The SAP HANA System
The SAP HANA system consists of multiple servers: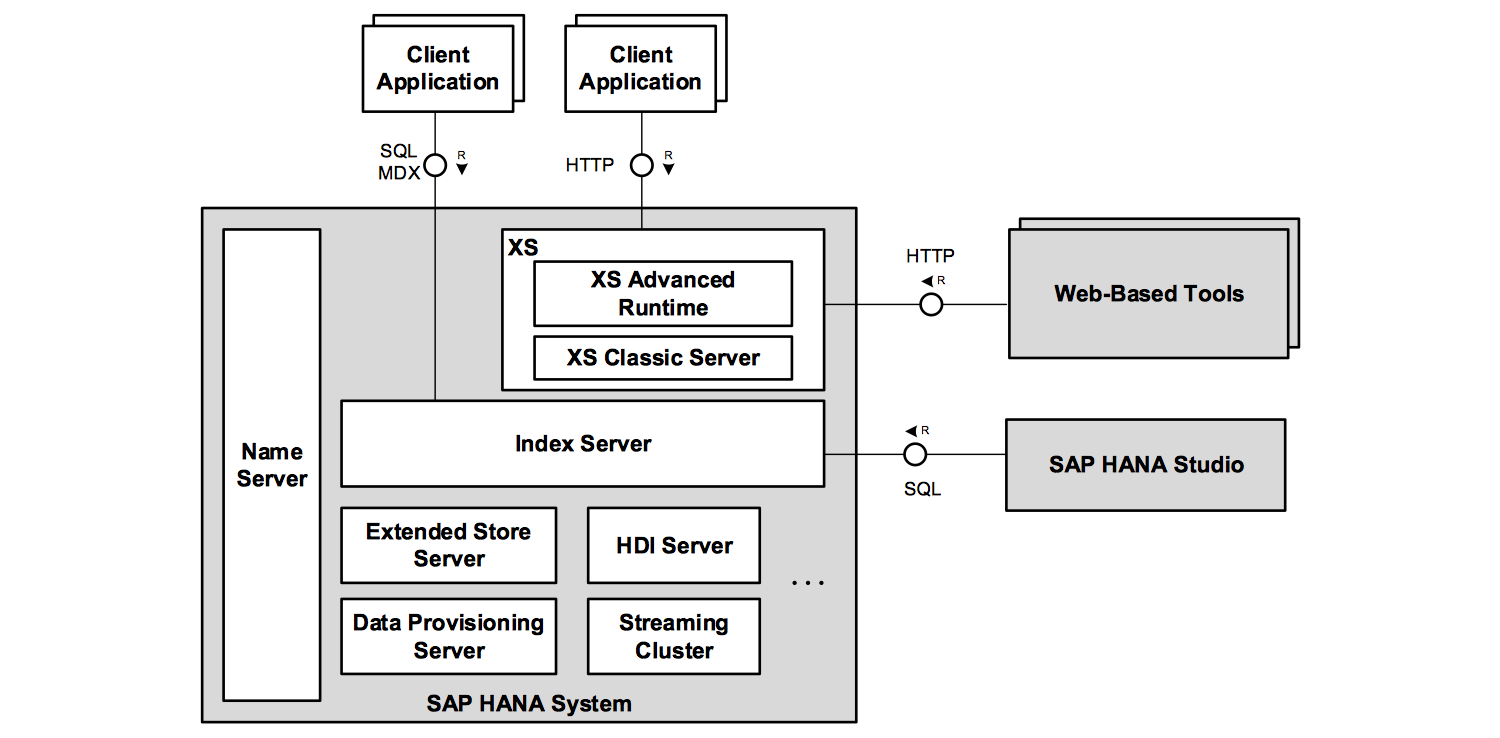
The most important component is the index server. The index server contains the in-memory data stores and the engines for processing the data.
The name server owns the information about the topology of an SAP HANA system. In a distributed system, the name server knows where the components are running, and which data is located on which server.
The XS runtime is the application server for native SAP HANA-based web applications. It is installed with the SAP HANA system and allows developers to write and run SAP HANA-based applications without the need to run an additional application server.
The extended store server is part of the dynamic tiering option. Less frequently accessed data, which you do not want to keep in main memory, can be put into the extended store. With dynamic tiering, SAP HANA can host very big databases with reduced cost of ownership.
The data provisioning server is part of Enterprise Information Management (EIM) in SAP HANA. It provides capabilities such as data provisioning in real time and batch mode, real-time data transformations, data quality functions.
The streaming cluster is part of the smart data streaming option. Smart data streaming extends SAP HANA with capabilities of SAP Event Stream Processor for consuming data streams and complex event processing.
The HDI server is a separate server process that is part of the HANA deployment infrastructure.
The SAP HANA server software is developed mainly in C++ and runs on the Linux operation system. The XS Advanced on-premise platform components are developed in Java.
SAP HANA Tools
Traditionally, the Eclipse-based SAP HANA Studio has been the development environment and administration tool for SAP HANA. The studio is superseded by web-based tools, which are grouped in the following three categories:
- Administration Tools
Web-based administration tools for SAP HANA are available in the SAPHANA Cockpit. The cockpit is an SAP Fiori launchpad site that integrates various tools for administration, monitoring, and software life-cycle management. - Development Tools
SAPWeb IDEfor SAP HANA is the browser-based development environment for SAP HANA-based application. It covers various aspects of development, such as editing, modeling, versioning, build, deployment, and debugging. It is based on XS Advanced and HDI and uses Git for source code management.
SAP Web IDE for SAP HANA supersedes the SAP HANAWeb Workbench, which can be used to develop SAP HANA-based applications for XS Classic. - Runtime Tools
The web-based SAP HANA runtime tools contain functions that are needed by both developers and administrators. Example are the SAP HANA database catalog browser, the SQL console and the Plan Visualizer for inspecting query execution plans.
Distributed SAP HANA Systems
SAP HANA supports distribution of its server components across multiple hosts – for example for scalability and availability.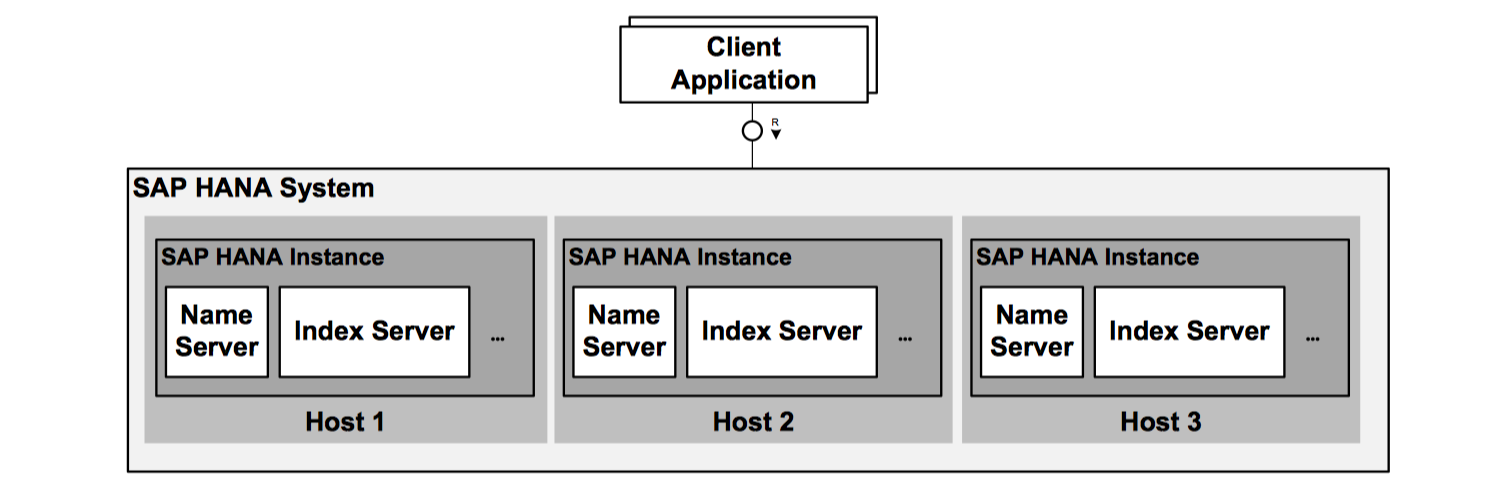
An installed SAP HANA system is identified by a System ID (SID). It is perceived as one unit from the perspective of the administrator, who can install, update, start up, shut down, or backup the system as a whole. The different components of the system share the same metadata, and requests from client applications are transparently dispatched to different servers in system, if required:
- A distributed SAP HANA
systemis installed on more than one host. Otherwise it is a single-host system. - A
hostis a machine which runs parts of the SAP HANA system. - A SAP HANA
instanceis the set of components of a distributed system that are installed on one host.
The streaming cluster nodes and the extended store servers run on their own dedicated hosts, at least in product systems. This means that you always need a distributed system if you run one of these options in production.
The Index Server
This section presents an overview of the architecture of the index server: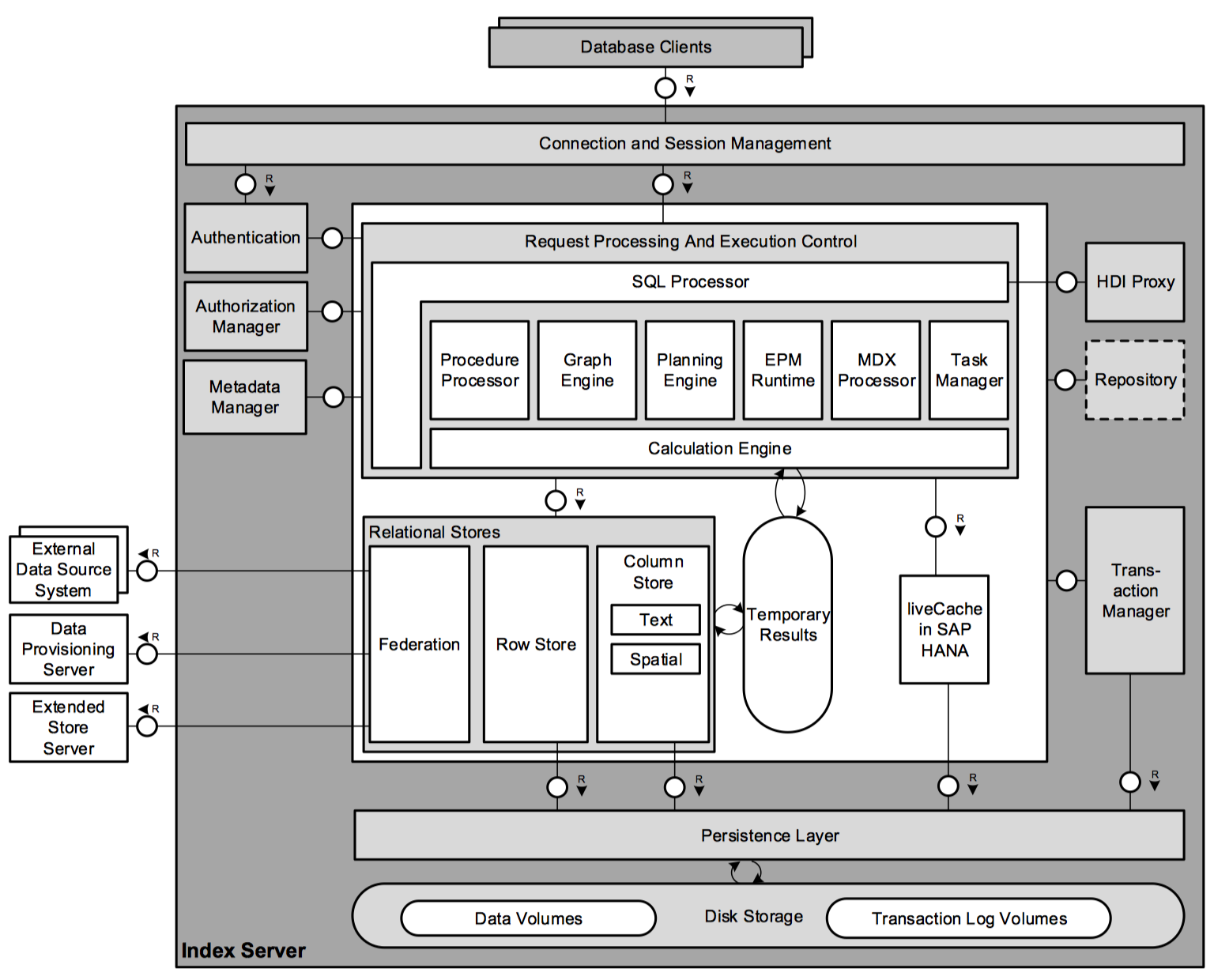
The Connection and Session Management component at the top creates and manages sessions and connections for the Database Clients. Once a session is established, database clients typically use SQL statements to communicate with the index server. Analytical applications may use MDX queries (MultiDimensional eXpressions). SQL statements and MDX queries are sent over the same connection using the same network communication protocol.
The Authentication component is invoked when a new connection is established. Users are authenticated either by the SAP HANA system itself or external provider. The Authorization Manager is invoked by other components to check whether the user has the required privileges to execute the requested operations.
Each statement is processed in the context of a transaction. The Transaction Manager is the component that coordinates transaction, controls transactional isolation, and keeps track of running and closed transactions. The transaction manager cooperates with the persistence layer to achieve atomic and durable transactions.
The client requests are analyzed and executed by the set of components summarized as Request Processing and Execution Control. SAP HANA offers rich programming capabilities for running application-specific calculations inside the database system. In addition to SQL and MDX, SAP HANA provides its own programming languages for different use cases.
Incoming SQL requests are received by the SQL Processor. Data manipulation statements are executed by the SQL processor itself. Other types of requests are delegated to the respective components:
- Data definition statements are dispatched to the metadata manager.
- Transaction control statements are forwarded to the transaction manager.
- Planning commands are routed to the planning engine.
- Task related commands are forwarded to the
Task Manager.
Incoming MDX requests are delegated to the MDX Processor. Procedure calls are forwarded to the Procedure Processor, which further dispatches the calls, for example to the calculation engine, the Graph Engine, the repository, or the HDI proxy. Procedures are also used to call liveCache functions.
The index server also contains a component called the Planning Engine that allows planning applications. It is mainly used for planning in SAP Business Warehouse (BW).
The SAP HANA Enterprise Performance Management (EPM) platform provides the infrastructure for developing and running enterprise performance management application on SAP HANA. The EPM Runtime is a central component of the EPM platform. While the planning engine provides basic planning operations, the EPM platform provides the foundation for complete planning application. It is usually invoked directly by an XS-based service.
While the planning engine is mainly used for planning in BW, the EPM platform addresses planning and simulation applications in general.
The SQL processor, the MDX processor, the planning engine and the task framework, translate the different programming languages, query languages, and models into common representation that is optimized and executed by the Calculation Engine.
Metadata can be accessed via Metadata Manager component. Metadata comprises a variety of objects, such as definitions of relational tables, columns, views, indexes and procedures. In distributed systems, central metadata is shared across servers.
The row store, column store, and the federation component are Relational Stores, which provide access to data organized in relational tables:
- The
Column Storestores relational tables column-wise. The column store also contains the text search and analysis capabilities, support for spatial data, and operators and storage for graph-structured data. - The
Row Storestores relational tables row-wise. When a table is created, the creator needs to specify whether it should be row or column-based. Tables can be migrated between the two storage formats. - The
Federationcomponent can be viewed as a virtual relational data store. It provides access to remote data in external systems through virtual tables, which can be used in SQL queries like normal tables. The data federation feature of SAP HANA is referred to as smart data access. The federation capabilities of smart data access are extended by Enterprise Information Management (EIM) in SAP HANA. - The SAP HANA database provides native support for storing and processing graph-structured data. However, technically it is not a separate physical data store. Instead it is built using the column store, which was extended with a dedicated graph API.
- SAP HANA includes an integration of SAP liveCache technology into the index server.
liveCache in SAP HANAis a non-relational, in-memory store with data represented as networks of C++ objects, which can be persisted to disk. Unlike the row store and column store, liveCache does not use relational tables. Instead the liveCache objects are directly stored in containers provided by the persistence layer.
The index server uses the federation infrastructure to send SQL statements to the extended store server.
The Persistence Layer is responsible for durability and atomicity of transactions. It ensures that the database is restored to the most recent committed state after a restart and that transactions are either completely executed or completely undone. To achieve this goal in an efficient way, the persistence layer uses a combination of write-ahead logs, shadow paging and savepoints. It also contains the logger component that manages the transaction log.
The HDI Proxy is a small component which forwards requests to the DI server, the main component of the HDI. HDI supersedes the classic SAP HANA Repository. In general the repository contains design-time representations, which need to be activated to create the corresponding runtime objects.