In-memory database technology is a core feature of the SAP HANA database, which enables new applications that were not possible before.
Impact of Modern Hardware on Database System Architecture
In the past database management systems were designed for optimizing performance on hardware with limited main memory and with slow disk I/O as the main bottleneck. The focus was on optimizing disk access, for example by minimizing the number of disk pages to be read into main memory when processing a query.
Today’s computer architectures have changed. With multi-core processors, parallel processing is possible with fast communication between processor cores. Very large main memory configurations are now commercially available and affordable.
With all relevant data in memory, disk access is no longer a limiting factor for performance. With the increasing number of cores, CPUs are able to process more and more data per time interval. That means the performance bottleneck is now between the CPU cache and main memory.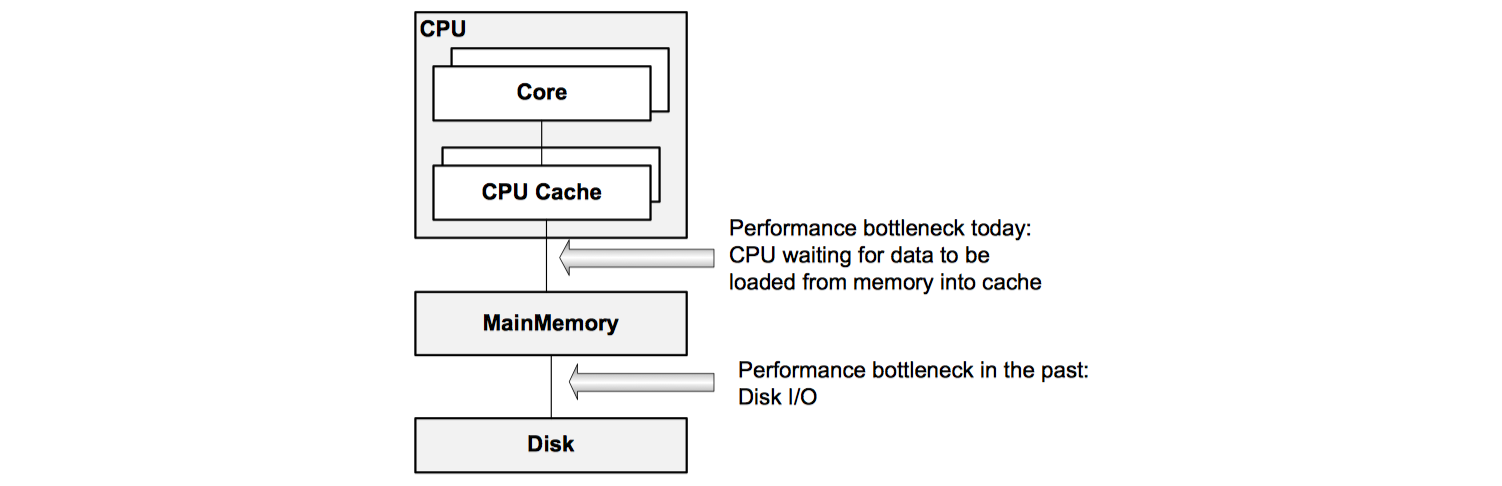
A high performance data management system for modern hardware must have the following characteristics:
- In-memory database
All relevant data must be kept in main memory, so read operations can be executed without disk I/O. Disk storage is still needed to make changes durable. - Cache aware memory organization, optimization and execution
The design must minimize the number of CPU cache misses and avoid CPU stalls because of memory access. One approach for achieving this goal is using column-based storage in memory. This leads to high spatial locality of data and instructions, so the operations can be executed completely in the CPU cache without costly random memory accesses. - Support for parallel execution
In recent years CPUs did not become faster by increasing clock rates. Instead the number of processor cores was increased. For data management systems this means that it must be possible to partition data in sections for which the calculations can be executed in parallel.
Columnar and Row-Based Data Storage
For storing a table in linear memory, two options can be chosen. A row store stores a sequence of records that contains the fields of one row in the table. In a column store, the entries of column are stored in contiguous memory locations.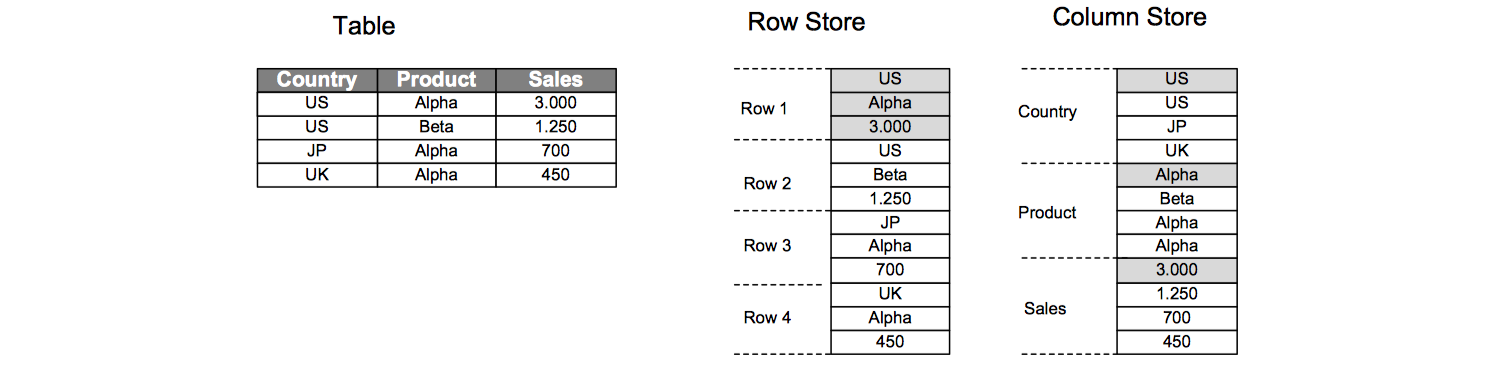
Choosing Between Column and Row Store
Column-based tables have advantages if:
- Calculations are typically executed on single of few columns only.
- The table is searched based on values of a few columns.
- The table has a big number of columns.
- The table has a big number of rows and columnar operations are required (aggregate, scan, …).
- High compression rate can be achieved because the majority of the columns contain only a few distinct values.
Row-based tables have advantages if:
- The application needs to process only one single record at one time.
- The application typically needs to access the complete record.
- The columns contain mainly distinct values so the data compression rate would be low.
- Neither aggregations nor fast search are required.
- The table has a small number of rows.
Advantages of Columnar Tables
Higher Data Compression Rates
The goal to keep all relevant data in main memory can be achieved with lower cost because data compression is used. Columnar data storage allows highly efficient compression. Especially if the column is sorted, there will be ranges of the same values in contiguous memory, so compression methods such as run length encoding or cluster encoding can be used more effectively.
Higher Performance for Column Operations
With columnar data organization, operation on single columns, such as searching or aggregations can be implemented as loops over an array stored in contiguous memory locations.
Higher data compression rate not only saves memory but also increases speed for the following reasons:
- Compressed data can be loaded faster into the CPU cache. As the limiting factor is the data transport between memory and CPU cache, the performance gain exceeds the additional computing time needed for decompression.
- With dictionary encoding, the columns are stored as arrays of bit encoded integers. That means that check for equality can be executed on the integers. This is much faster than comparing for example string values.
- Compression can speed up operations such as scans and aggregations if the operator is aware of the compression. Given a good compression rate, computing the sum of the values in a column will be much faster if many additions of the same value can be replaced by a single multiplication.
Elimination of Additional Indexes
Storing data in columns already works like having a built-in index for each column. In many cases it will not be required to have addition index structures. Eliminating indexes reduces memory size, can improve write performance, and reduces development efforts.
Elimination of Materialized Aggregates
Traditional business applications use materialized aggregates to increase read performance. That means that the application developers define additional tables in which the application redundantly stores the results of aggregates computed on other tables.
SAP HANA eliminates the need for materialized aggregates in many cases. Financial applications, for instance, can compute totals and balances from the accounting documents when they are queried, instead of maintaining them as materialized values.
Eliminating materialized aggregates has several advantages:
- It simplifies data model and aggregation logic, which makes development and maintenance more efficient.
- It allows for a higher level of concurrency because write operations do not require exclusive locks for updating aggregated values.
- It ensures that the aggregated values are always up-to-date, while materialized aggregates are sometimes updated only at scheduled times.
Parallelization
Column-based storage also simplifies parallel execution using multiple processor cores. That means operations on different columns can easily be processed in parallel.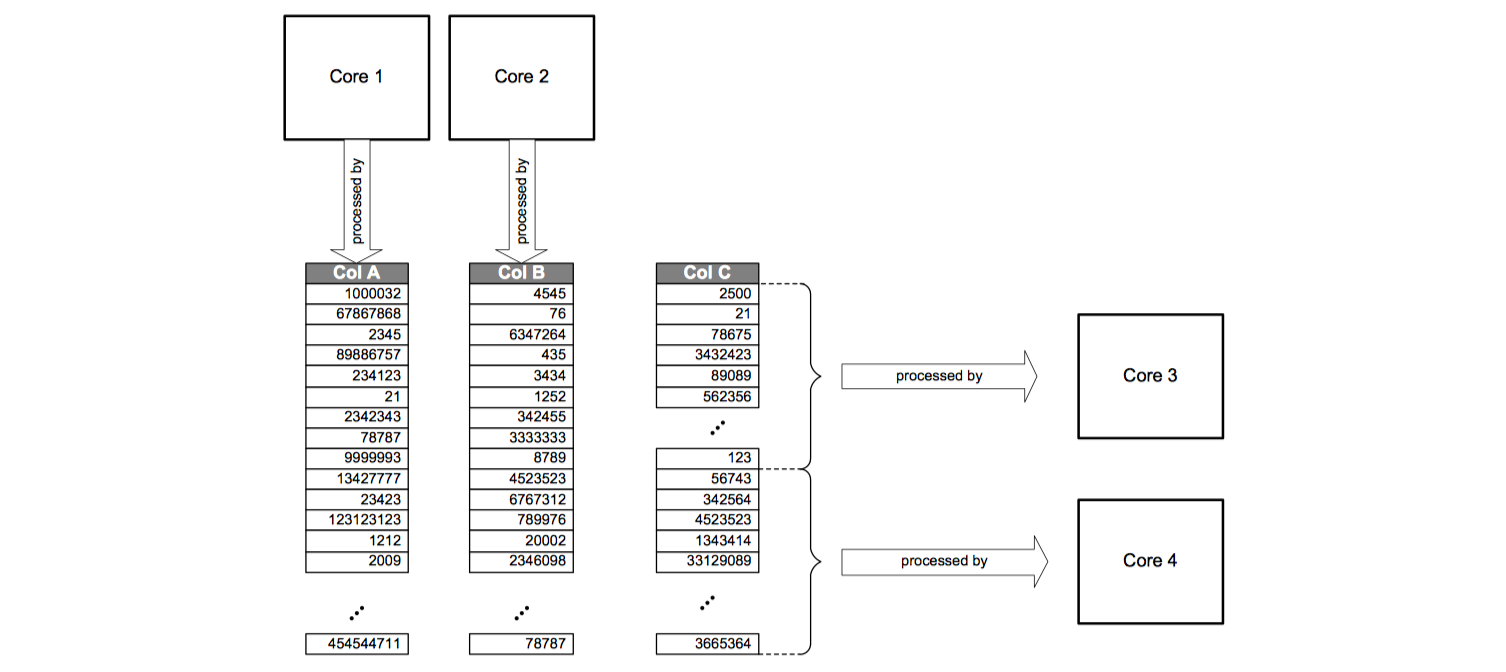
If multiple columns need to be searched or aggregated, each of these operations can be assigned to a different processor core. In addition, the execution of operations on one column can be parallelized by dividing the column into multiple sections that are processed by different processor cores.
History Tables
SAP HANA supports history tables which allow queries on historical data. Applications may use this feature for example for time-based reporting and analysis. Write operations on history tables do not physically overwrite existing records. Instead, write operations always insert new versions of the data record into the database. Each row in a history table has timestamp-like system attributes that indicate the time period when the record version in this row was the current one.
In literature, data with time-based validity or visibility is known as temporal data. The standard distinguishes two levels of temporal data support, which can be characterized as system-versioned and as application-managed.
For system-versioned temporal data, the timestamps are automatically set and indicate the so-called transaction time when the data was current. New versions are automatically created by the system during updates. Application-managed is different, the time period indicates the period of validity on application level.