,都比较通用,能借鉴应用在很多通用功能模块的设计开发中。
约定优于配置
在使用 Spring 开发的项目中,配置往往会比较复杂、繁琐。比如,我们利用 Spring MVC 来开发 Web 应用,需要配置每个 Controller 类以及 Controller 类中的接口对应的 URL。如何来简化配置呢?一般来讲,有两种方法:
- 基于注解;
- 基于约定;
基于注解的配置方式,我们在指定类上使用指定的注解,来替代集中的 XML 配置。比如,我们使用 @RequestMapping 注解,在 Controller 类或者接口上,标注对应的 URL;使用 @Transaction 注解表明支持事务等。基于约定的配置方式,也常叫作“约定优于配置”(Convention Over Configuration)。通过约定的代码结构或者命名来减少配置,说直白点,就是提供配置的默认值,优先使用默认值,程序员只需要设置那些偏离约定的配置就可以了。实际上,约定优于配置,很好地体现了“二八法则”。在平时的项目开发中,80% 的配置使用默认配置就可以了,只有 20% 的配置必须用户显式地去设置。所以,基于约定来配置,在没有牺牲配置灵活性的前提下,节省了我们大量编写配置的时间,省掉了很多不动脑子的纯体力劳动,提高了开发效率。除此之外,基于相同的约定来做开发,也减少了项目的学习成本和维护成本。
低侵入、松耦合
框架的侵入性是衡量框架好坏的重要指标。所谓低侵入指的是,框架代码很少耦合在业务代码中。低侵入意味着,当我们要替换一个框架的时候,对原有的业务代码改动会很少。相反,如果一个框架是高度侵入的,代码高度侵入到业务代码中,那替换成另一个框架的成本将非常高,甚至几乎不可能。这也是一些长期维护的老项目,使用的框架、技术比较老旧,又无法更新的一个很重要的原因。
Spring 提供的 IoC 容器,在不需要 Bean 继承任何父类或者实现任何接口的情况下,仅仅通过配置,就能将它们纳入进 Spring 的管理中。如果我们换一个 IoC 容器,也只是重新配置一下就可以了,原有的 Bean 都不需要任何修改;除此之外,Spring 提供的 AOP 功能,也体现了低侵入的特性。在项目中,对于非业务功能,比如请求日志、数据采点、安全校验、事务等等,我们没必要将它们侵入进业务代码中。因为一旦侵入,这些代码将分散在各个业务代码中,删除、修改的成本就变得很高。而基于 AOP 这种开发模式,将非业务代码集中放到切面中,删除、修改的成本就变得很低了。
模块化、轻量级
随着不断的发展,Spring 现在也不单单只是一个只包含 IoC 功能的小框架了,它显然已经壮大成了一个“平台”或者叫“生态”,包含了各种五花八门的功能。尽管如此,但它也并没有重蹈覆辙,变成一个像 EJB 那样的庞大难用的框架。这就要归功于 Spring 的模块化设计思想: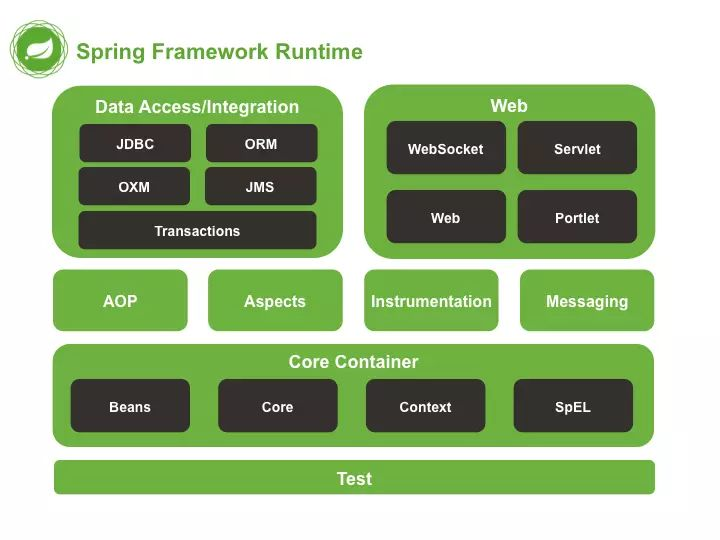
从图中我们可以看出,Spring 在分层、模块化方面做得非常好。每个模块都只负责一个相对独立的功能。模块之间关系,仅有上层对下层的依赖关系,而同层之间以及下层对上层,几乎没有依赖和耦合。除此之外,在依赖 Spring 的项目中,开发者可以有选择地引入某几个模块,而不会因为需要一个小的功能,就被强迫引入整个 Spring 框架。所以,尽管 Spring Framework 包含的模块很多,已经有二十几个,但每个模块都非常轻量级,都可以单独拿来使用。正因如此,到现在,Spring 框架仍然可以被称为是一个轻量级的开发框架。
再封装、再抽象
Spring 不仅仅提供了各种 Java 项目开发的常用功能模块,而且还对市面上主流的中间件、系统的访问类库,做了进一步的封装和抽象,提供了更高层次、更统一的访问接口。比如,Spring 提供了 spring-data-redis 模块,对 Redis Java 开发类库(比如 Jedis、Lettuce)做了进一步的封装,适配 Spring 的访问方式,让编程访问 Redis 更加简单。除此之外,JdbcTemplate 也是对 JDBC 的进一步封装和抽象,为的是进一步简化数据库编程。不仅如此,Spring 对 JDBC 异常也做了进一步的封装,封装的数据库异常继承自 DataAccessException 运行时异常。这类异常在开发中无需强制捕获,从而减少了不必要的异常捕获和处理。除此之外,Spring 封装的数据库异常,还屏蔽了不同数据库异常的细节(比如,不同的数据库对同一报错定义了不同的错误码),让异常的处理更加简单。
观察者模式在 Spring 中的应用
Spring 中实现的观察者模式包含三部分:Event 事件(相当于消息)、Listener 监听者(相当于观察者)、Publisher 发送者(相当于被观察者):
1 | // Event 事件 |
从代码中,我们可以看出,框架使用起来并不复杂,主要包含三部分工作:
- 定义一个继承 ApplicationEvent 的事件(DemoEvent);
- 定义一个实现了 ApplicationListener 的监听器(DemoListener);
- 定义一个发送者(DemoPublisher),发送者调用 ApplicationContext 来发送事件消息;
其中,ApplicationEvent 和 ApplicationListener 的代码实现都非常简单,内部并不包含太多属性和方法。实际上,它们最大的作用是做类型标识(继承自 ApplicationEvent 的类是事件,实现 ApplicationListener 的类是监听器):
1 | public abstract class ApplicationEvent extends EventObject { |
观察者需要事先注册到被观察者(JDK 的实现方式)或者事件总线(EventBus 的实现方式)中,Spring 的实现中,观察者注册到了 ApplicationContext 对象中。ApplicationContext 这个类并不只是为观察者模式服务的,它底层依赖 BeanFactory(IoC 的主要实现类),提供应用启动、运行时的上下文信息,是访问这些信息的最顶层接口。实际上,具体到源码来说,ApplicationContext 只是一个接口,具体的代码实现包含在它的实现类 AbstractApplicationContext 中:
1 | public abstract class AbstractApplicationContext extends ... { |
从上面的代码中,我们发现,真正的消息发送,实际上是通过 ApplicationEventMulticaster 这个类来完成的。这个类的源码我只摘抄了最关键的一部分,也就是 multicastEvent() 这个消息发送函数。它通过线程池,支持异步非阻塞、同步阻塞这两种类型的观察者模式:
1 | public void multicastEvent(ApplicationEvent event) { |
模板模式在 Spring 中的应用
Spring Bean 的创建过程,可以大致分为两大步:
- 对象的创建;
- 对象的初始化;
对象的创建是通过反射来动态生成对象,而不是 new 方法。不管是哪种方式,说白了,总归还是调用构造函数来生成对象,没有什么特殊的。对象的初始化有两种实现方式,一种是在类中自定义一个初始化函数,并且通过配置文件,显式地告知 Spring,哪个函数是初始化函数:
1 | public class DemoClass { |
这种初始化方式有一个缺点,初始化函数并不固定,由用户随意定义,这就需要 Spring 通过反射,在运行时动态地调用这个初始化函数,而反射又会影响代码执行的性能。Spring 提供了另外一个定义初始化函数的方法,那就是让类实现 InitializingBean 接口,这个接口包含一个固定的初始化函数定义(afterPropertiesSet() 函数)。Spring 在初始化 Bean 的时候,可以直接通过 bean.afterPropertiesSet() 的方式,调用 Bean 对象上的这个函数,而不需要使用反射来调用了:
1 | public class DemoClass implements InitializingBean{ |
尽管这种实现方式不会用到反射,执行效率提高了,但业务代码(DemoClass)跟框架代码(InitializingBean)耦合在了一起。框架代码侵入到了业务代码中,替换框架的成本就变高了。所以,我并不是太推荐这种写法。实际上,在 Spring 对 Bean 整个生命周期的管理中,还有一个跟初始化相对应的过程,那就是 Bean 的销毁过程。我们知道,在 Java 中,对象的回收是通过 JVM 来自动完成的。但是,我们可以在将 Bean 正式交给 JVM 垃圾回收前,执行一些销毁操作(比如关闭文件句柄等等)。
销毁过程跟初始化过程非常相似,也有两种实现方式:
- 通过配置 destroy-method 指定类中的销毁函数;
- 让类实现 DisposableBean 接口;
实际上,Spring 针对对象的初始化过程,还做了进一步的细化,将它拆分成了三个小步骤:初始化前置操作、初始化、初始化后置操作。其中,初始化的前置和后置操作,定义在接口 BeanPostProcessor 中:
1 | public interface BeanPostProcessor { |
我们只需要定义一个实现了 BeanPostProcessor 接口的处理器类,并在配置文件中像配置普通 Bean 一样去配置就可以了。Spring 中的 ApplicationContext 会自动检测在配置文件中实现了 BeanPostProcessor 接口的所有 Bean,并把它们注册到 BeanPostProcessor 处理器列表中。在 Spring 容器创建 Bean 的过程中,Spring 会逐一去调用这些处理器。Spring Bean 的整个生命周期(创建加销毁):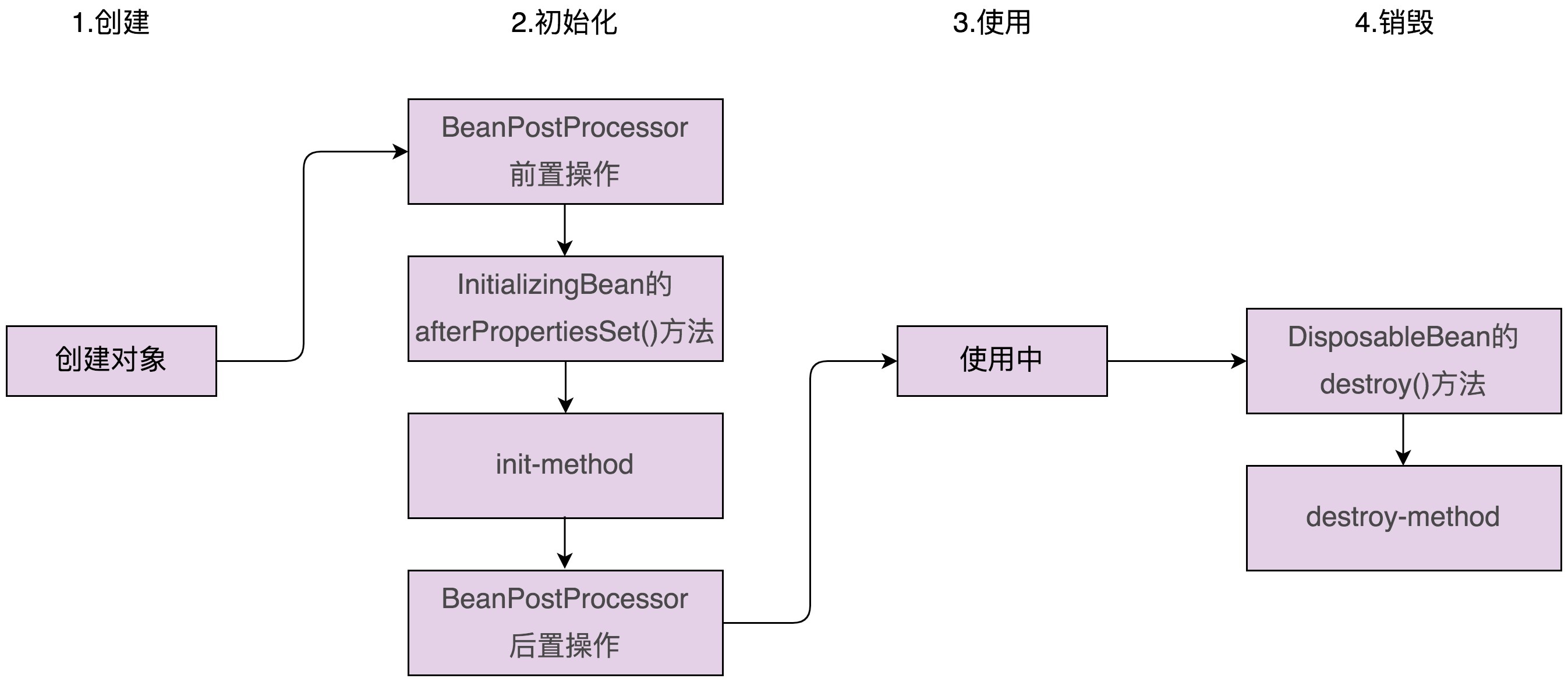
实际上,这里的模板模式的实现,并不是标准的抽象类的实现方式,而是有点类似我们前面讲到的 Callback 回调的实现方式,也就是将要执行的函数封装成对象(比如,初始化方法封装成 InitializingBean 对象),传递给模板(BeanFactory)来执行。
适配器模式在 Spring 中的应用
在 Spring MVC 中,定义一个 Controller 最常用的方式是,通过 @Controller 注解来标记某个类是 Controller 类,通过 @RequestMapping 注解来标记函数对应的 URL。不过,定义一个 Controller 远不止这一种方法。我们还可以通过让类实现 Controller 接口或者 Servlet 接口,来定义一个 Controller:
1 | // 方法一:通过 @Controller、@RequestMapping 来定义 |
在应用启动的时候,Spring 容器会加载这些 Controller 类,并且解析出 URL 对应的处理函数,封装成 Handler 对象,存储到 HandlerMapping 对象中。当有请求到来的时候,DispatcherServlet 从 HandlerMapping 中,查找请求 URL 对应的 Handler,然后调用执行 Handler 对应的函数代码,最后将执行结果返回给客户端。但是,不同方式定义的 Controller,其函数的定义(函数名、入参、返回值等)是不统一的,DispatcherServlet 需要根据不同类型的 Controller,调用不同的函数:
1 | Handler handler = handlerMapping.get(URL); |
从代码中我们可以看出,这种实现方式会有很多 if-else 分支判断,而且,如果要增加一个新的 Controller 的定义方法,我们就要在 DispatcherServlet 类代码中,对应地增加一段如上伪代码所示的 if 逻辑,这显然不符合开闭原则。实际上,我们可以利用是适配器模式对代码进行改造,让其满足开闭原则,能更好地支持扩展。适配器其中一个作用是统一多个类的接口设计,利用适配器模式,我们将不同方式定义的 Controller 类中的函数,适配为统一的函数定义。这样,我们就能在 DispatcherServlet 类代码中,移除掉 if-else 分支判断逻辑,调用统一的函数。
Spring 定义了统一的接口 HandlerAdapter,并且对每种 Controller 定义了对应的适配器类。这些适配器类包括:AnnotationMethodHandlerAdapter、SimpleControllerHandlerAdapter、SimpleServletHandlerAdapter 等:
1 | public interface HandlerAdapter { |
策略模式在 Spring 中的应用
Spring AOP 是通过动态代理来实现的,Spring 支持两种动态代理实现方式:
- JDK 提供的动态代理实现方式;
cglib提供的动态代理实现方式;
前者需要被代理的类有抽象的接口定义,后者不需要。针对不同的被代理类,Spring 会在运行时动态地选择不同的动态代理实现方式,这个应用场景实际上就是策略模式的典型应用场景。策略模式包含三部分,策略的定义、创建和使用。在策略模式中,策略的定义这一部分很简单,我们只需要定义一个策略接口,让不同的策略类都实现这一个策略接口。对应到 Spring 源码,AopProxy 是策略接口,JdkDynamicAopProxy、CglibAopProxy 是两个实现了 AopProxy 接口的策略类:
1 | public interface AopProxy { |
在策略模式中,策略的创建一般通过工厂方法来实现。对应到 Spring 源码,AopProxyFactory 是一个工厂类接口,DefaultAopProxyFactory 是一个默认的工厂类,用来创建 AopProxy 对象:
1 | public interface AopProxyFactory { |
策略模式的典型应用场景,一般是通过环境变量、状态值、计算结果等动态地决定使用哪个策略。对应到 Spring 源码中,我们可以参看刚刚给出的 DefaultAopProxyFactory 类中的 createAopProxy() 函数的代码实现。其中,第 9 行代码是动态选择哪种策略的判断条件。
组合模式在 Spring 中的应用
Spring Cache 提供了一套抽象的 Cache 接口,Spring 中针对不同缓存实现的不同缓存访问类,都依赖这个接口,比如:EhCacheCache、GuavaCache、NoOpCache、RedisCache、JCacheCache、ConcurrentMapCache、CaffeineCache:
1 | public interface Cache { |
在实际的开发中,一个项目有可能会用到多种不同的缓存,比如既用到 Google Guava 缓存,也用到 Redis 缓存。除此之外,同一个缓存实例,也可以根据业务的不同,分割成多个小的逻辑缓存单元(或者叫作命名空间)。为了管理多个缓存,Spring 还提供了缓存管理功能。不过,它包含的功能很简单,主要有这样两部分:
- 根据缓存名字(创建 Cache 对象的时候要设置 name 属性)获取 Cache 对象;
- 获取管理器管理的所有缓存的名字列表;
对应的 Spring 源码如下所示:
1 | public interface CacheManager { |
那如何来实现这两个接口呢?实际上,这就要用到组合模式,组合模式主要应用在能表示成树形结构的一组数据上。树中的结点分为叶子节点和中间节点两类。对应到 Spring 源码,EhCacheManager、SimpleCacheManager、NoOpCacheManager、RedisCacheManager 等表示叶子节点,CompositeCacheManager 表示中间节点。叶子节点包含的是它所管理的 Cache 对象,中间节点 CompositeCacheManger 如下所示;其中,getCache()、getCacheNames() 两个函数的实现都用到了递归,这正是树形结构最能发挥优势的地方:
1 | public class CompositeCacheManager implements CacheManager, InitializingBean { |
装饰器模式在 Spring 中的应用
缓存一般都是配合数据库来使用的,如果写缓存成功,但数据库事务回滚了,那缓存中就会有脏数据。为了解决这个问题,我们需要将缓存的写操作和数据库的写操作,放到同一个事务中,要么都成功,要么都失败。实现这样一个功能,Spring 使用到了装饰器模式。TransactionAwareCacheDecorator 增加了对事务的支持,在事务提交、回滚的时候分别对 Cache 的数据进行处理。TransactionAwareCacheDecorator 实现 Cache 接口,并且将所有的操作都委托给 targetCache 来实现,对其中的写操作添加了事务功能:
1 | public class TransactionAwareCacheDecorator implements Cache { |
工厂模式在 Spring 中的应用
在 Spring 中,工厂模式最经典的应用莫过于实现 IoC 容器,对应的 Spring 源码主要是 BeanFactory 类和 ApplicationContext 相关类。在 Spring 中,创建 Bean 的方式有很多种,比如前面提到的纯构造函数、无参构造函数加 setter 方法:
1 | public class Student { |
实际上,除了这两种创建 Bean 的方式之外,我们还可以通过工厂方法来创建 Bean:
1 | public class StudentFactory { |
其他模式在 Spring 中的应用
SpEL,全称叫 Spring Expression Language,是 Spring 中常用来编写配置的表达式语言。它定义了一系列的语法规则。我们只要按照这些语法规则来编写表达式,Spring 就能解析出表达式的含义。实际上,这就是我们前面讲到的解释器模式的典型应用场景,代码主要集中在 spring-expression 这个模块下面;单例模式有很多弊端,比如单元测试不友好等。应对策略是通过 IoC 容器来管理对象,通过 IoC 容器来实现对象的唯一性的控制。实际上,这样实现的单例并非真正的单例,它的唯一性的作用范围仅仅在同一个 IoC 容器内;实际上,在 Spring 中,只要后缀带有 Template 的类,基本上都是模板类,而且大部分都是用 Callback 回调来实现的,比如 JdbcTemplate、RedisTemplate 等;剩下的两个模式在 Spring 中的应用应该人尽皆知了:职责链模式在 Spring 中的应用是拦截器(Interceptor),代理模式经典应用是 AOP。