异步(Asynchronism)

异步工作流有助于减少那些原本顺序执行的请求时间。它们可以通过提前进行一些耗时的工作来帮助减少请求时间,比如定期汇总数据。
消息队列
消息队列接收、保留和传递消息。如果按顺序执行操作太慢的话,你可以使用有以下工作流的消息队列:
- 应用程序将作业发布到队列,然后通知用户作业状态;
- 一个 worker 从队列中取出该作业,对其进行处理,然后显示该作业完成;
不去阻塞用户操作,作业在后台处理。在此期间,客户端可能会进行一些处理使得任务看上去像是已经完成了。例如,如果要发送一条推文,推文可能会马上出现在你的时间线上,但是可能需要一些时间才能将你的推文推送到你的所有关注者那里去。
Redis 是一个令人满意的简单的消息代理,但是消息有可能会丢失。
RabbitMQ 很受欢迎但是要求你适应 AMQP 协议,并且管理你自己的节点。
Amazon SQS 是被托管的,但可能具有高延迟,并且消息可能会被传送两次。
任务队列
任务队列接收任务及其相关数据,运行它们,然后传递其结果。它们可以支持调度,并可用于在后台运行计算密集型作业。
Celery 支持调度,主要是用 Python 开发的。
背压
如果队列开始明显增长,那么队列大小可能会超过内存大小,导致 Cache 未命中,磁盘读取,甚至性能更慢。Back Pressure 可以通过限制队列大小来帮助我们,从而为队列中的作业保持高吞吐率和良好的响应时间。
一旦队列填满,客户端将得到服务器忙或者 HTTP 503 状态码,以便稍后重试。客户端可以在稍后时间重试该请求,也许是指数退避。
缺陷:异步
简单的计算和实时工作流等场景可能更适用于同步操作,因为引入队列可能会增加延迟和复杂性。
通讯
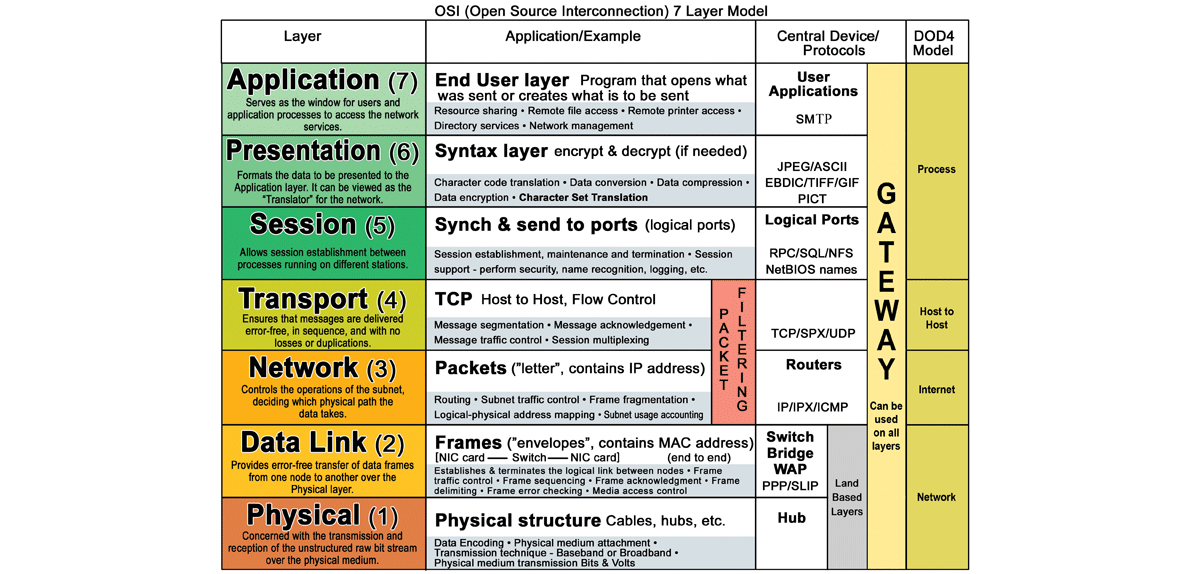
超文本传输协议(HTTP)
HTTP 是一种在客户端和服务器之间编码和传输数据的方法。它是一个 request/response 协议:客户端和服务端针对相关内容和完成状态信息的请求和响应。
HTTP 是独立的,允许请求和响应流经许多执行负载均衡、缓存、加密和压缩的中间路由器和服务器。
一个基本的 HTTP 请求由一个动词(method)和一个资源(endpoint)组成。 以下是常见的 HTTP 动词:
| 动词 | 描述 | 幂等 | 安全性 | 可缓存 |
|---|---|---|---|---|
| GET | 读取资源 | Yes | Yes | Yes |
| POST | 创建资源或触发处理数据的进程 | No | No | Yes,如果 response 包含刷新信息 |
| PUT | 创建或替换资源 | Yes | No | No |
| PATCH | 部分更新资源 | No | No | Yes,如果 response 包含刷新信息 |
| DELETE | 删除资源 | Yes | No | No |
HTTP 是依赖于较低级协议(例如,TCP 和 UDP)的应用层协议。
传输控制协议(TCP)

TCP 是 IP(Internet Protocol)网络上的面向连接协议。 使用握手建立和断开连接。 发送的所有数据包保证以原始顺序到达目的地,用以下措施保证数据包不被损坏:
- 每个数据包的序列号和校验码(checksum);
- 确认包和自动重传;
如果发送者没有收到正确的响应,它将重新发送数据包。如果多次超时,连接就会断开。TCP 实行流量控制和拥塞控制。这些确保措施会导致延迟,而且通常导致传输效率比 UDP 低。
为了确保高吞吐量,Web 服务器需要保持大量的 TCP 连接,这样会导致高的内存使用。在 Web 服务器线程间,拥有大量的开放连接开销巨大,连接池可以帮助在适当的情况下切换到 UDP。
TCP 对于高可靠性、低实时性的应用很有用。例如,Web 服务器、数据库信息、SMTP、FTP 和 SSH。
以下情况使用 TCP 代替 UDP:
- 你需要数据完好无损;
- 你想对网络吞吐量自动进行最佳评估;
用户数据报协议(UDP)

UDP 是无连接的。数据报(Datagram)类似于数据包(Packet),只在数据报级别有保证。数据报可能会无序地到达,也有可能会丢失,UDP 不支持拥塞控制。虽然不如 TCP 那样有保证,但 UDP 通常效率更高。
UDP 可以通过广播将数据报发送至子网内的所有设备。这对 DHCP 很有用,因为子网内的设备还没有分配 IP 地址,而 IP 地址对于 TCP 是必须的。
UDP 可靠性更低,但适合网络电话、视频聊天、流媒体和实时多人游戏上。
以下情况使用 UDP 代替 TCP:
- 相对于数据丢失,更糟的是数据延迟;
- 你想实现自己的错误校正方法;
远程过程调用(RPC)
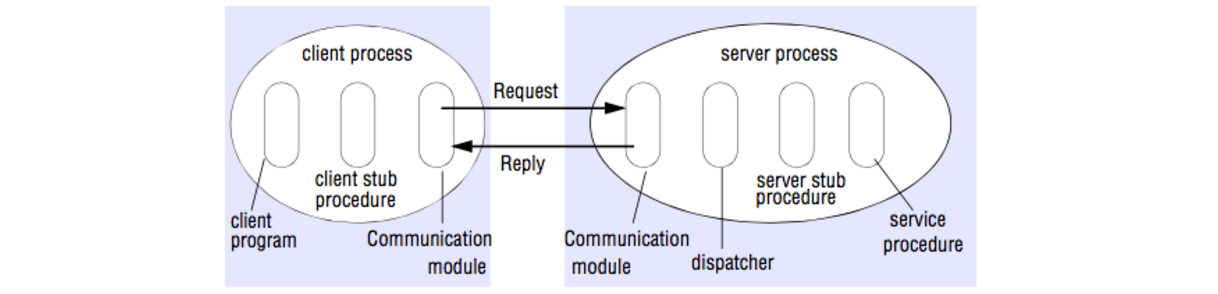
在 RPC 中,客户端会调用另一个地址空间(通常是远程服务器)里的过程。客户端和服务器交互的具体过程被抽象,看起来就像是本地调用。
远程调用相对于本地调用,一般较慢而且可靠性较差,很容易区分两者。热门的 RPC 框架包括:Protobuf、Thrift 和 Avro。
RPC 是一个 request/response 协议(客户端的响应与之相反):
- 客户端程序:调用客户端 stub 过程,就像调用本地过程一样,参数会被压入栈中;
- 客户端 stub 程序:将过程的 id 和参数打包进请求信息中;
- 客户端通信模块:将信息从客户端发送至服务端;
- 服务端通信模块:将接收的 packets 传给服务端 stub 程序;
- 服务端 stub 程序:将结果解包,依据过程 id 调用服务端程序,并将参数传传入;
RPC 调用示例:
1 | GET /someOperation?data=anID |
RPC 专注于暴露行为。RPC 通常用于处理内部通讯的性能问题,这样你可以手动处理本地调用,以更好地适应你的需求。
当以下情况时选择本地库(AKA SDK):
- 你知道你的目标平台;
- 你想控制如何访问你的“逻辑”;
- 你想对发生在你的库中的错误进行控制;
- 性能和终端用户体验是你最关心的事;
缺陷:RPC
- RPC 客户端与服务实现捆绑得很紧密;
- 一个新的 API 必须在每一个操作或者用例中定义;
- RPC 很难调试;
- 你可能没办法很方便地去修改现有的技术。例如,如果你希望在
Squid这样的缓存服务器上,确保 RPC 被正确缓存的话,可能需要一些额外的努力;
表述性状态转移(REST)
REST 是一种强制的 client/server 架构设计模型,client 基于 server 管理的一系列资源进行操作。server 提供修改或获取资源的接口,所有的通信必须是无状态和可缓存的。
RESTful 接口有四条特征:
- 标志资源(URI):无论什么操作,都使用同一个 URI;
- 带有表述的改变(Verbs):使用动词、header 和 body;
- 可自我描述的错误信息(Status Code):使用状态码,不要重复造轮子;
- HATEOAS(Hypertext As The Engine Of Application State):你的 server 应该能够通过浏览器访问;
REST 调用示例:
1 | GET /someResources/anID |
REST 专注于暴露数据。它减少了 client/server 的耦合程度,经常用于设计公共 HTTP APIs。REST 使用更普遍和规范化的方法,借助 URIs 暴露资源,使用 header 来表述,并通过动词进行操作。由于无状态的特性,REST 易于水平扩展和分区。
缺陷:REST
- 由于 REST 将重点放在暴露数据,所以当资源不是自然组织或结构复杂的时候,它可能无法很好地适应。例如,返回过去 1 小时中与特定事件集匹配的更新记录,这种操作就很难表示为路径。使用 REST,可能会结合 URI 路径、查询参数和可能的请求体;
- REST 一般依赖几个动词,但有时候它们无法满足你的需求。例如,将过期的文档移动到归档文件夹里去,这样的操作可能没法简单地几个动词来表述;
- 为了渲染单个页面,获取被嵌套在层级结构中的复杂资源,需要 client、server 之间多次往返通信。例如,获取博客内容及关联评论,对于使用不确定网络环境的移动应用来说,这些多次往返通信是非常麻烦的;
- 随着时间的推移,更多的字段可能会被添加到 API 响应中,旧的客户端将会接收到所有新的数据字段。即使是那些它们不需要的字段,结果会增加负载大小,并引起更大延迟;