Distributed Hash Table (DHT) is one of the fundamental components used in distributed scalable systems. Hash Tables need a key, a value, and a hash function where hash function maps the key to a location where the value is stored:
index = hash_function(key)
Suppose we are designing a distributed caching system. Given “n” cache servers, an intuitive hash function would be “key % n”. It is simple and commonly used. But it has two major drawbacks:
- It is NOT horizontally scalable. Whenever a new cache host is added to the system, all existing mappings are broken. It will be a pain point in maintenance if the caching system contains lots of data. Practically, it becomes difficult to schedule a downtime to update all caching mappings;
- It may NOT be load balanced, especially for non-uniformly distributed data. In practice, it can be easily assumed that the data will not be distributed uniformly. For the caching system, it translates into some caches becoming hot and saturated while the others idle and are almost empty;
In such situations, consistent hashing is a good way to improve the caching system.
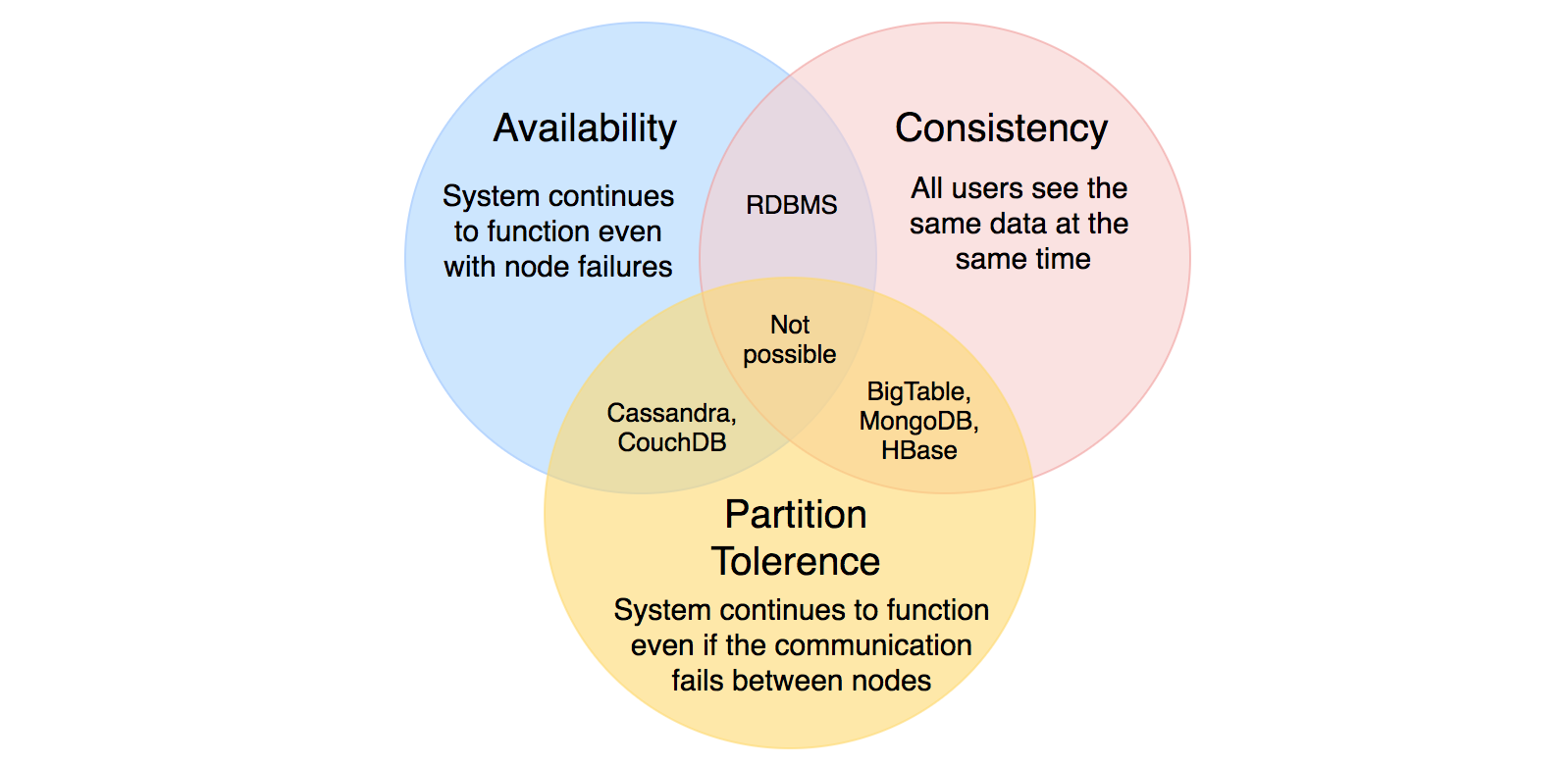
What is Consistent Hashing?
Consistent hashing is a very useful strategy for distributed caching systems and DHTs. It allows us to distribute data across a cluster in such a way that will minimize reorganization when nodes are added or removed. Hence, the caching system will be easier to scale up or scale down.
In Consistent Hashing, when the hash table is resized (e.g., a new cache host is added to the system), only “k/n” keys need to be remapped where “k” is the total number of keys and “n” is the total number of servers. Recall that in a caching system using the “mod” as the hash function, all keys need to be remapped.
In Consistent Hashing, objects are mapped to the same host if possible. When a host is removed from the system, the objects on that host are shared by other hosts; when a new host is added, it takes its share from a few hosts without touching other’s shares.