关系型数据库管理系统(RDBMS)
像 SQL 这样的关系型数据库,是一系列以表的形式组织的数据项集合。
ACID 用来描述关系型数据库事务的特性:
- 原子性(Atomicity):每个事务内部所有操作要么全部完成,要么全部不完成;
- 一致性(Consistency):任何事务都使数据库从一个有效的状态转换到另一个有效状态;
- 隔离性(Isolation):并发执行事务的结果与顺序执行事务的结果相同;
- 持久性(Durability):事务提交后,对系统的影响是永久的。
关系型数据库的扩展,包括许多技术:主-从复制、主-主复制、联邦、分片、非规范化和 SQL 调优。
主-从复制
主库同时负责读取和写入操作,并复制写入到一个或多个从库中,从库只负责读操作。树状形式的从库再将写入复制到更多的从库中去。如果主库离线,系统可以以只读模式运行,直到某个从库被提升为主库或有新的主库出现: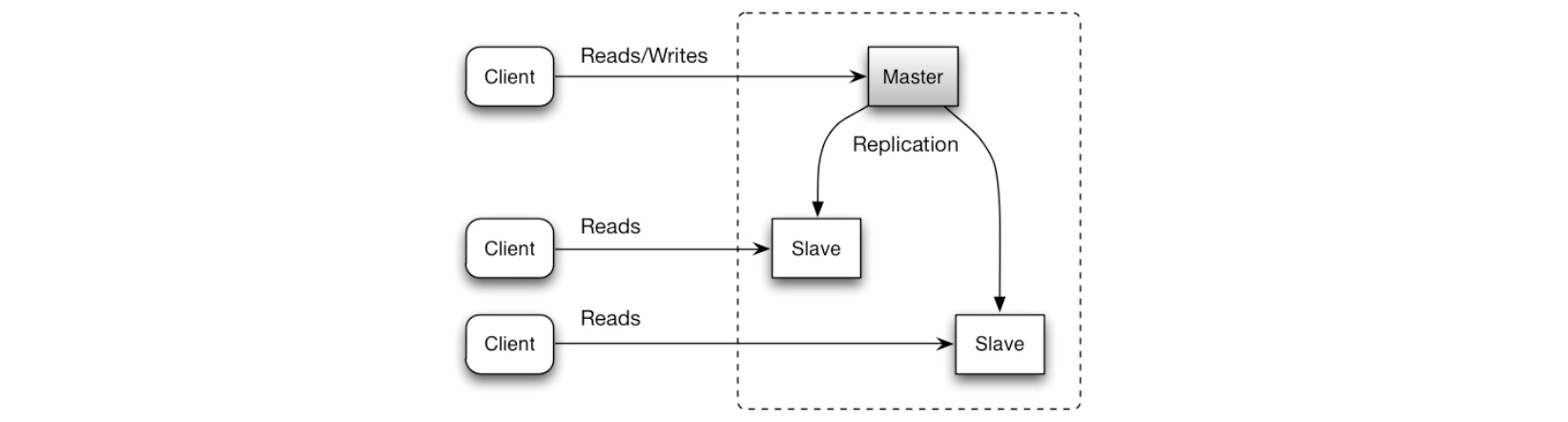
缺陷:主-从复制
- 将从库提升为主库需要额外的逻辑
主-主复制
两个主库都负责读操作和写操作,写入操作时互相协调。如果其中一个主库挂机,系统可以继续读取和写入:
缺陷:主-主复制
- 需要添加负载均衡器或者在应用逻辑中做改动,来确定写入哪一个数据库;
- 多数主-主系统要么不能保证一致性(违反 ACID),要么因为同步产生了写入延迟;
- 随着更多写入节点的加入和延迟的提高,如何解决冲突显得越发重要。
缺陷:复制
- 如果主库在将新写入的数据复制到其他节点前挂掉,则有数据丢失的可能;
- 写入会被重放到负责读取操作的副本。副本可能因为过多写操作阻塞,导致读取功能异常;
- 读取从库越多,需要复制的写入数据就越多,导致更严重的复制延迟;
- 在某些数据库系统中,写入主库的操作可以用多个线程并行写入,但写入副本只支持单线程顺序写入;
- 复制意味着更多的硬件和额外的复杂度。
联邦
Federation 将数据库按对应功能分割。例如,你可以有三个数据库:论坛、用户和产品,而不仅是一个单体数据库,从而减少每个数据库的读取和写入流量,减少复制延迟。较小的数据库意味着更多适合放入内存的数据,进而意味着更高的缓存命中几率。没有只能串行写入的中心化主库,你可以并行写入,提高负载能力: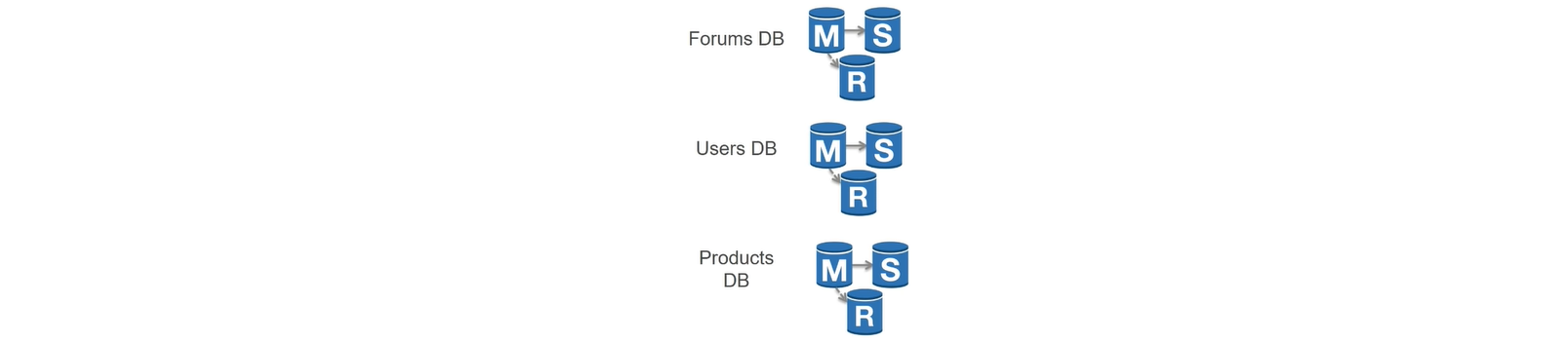
缺陷:联邦
- 如果你的数据库模式需要大量的功能和数据表,联邦的效率并不好;
- 你需要更新应用程序的逻辑,来确定要读取和写入哪个数据库;
- 用 server link 从两个库 JOIN 数据更复杂;
- 联邦需要更多的硬件和额外的复杂度。
分片
Sharding 将数据分配在不同的数据库上,使得每个数据库仅管理整个数据集的一个子集。以用户数据库为例,随着用户数量的增加,越来越多的分片会被添加到集群中: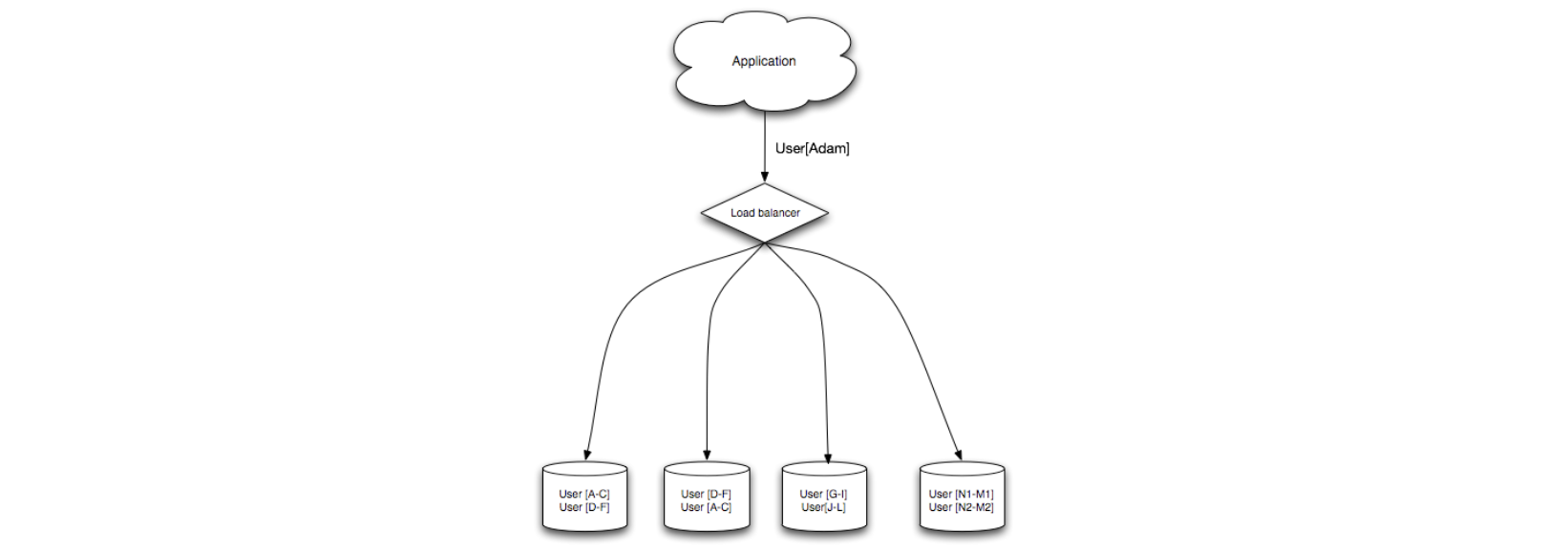
类似联邦的优点,分片可以减少读取和写入流量,减少复制并提高缓存命中率。也减少了索引,通常意味着查询更快,性能更好。如果一个分片出问题,其他的仍能运行,你可以使用某种形式的冗余来防止数据丢失。类似联邦,没有只能串行写入的中心化主库,你可以并行写入,提高负载能力。
常见的做法是:通过用户姓氏的首字母,或者用户的地理位置来分隔用户表。
缺陷:分片
- 你需要修改应用程序的逻辑来实现分片,这会带来复杂的 SQL 查询;
- 分片不合理可能导致数据负载不均衡。例如,被频繁访问的用户数据会导致其所在分片的负载相对其他分片高:
- 再平衡会引入额外的复杂度(基于
一致性哈希的分片算法可以减少这种情况);
- 再平衡会引入额外的复杂度(基于
- JOIN 多个分片的数据操作更复杂;
- 分片需要更多的硬件和额外的复杂度。
非规范化
Denormalization 试图以写入性能为代价来换取读取性能。在多个表中冗余数据副本,以避免高成本的 JOIN 操作。一些关系型数据库,比如 PostgreSQL 和 Oracle 支持物化视图,可以存储冗余信息和保持冗余副本的一致。
当数据使用诸如联邦和分片等技术被分割,进一步提高了处理跨数据中心的 JOIN 操作的复杂度。非规范化可以规避这种复杂的 JOIN 操作。
在多数系统中,读取操作的频率远高于写入操作,比例可达到 100:1,甚至 1000:1。需要复杂的数据库 JOIN 的读取操作成本非常高,在磁盘操作上消耗了大量时间。
缺陷:非规范化
- 数据会冗余;
Constraint可以帮助冗余的信息副本保持同步,但这样会增加数据库设计的复杂度;- 非规范化的数据库在高写入负载下,性能可能比规范化的数据库差;
SQL 调优
SQL tuning 是一个范围很广的话题,有很多相关的书可以作为参考。
利用基准测试(Benchmark)和性能分析(Profiling)来模拟和发现系统瓶颈很重要:
- Benchmark:用
ab等工具模拟高负载情况; - Profiling:通过启用如慢查询日志等工具来辅助追踪性能问题。
基准测试和性能分析可能会指引你到如下优化方案:
改进模式(Schema)
- 为了实现快速访问,MySQL 在磁盘上用连续的块存储数据;
- 使用 CHAR 类型存储固定长度的字段,不要用 VARCHAR:
- CHAR 在快速、随机访问时效率很高。使用 VARCHAR 时,如果你想读取下一个字符串,不得不先读取到当前字符串的末尾;
- 使用 TEXT 类型存储大块的文本(允许
布尔检索),例如博客正文。使用 TEXT 字段需要在磁盘上存储一个用于定位文本块的指针; - 使用 INT 类型存储高达 2^32(40 亿)的较大数字;
- 使用 DECIMAL 类型存储货币可以避免浮点数表示错误;
- 避免存储较大的
BLOB,而应存储获取对象的位置; - VARCHAR(255) 是以 8 位数字存储的最大字符数,在某些关系型数据库中,最大限度地利用字节;
- 在适用场景中设置
NOT NULL约束,来提高搜索性能;
使用正确的索引
- 查询(SELECT、GROUP BY、ORDER BY、JOIN)的列,如果用了索引会更快;
- 索引通常表示为自平衡的 B-tree,可以保持数据有序,并允许在对数时间内进行搜索、顺序访问、插入和删除操作;
- 设置索引,会将数据存在内存中,占用更多的内存空间;
- 写入操作会变慢,因为索引需要被更新;
- 加载大量数据时,禁用索引再加载数据,然后重建索引,这样也许会更快。
避免高成本的 JOIN 操作
若有需要,可以进行非规范化。
分割数据表
将热点数据拆分到单独的数据表中,可以有助于缓存。
调优查询缓存
在某些情况下,查询缓存可能会导致性能问题。
NoSQL
NoSQL 是采用键-值存储、文档存储、宽列存储和图存储的数据库的统称。数据库是非规范化的,JOIN 大多在应用程序代码中完成。大多数 NoSQL 无法完成真正满足 ACID 的事务,支持最终一致性。
BASE 通常被用于描述 NoSQL 数据库的特性。相比 CAP 理论,BASE 强调可用性超过一致性:
- 基本可用(Basically Available):系统保证可用性;
- 软状态(Soft state):即使没有输入,系统状态也可能随着时间变化;
- 最终一致性(Eventual consistency):经过一段时间之后,系统最终会变一致,因为系统在此期间没有收到任何输入。
除了在 SQL 还是 NoSQL 之间做选择,了解哪种类型的 NoSQL 数据库,最适合你的用例也是非常有帮助的。
键-值存储
抽象类型:Hash table
键-值存储通常可以实现 O(1) 时间的读写,用内存或 SSD 存储数据。数据存储可以按字典序维护键,从而实现键的高效检索。键-值存储可以用于存储元数据。
键-值存储性能很高,通常用于存储简单数据模型或频繁修改的数据,如内存中的缓存。键-值存储提供的操作有限,如需更多操作,复杂度将转嫁到应用程序层面。
键-值存储是更复杂的存储系统的基础,如文档存储和图存储。
文档存储
抽象模型:将文档作为值的键-值存储
文档存储以文档(XML、JSON、二进制文件等)为中心,文档存储了指定对象的全部信息。文档存储根据文档自身的内部结构,提供 API 或查询语句来实现查询。注意:许多键-值存储数据库有用值存储元数据的特性,这也模糊了这两种存储类型的界限。
基于底层实现,文档可以根据集合、标签(tag)、元数据(metadata)或文件夹组织。尽管不同文档可以被组织在一起或分成一组,但相互之间可能具有完全不同的字段。
MongoDB 和 Apache CouchDB 等一些文档存储数据库,还提供了类似 SQL 的查询语句来实现复杂查询。Amazon DynamoDB 同时支持键-值存储和文档存储。
文档存储具备高度的灵活性,常用于处理偶尔变化的数据。
宽列存储

抽象模型:Nested map,ColumnFamily<RowKey, Columns<ColKey, Value, Timestamp>>
宽列存储的基本数据单元是列(名/值对)。列可以在列簇(类似于 SQL 的数据表)中被分组,超级列簇再分组普通列簇。你可以使用行键独立访问每一列,具有相同行键值的列组成一行。每个值都包含时间戳,用于解决版本冲突。
Google 发布了第一个列型存储数据库 Bigtable,它影响了 Hadoop 生态系统中活跃的开源数据库 HBase 和 Facebook 的 Cassandra。它们将键以字典序存储,实现高效检索。
宽列存储具备高可用性和高可扩展性,常被用于大数据领域。
图存储
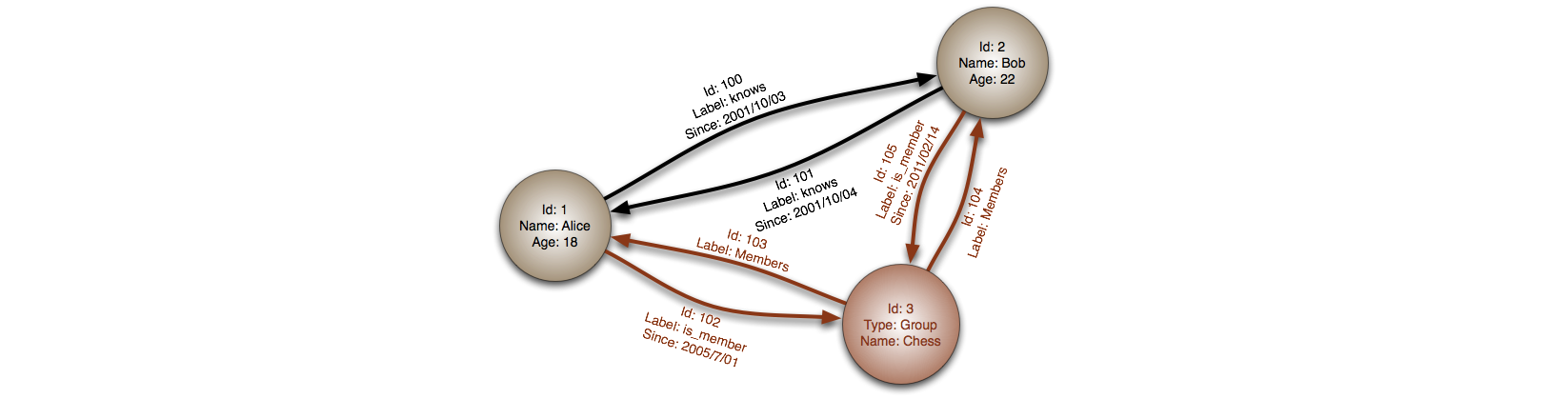
抽象模型:Graph
在图数据库中,一个节点对应一条记录,一条弧对应两个节点之间的关系。图数据库被优化用于表示外键繁多的复杂关系或多对多关系。
图数据库为存储复杂关系的数据模型,如社交网络,提供了很高的性能。它们相对较新,尚未广泛应用,查找开发工具和资源相对较难,许多图只能通过 RESTful API 访问。
SQL or NoSQL

选择 SQL 的原因
- 结构化数据;
- 严格的模式;
- 关系型数据;
- 需要复杂的 JOIN 操作;
- 事务;
- 清晰的扩展模式;
- 既有资源更丰富:开发者、社区、代码库、工具等;
- 通过索引进行查询非常快;
选择 NoSQL 的原因
- 半结构化数据;
- 动态或灵活的模式;
- 非关系型数据;
- 不需要复杂的 JOIN 操作;
- 存储 TB(甚至 PB)级别的数据;
- 高数据密集的工作负载;
- 高
Throughput/IOPS;
适合 NoSQL 的示例数据
- 埋点数据和日志数据;
- 排行榜或得分数据;
- 临时数据,如购物车;
- 频繁访问的热表;
- Metadata/Lookup table;