Introduction
This chapter presents the application developer’s view of SAP HANA. It gives an overview of both the programming languages for writing code that runs inside SAP HANA, and the client libraries used by client applications to connect to SAP HANA.
Database applications use well-defined interfaces to communicate with the database management system functioning as a data source, usually over a network connection.
The application, often running in the context of an application server, takes the role of a client, while the database system plays the role of a server. Client applications typically use vendor-supplied client libraries which implement part of the API and encapsulates the communication details.
The leading programming language for database application is the SQL. SQL provides functional capabilities for creating, accessing, maintaining, controlling, and protecting relational data.
SAP HANA greatly extends SQL. This includes SAP HANA-specific SQL statements, views, data types, and the possibility to write Procedures in several languages, such as SQLScript, L, C++ and R.Modeled Views are design-time abstractions that allow developers to work efficiently with SAP HANA’s extended views on a higher level of abstraction.
An alternative query language for clients is MDX. Pioneered by Microsoft, MDX is used by applications to query OLAP (OnLine Analytical Processing) data models. Applications can query graph data with the openCypher query language and implement custom graph algorithms as graph stored procedures.
Traditionally, the client application is written in a high-level language such as ABAP, Java or C++, has to build its own high-level data models. The involved data then needs to be sent back and forth across the SQL interface, often introducing significant inefficiencies. Another well-recognized complexity that application developers face is that these data models cannot easily be shared by different technology stacks, leading to duplication and re-engineering. Toady, SAP HANA helps to overcome these difficulties in 3 ways:
- SAP HANA allows developers to create application-specific procedures and models that are executed within the index server, with fast access to the in-memory data. This way, in-memory technology can be used and the data transfer with the client can be minimized as well.
- Developers can use XS to provide service APIs, data and resources to HTTP clients, without the need of an additional application server.
- SAP HANA has been enhanced with a new abstraction layer, called
Core Data Services(CDS). The CDS allow application developers to create data models on a high level of abstraction. These models can then be reused from different application development environments.
It shows most elements of the SAP HANA programming model and their relationships: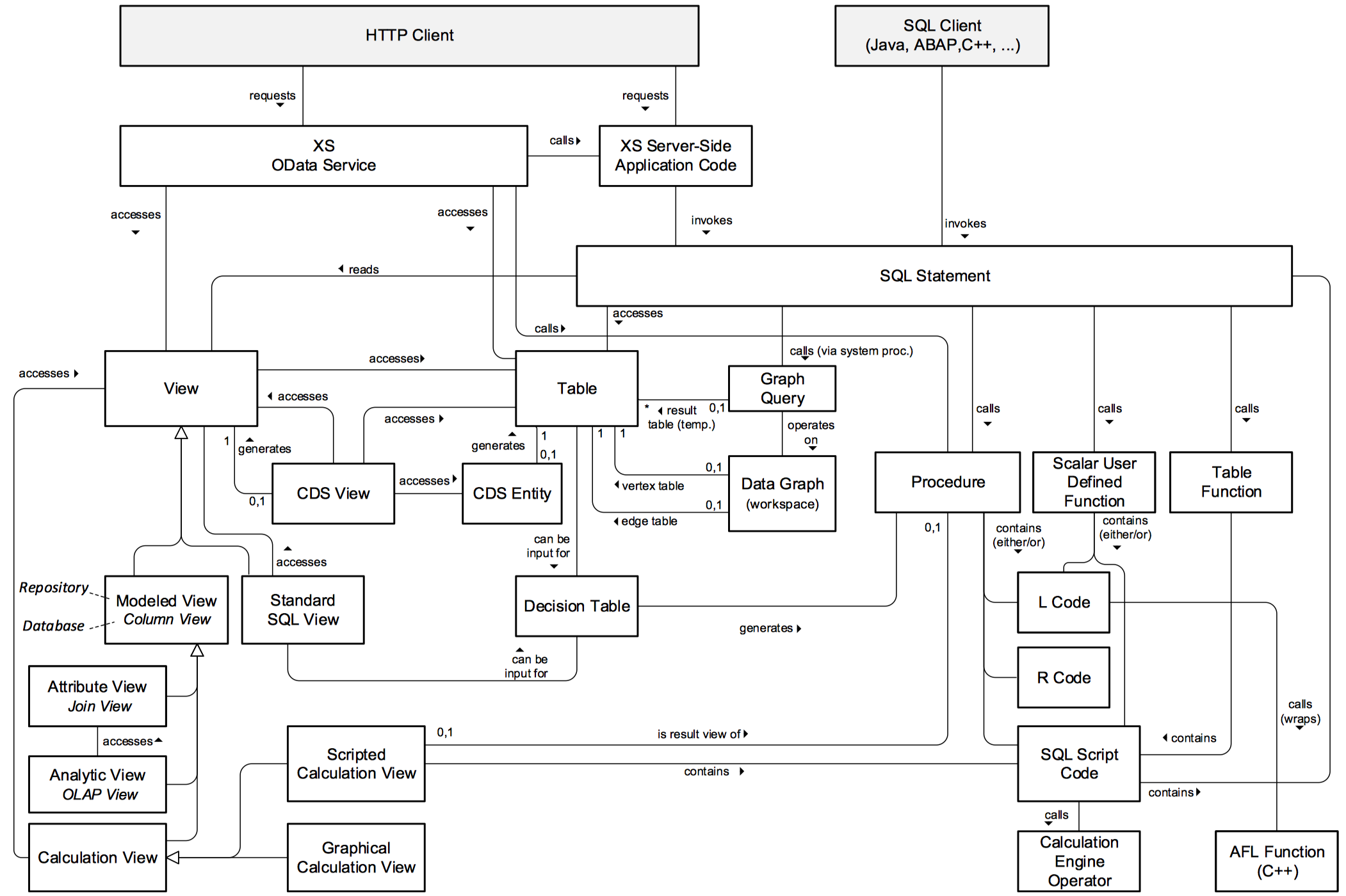
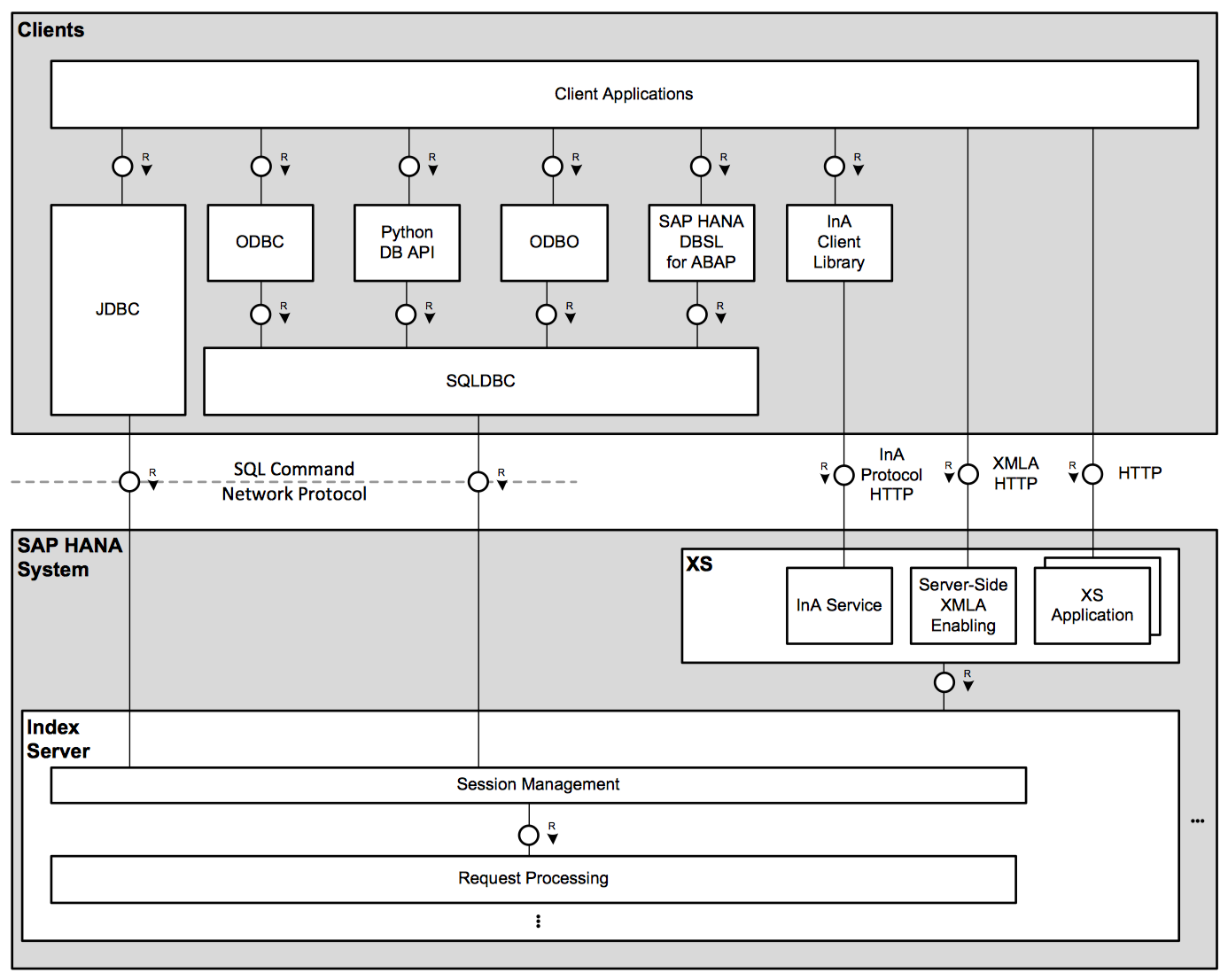
Clients
SAP HANA supports clients using the following development environments and interfaces:
- Client applications written in C/C++, which use the
ODBC(Open DataBase Connectivity) interface. - Client applications written in Java, which use the
JDBC(Java DataBase Connectivity) interface. - Client applications written in Python, which use the
Python Database API. - Windows-based client applications that use the
ODBO(Object linking and embedding DataBase for Online analytical processing) interface for MDX. - MDX clients using
XMLA(XML for Analysis) over HTTP. - ABAP applications using
DBSL(DataBase Shared Library) to connect to the SAP HANA system. - XS applications can execute SQL statements using a database API provided by the
XSserver. - The
InA(InformationAccess) infrastructure provides a client API, which combines analytical queries, search and planning. It connects to the InA service in the backend via HTTP using an InA-specific internal protocol.
ODBC is a standard, implementation-agnostic C-based API for accessing a database. Analogously, JDBC is a data access API for Java, and the Python Database API is the data access interface for Python. All three interfaces provide methods for creating and maintaining connections, as well as transactions, and other mechanisms for querying and updating data in a database, which map directly to underlying SQL semantics, hiding the actual communication details.
ODBO is a Microsoft specification and an industry standard for multi-dimensional data processing. The ODBO API is used by applications that use the MDX query language to access multi-dimensional data in SAP HANA. As alternative to ODBO, MDX clients can use XMLA which exposes a similar interface as a SOAP (Simple Object Access Protocol) web service over HTTP. On the server side, the XMLA interface is provided by an application that runs in the XS server.
SQL
The SAP HANA SQL implementation is based on the P*TIME (ParallelTransact-In-Memory Engine) SQL dialect which implements SQL 92 entry level and some features of SQL 99. SAP HANA *offers several SQL extensions** on top of this standard, for example:
- SQL extensions for creating tables as row-based or column-based and for conversion between both storage formats. Row-based tables can be converted into columnar tables and vice versa.
- Support for managing columnar in-memory tables. One example is the
MERGE DELTAstatement for merging the delta and the main part of a column-based table. Other examples are theLOADandUNLOADstatements for explicitly loading and unloading table to memory. - SAP HANA supports a number of extended SQL views.
Join viewsare parameterized join-based views on columnar tables.OLAP viewscontain metadata for querying data cubes stored in column-based tables.Calculation viewsexpose results calculated by a procedure or based on a data flow graph.Hierarchy viewssupport querying and navigating hierarchical data in column-based tables in an efficient way. - An extended
PROCEDUREspecification, allowing the development of embedded procedures using multiple technologies and programming languages. - Support for defining and querying history tables.
- Support for full text search on database tables and views.
- Support for spatial data.
- Support for accessing remote data sources via virtual tables.
- Flexible tables, which can be dynamically extended with new columns when data is inserted or updated, without the need to explicitly call SQL data definition statements.
- Extensions to support the planning engine, which provides planning commands that are invoked by planning applications.
For most SQL statement it is syntactically irrelevant whether the table is column-based or row-based.
Modeled Views
Modeled views are design-time definitions, created by application developers with specific modeling tools. The actual database objects are generated from these definitions during deployment via HDI or during activation, if the classic repository is used.
There are several reasons why developers use modeled views:
- They support structured and modular abstractions.
- Using modeling tools is more convenient than writing complex statements in pure SQL.
- Additional semantics can be provided, such as description texts for attributes, hierarchies, variables and parameters.
- Modeled views generate additional metadata at deploy-time, which enable access to the views for MDX clients and for generic Business Intelligence (BI).
- Values of columns in the resulting database objects can be calculated using formulas.
Calculation Views
Calculation views can be used for defining advanced slices on the data available in the SAP HANA database, based on complex calculations. The data foundation of the calculation view can include any combination of various sources such as tables, views of different types, table functions and virtual tables for accessing remote data. The logic of a calculation view can be programmed in SQLScript or you can use a visual view editor to create the data flow graph for the view.
Traditionally Used Modeled View types
Attribute views are created on data from column store tables, using projection and join operations. They were traditionally used to represent the master data dimensions in a star schema, and they also support the definition of hierarchies. Analytic views are created on column tables and attribute views. They were traditionally used to define star schemas, linking the central fact table to the dimensions.
In the SAP HANA studio, the traditional view types are still supported.
Modeled Views and Column Views
It is important to understand the difference between modeled views and the corresponding database objects that are generated at run-time. The modeled views are design-time artifacts. To create the actual database objects, the modeled views need to deployed (when HDI is used) or activated (if the classic repository is used). For calculation views, the main database object is a column view of type CALCULATION. For attribute views, it is a column view of type JOIN. For analytic views a column view of type OLAP is created.
Procedures
An important SAP HANA SQL feature is its specification of database procedures (also known as stored procedures). The CREATE PROCEDURE statement supports the specification of the procedure body using several technologies and programming languages. These procedures run directly in the database layer, thus benefiting from the performance improvement of the SAP HANA algorithms and eliminating large amounts of data transfers from the database to the application.
| Procedure Language | Comments |
|---|---|
| SQLScript | SQLScript is used to write procedural orchestration logic, to define complex data flows and to write user-defined scalar functions. |
| L | L is an imperative programming language, derived from C++, for implementing embedded code. L programs are compiled to native code, and thus very efficient. |
| C++ | Application Function Libraries (AFLs) can be written in C++ to develop performance critical code. One example of AFLs is the Predictive Analytics Library (PAL). |
| R | R is an open-source programming language and software environment for statistical computing and graphics. |
Note that programming in L or C++ is not released for customers.
SQLScript
SAP HANA provides SQLScript as the default programming language for writing embedded orchestration and data flow logic, in the form of embedded procedures.
SQLScript has table variables that can contain internal tables, which can be seen as temporary tables inside the index server. Table variables need not be declared, their structure is automatically determined by the compiler from the type of the assigned values.
In SQLScript, the data types of procedure parameters need to be declared. A table type defines the names and the types of columns without creating a table on the database.
A SQLScript procedure may contain SQL statements, call other procedures, and uses if/else statements or loops for control flow. Cursors can be used to iterate through result sets. With support for loops and cursors, SQLScript procedures can process data row-by-row. However, procedures that follow the row-oriented processing model are hard to parallelize and optimize.
Programmers are encouraged to process mass data using read-only procedures with declarative table operators.
Calculation Engine Operators
SQLScript procedures may directly call the intrinsic operators of the calculation engine. Using intrinsic calculation engine operators can result in higher performance in some cases and therefore be used for fine-tuning the execution of a procedure. Calculation engine operators of the following categories are available:
- Operators for binding tables or views to table variables.
- Relational operators such as join, union, projection and aggregation.
- Expressions with mathematical operations, string operations and date/time operations.
- Implementation of business logic such as currency conversion.
While these operators are implemented inside the calculation engine, in some cases the operator implementation just forwards the execution to the column store.
The calculation engine operators and the corresponding SQL statement are implemented differently and sometimes even have different semantics.
Mixing SQL queries and calculation engine operators in the same procedure is not recommended for performance reasons.
Read-Only Procedures
Read-only procedures must not contain any statements that modify the database and they may only call other read-only procedures. As read-only procedures are guaranteed to be free of side effects, they can be better optimized and execution can be better parallelized.
The code sample below shows a simple read-only procedure:
1 | CREATE TYPE TT_TAB1 AS TABLE ("A" INTEGER, "B" INTEGER); |
Table Functions
SQLScript is also used to write table functions. A table function contains read-only SQLScript code and returns a single table as its result value. The function call can be used instead of a table or view in SQL queries.
In the following example a table function FUNC1 is used as the data source for a select operation:
1 | SELECT col1, col2 FROM FUNC1(5, 'AB') WHERE col1 > 3000; |
Table functions make it possible to call complex logic from client tools that can only invoke queries and which cannot call procedures.
Scalar SQLScript Functions
With SQLScript you can also write user-defined functions that return one or more scalar values. Like the built-in SQL functions they can be used in projection lists, group-by clauses and where conditions.
The code sample shows the definition of a scalar function F1, which returns two scalar values Y1 and Y2:
1 | CREATE FUNCTION F1 (X1 DOUBLE, X2 DOUBLE) |
In the following example the function F1 is called twice, in the projection list and in the WHERE condition:
1 | SELECT A, F1(A, B).Y1 FROM T1 |
Currently, scalar functions do not support table-valued parameters and they cannot contain operations on database tables.
L
L is a language designed by SAP for executing procedural code in SAP HANA. One purpose of L is to serve as an internal common intermediate language for other SAP HANA languages. SQLScript procedures and FOX formula code are internally compiled into L.
L can be roughly described as a safe subset of C++ with support for the SAP HANA data types. Unlike C++, L does not contain unsafe language elements (e.g. pointers) that may crash the server process.
L programs consist of a set of type definitions, variables and functions:
- For control flow, the L language provides if/else clauses and loops.
- Exception handling with try/catch is also supported.
- L comes with a math library with common mathematical functions and matrix operations.
L programs are compiled at runtime. Using L for the wrong tasks may cause performance issues, L programs are executed sequentially. If procedural code is required, SQLScript should be the first choice.
User-defined scalar functions can also be written in L. However, the SQLScript is the preferred choice.
L Procedures
Writing procedures in L is useful when application logic cannot be expressed with SQL or SQLScript, and for accessing internal data structures that are not exposed in SQLScript.
Procedures written in L cannot contain SQL statements. Tables can only be accessed via table typed input and output parameters.
C++ (AFL)
- A typical use case is to develop application-specific C++ functions that can be called from L code, for example from a procedure written in L.
- Another use case is extending the calculation engine by writing custom operations in L which can call the C++ function.
Application logic written in C++ can be executed within SAP HANA by creating an Application Function Library (AFL).
- The main reason for writing business logic in C++ is performance.
- Another reason may be the need to use internal interfaces that are not available otherwise.
However, using C++ also means that programming errors in the application code affect the stability and availability of the whole server. It needs to be carefully examined, whether using C++ is really required and writing application logic in C++ is restricted to privileged developers.
R
R is an open-source programming language and software environment for statistical computing and graphs. With over 4,000 add-on packages, R provides a wide range of library functions. It provides roughly the same functions as the combination of the most successful commercial packages, SAS and SPSS.
SAP HANA provides interoperability with the R runtime environment, via a tight component integration, and support for functions written in R, which are encapsulated by a regular embedded procedure interface. Table parameters can be passed to R code, and a result is returned in the form of tables:
1 | -- prepare tables |
MDX
MDX syntactically resembles SQL, but it incorporates concepts like cube, dimensions, hierarchies and measures, and can be used to connect a variety of analytics applications including SAP Business Objects BI tools and Microsoft Excel.
The following is an example of an MDX query:
1 | SELECT { |
MDX includes a rich set of functions for statistical analysis, but unlike SQL, MDX has limited DDL or DML capabilities. MDX cubes are defined in SAP HANA by creating calculation views.
The current MDX implementation in SAP HANA covers most parts of the MDX specification, and includes additional SAP-specific extensions.
Decision Tables
SAP HANA supports decision tables as an intuitive design-time representation of business rules. At runtime, the business rules are executed as database procedures for best performance. From the decision table model, a SQLScript procedure with result view is generated for execution.
Declarative OData Provisioning in XS
XS application programmers can define OData (Open Data protocol) data access services without programming. OData is a resource-based web protocol for querying and updating data. OData defines operations on resources using HTTP verbs, and specifies the URI syntax for identifying the resources. OData defines a set of query parameters, which allow clients to influence the result set.
To create an OData service, XS developers just have to create an OData service descriptor file. These declarations are evaluated by a generic OData provider component of the XS platform to provide the services at runtime.
Server-Side Application Code in XS
Developers of XS Classic applications can write server-side logic in JavaScript. This is server-side JavaScript, augmented to support connections to the SAP HANA database and the SAP HANA data types.
Ths server part of XS Advanced applications can be written in Java, or in JavaScript on Node.js. In addition, a XS Classic compatibility layer is provided, which was developed for executing existing XS Classic JavaScript code with as few migration efforts as possible.
Core Data Services (CDS)
Introducing CDS
Application programs implement their own domain-specific models and access logic on top of the SQL standard API, but the implementation-specific information cannot be shared across technology stacks, programming languages, and application frameworks. To address this, HANA has introduced the Core Data Services (CDS), an infrastructure for defining and consuming semantically enriched data models. These CDS can be consumed by applications written in different languages, such as ABAP, Java and others.
The CDS comprise a family of programming specifications:
- Schema Definition Language (SDL) for defining semantically enriched domain data models. The SDL allows developers to define persisted entities that are similar to tables but have some additional features. SDL also supports the definition of views and reusable structured types. CDS annotations allow for enriching data models with additional metadata.
- Query Language (QL) for conveniently and efficiently reading data. The QL extends the SQL
SELECTstatement by allowing a path-like syntax for identifying associated entities that is much easier to use than an equivalentJOINstatement in SQL. QL can be used in SDL view definitions. - Expression Language (EL) for specifying calculated fields, default values, constraints, etc. with queries as well as for elements in data models.
- Data Control Language (DCL) for defining the application’s authorization model. The DCL supports
static privilegesandpredicated privileges.- Static privileges control access to an entire resource, e.g. a CDS view, in an all or nothing fashion.
- Predicated privileges allow for dynamic access control, based on the values of the attributes of entity instances.
The CDS focus on providing functional services independent of any programming language and language paradigms.
CDS Support in SAP HANA
CDS support in SAP HANA allows application developers to define the data models by creating CDS design-time files that contain CDS definitions. CDS can be used to define various aspects of an application such as persisted data model, views, analytical models, search models, and the authorization models. SAP HANA internally transforms the CDS definitions to the existing mechanisms for data definition, to SQL, to database privileges, to calculation models executed by the calculation engine, or to L programs.
The SQL CREATE TABLE statement now supports the definition of CDS associations, and in SQL queries you can navigate such associations with path expressions. The following code snippets from illustrate this feature.
SQL data definition with CDS association:
1
2
3
4
5CREATE TABLE Employees (
id, name, ..., homeAddress_id INTEGER
) WITH ASSOCIATIONS (
JOIN Address AS homeAddress ON homeAddress.id = homeAddress_id;
)SQL query with CDS infix filters and path expressions along association:
1
2SELECT name, address[kind='business'].town.country.name
FROM Employees;