递归树与时间复杂度分析
递归的思想就是,将大问题分解为小问题来求解,然后再将小问题分解为小小问题。这样一层一层地分解,直到问题的数据规模被分解得足够小,不用继续递归分解为止。如果我们把这个一层一层的分解过程画成图,它其实就是一棵树。我们给这棵树起一个名字,叫作递归树(Recursion Tree)。归并排序每次会将数据规模一分为二,我们把归并排序画成递归树,就是下面这个样子: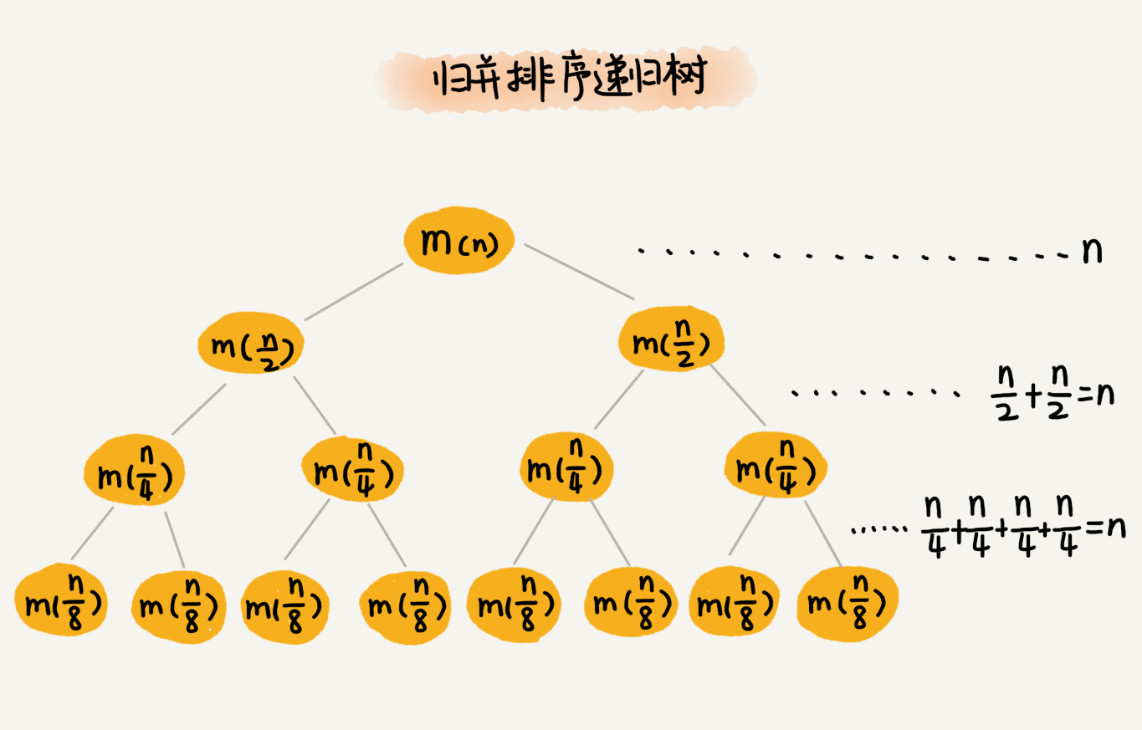
因为每次分解都是一分为二,所以代价很低,我们把时间上的消耗记作常量 1。归并算法中比较耗时的是归并操作,也就是把两个子数组合并为大数组。从图中我们可以看出,每一层归并操作消耗的时间总和是一样的,跟要排序的数据规模有关。我们把每一层归并操作消耗的时间记作 n。现在,我们只需要知道这棵树的高度 h,用高度 h 乘以每一层的时间消耗 n,就可以得到总的时间复杂度 O(n*h)。
从归并排序的原理和递归树,可以看出来,归并排序递归树是一棵满二叉树。满二叉树的高度大约是 log2n,所以,归并排序递归实现的时间复杂度就是 O(nlogn)。我这里的时间复杂度都是估算的,对树的高度的计算也没有那么精确,但是这并不影响复杂度的计算结果。