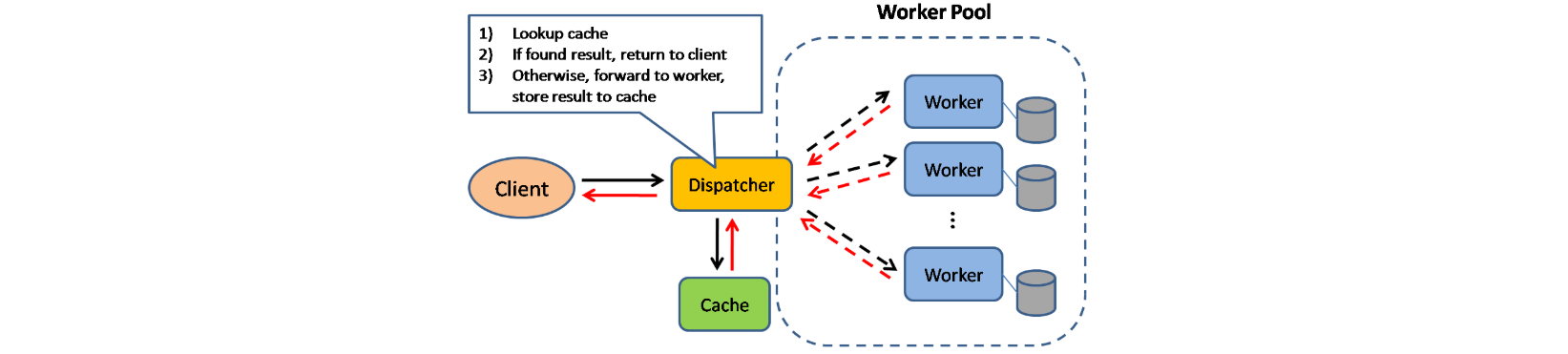
Cache 可以提高页面加载速度,并可以减少服务器和数据库的负载。在这个模型中,Dispatcher 先查看请求之前是否被响应过,如果有则将之前的结果直接返回,来省去真正的处理。
数据库因分区(Partition)读写而获益,但是热数据会导致读写不均,造成瓶颈。如果在数据库前加个缓存,就会减轻不均匀的负载和突发流量对数据库的影响。
客户端缓存
缓存可以位于客户端(OS or Browser)、服务端或不同的缓存层。
CDN 缓存
CDN 也被视为一种缓存。
Web 服务器缓存
Reverse Proxy 和缓存(例如,Varnish)可以直接提供静态和动态内容。Web 服务器同样也可以缓存请求,返回响应结果而不必联络应用服务器。
数据库缓存
数据库的默认配置中通常包含缓存级别,针对一般用例进行了优化。针对特定的使用模式调整配置,可以进一步提高性能。
应用缓存
基于内存的缓存,例如:Memcached 和 Redis,是应用程序和数据存储之间的一种 key-value 存储。由于数据保存在 RAM 中,它比存储在磁盘上的传统数据库要快多了。RAM 比磁盘限制更多,所以缓存无效算法(例如,LRU)可以将热数据留存在 RAM 中。
Redis 有下列附加功能:
- 持久化选项;
- 内置数据结构,例如:有序集合和列表;
有多个缓存级别,分为两大类:数据库查询和对象:
- 行级别;
- 查询级别;
- 完整的可序列化对象;
- 完全渲染的 HTML;
一般来说,应该尽量避免基于文件的缓存,因为会使得复制和自动缩放变得更困难。
数据库查询级别的缓存
无论何时查询数据库,将查询语句的 hash 值和查询结果存储到缓存中,这种方法会遇到以下问题:
- 很难删除复杂查询语句的缓存结果;
- 如果一条数据(例如,表中的一项)改变了,则需要删除所有可能包含已更改项的缓存结果;
对象级别的缓存
将数据视为对象,像编写应用代码一样:让应用程序将数据从数据库中,组合到类实例或数据结构中:
- 如果对象的基础数据已更改,那么从缓存中删除这个对象;
- 允许异步处理:使用最新的缓存组装对象;
建议缓存的内容:
- 活动流;
- 用户会话;
- 用户图数据;
- 完全渲染的 Web 界面;
何时更新缓存
由于你只能在缓存中存储有限的数据,所以你需要选择一个适用于用例的缓存更新策略。
缓存模式(Cache-Aside)
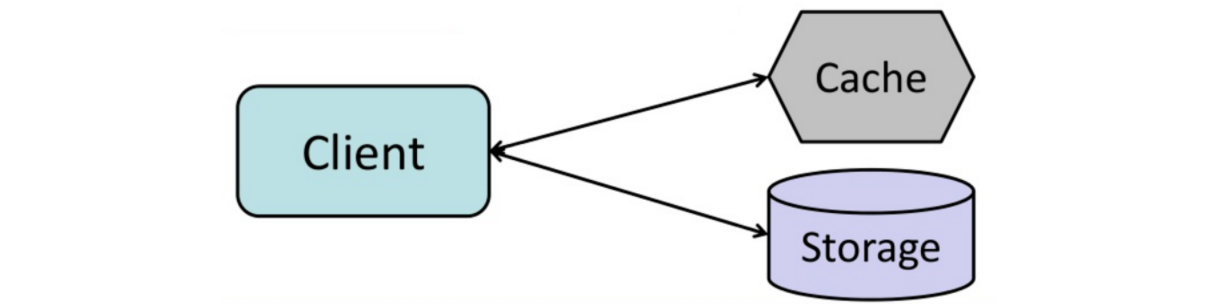
应用从外存读写,缓存不和外存直接交互,应用执行以下操作:
- 在缓存中查找记录,如果所需数据不在缓存中;
- 从数据库中加载所需内容;
- 将查找到的结果存储到缓存中;
- 返回所需内容;
1 | def get_user(self, user_id): |
Memcached 通常用这种方式使用。
添加到缓存中的数据读取速度很快,缓存模式也称为延迟加载,只缓存所请求的数据。这避免了没有被请求的数据占满缓存空间。
缺陷:缓存模式
- 请求的数据如果不在缓存中,需要经过 3 个步骤来获取数据,会导致明显的延迟;
- 如果数据库中的数据更新,会导致缓存中的数据过时。需要设置 TTL(Time To Live)强制更新缓存,或者采用直写模式缓解这种情况;
- 当一个节点出现故障时,它会被一个新节点替代,这增加了延迟时间;
直写模式(Write-Through)
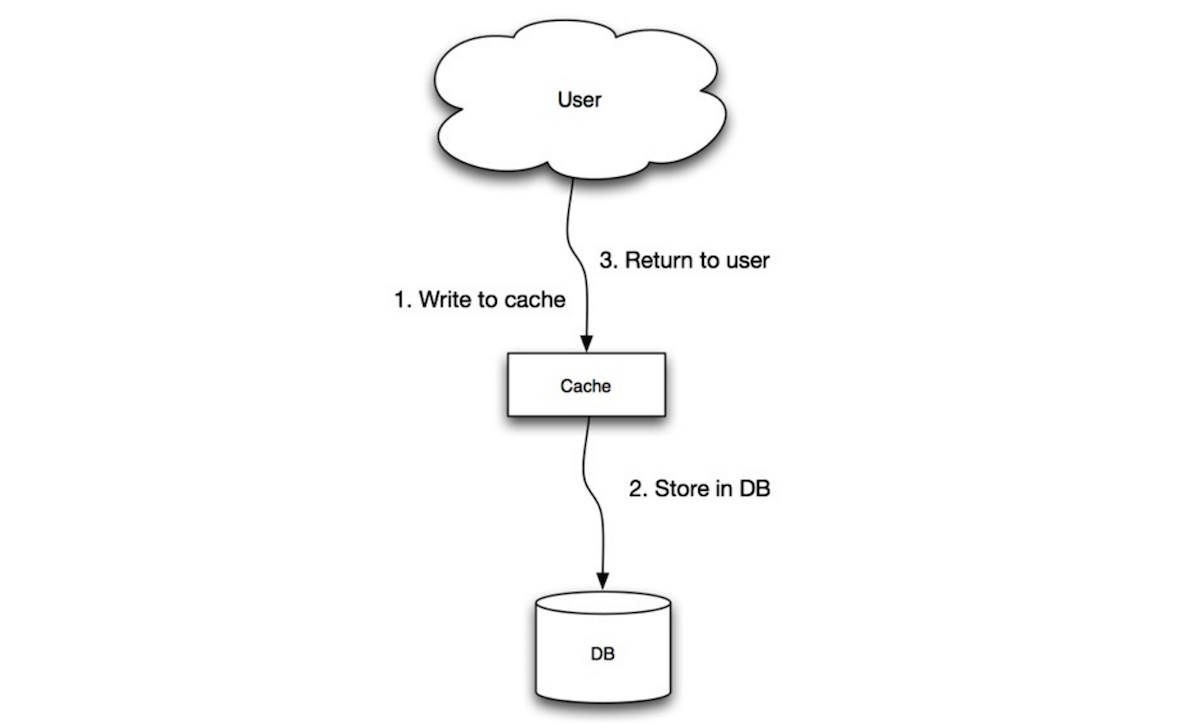
应用使用缓存作为主要的存储单元,将数据读写到缓存中,而缓存负责从数据库读写数据:
- 应用向缓存中添加/更新数据;
- 缓存同步写入并存储数据;
- 返回所需内容;
应用代码:
1 | set_user(1234, {"foo":"bar"}) |
缓存代码:
1 | def set_user(user_id, values): |
由于写入操作,直写模式整体是一种很慢的操作,但读取刚写入的数据很快。相比读取数据,用户通常比较能接受更新数据时速度较慢;缓存中的数据不会过时。
缺陷:直写模式
- 由于故障或缩放创建的新节点不会有缓存,直到数据库更新。缓存模式 + 直写模式可以缓解这个问题;
- 写入的大多数数据可能永远不会被读取,使用 TTL 可以最小化这类问题;
回写模式(Write-Behind)
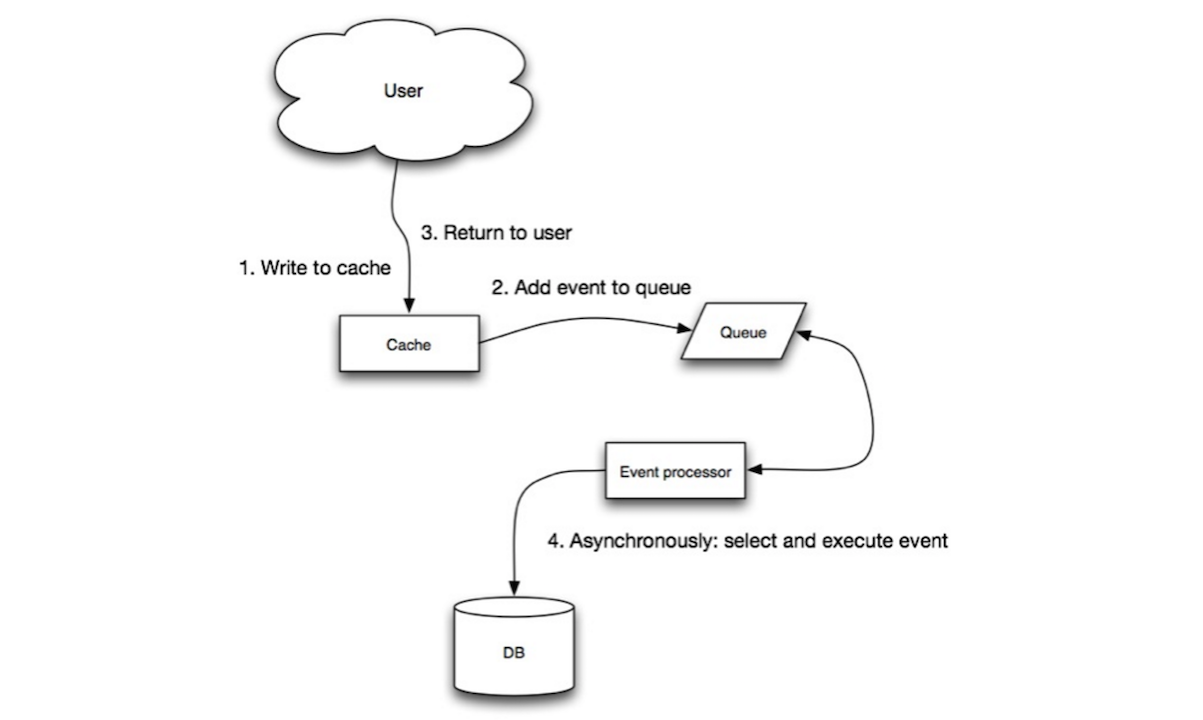
在回写模式中,应用执行以下操作:
- 在缓存中增加或更新数据;
- 异步写入数据,提高写入性能;
缺陷:回写模式
- 数据可能在其内容成功存储之前丢失;
- 实现回写模式比缓存模式、直写模式更复杂;
刷新模式(Refresh-Ahead)

你可以将缓存配置成,在到期之前自动刷新最近访问过的内容。
缺陷:刷新模式
- 不能准确预测未来需要用到的数据,可能会导致性能不如不使用刷新;
缺陷:缓存
- 需要维护缓存和真实数据源之间的一致性,通过
cache replacement policies; cache invalidation以及何时更新缓存是一个复杂的问题;- 需要改变应用程序,比如增加 Redis 或 Memcached;