大应用拆分成微服务之后,服务之间的调用关系变得更复杂,平台的整体复杂熵升高,出错的概率、Debug 问题的难度都高了好几个数量级。所以,为了解决这些问题,服务治理便成了微服务的一个技术重点。所谓服务治理,简单点讲,就是管理微服务,保证平台整体正常、平稳地运行。服务治理涉及的内容比较多,比如鉴权、限流、降级、熔断、监控告警等等。这些服务治理功能的实现,底层依赖大量的数据结构和算法。
鉴权背景介绍
假设我们有一个微服务叫用户服务(User Service)。它提供很多用户相关的接口,比如获取用户信息、注册、登录等,给公司内部的其他应用使用。但是,并不是公司内部所有应用,都可以访问这个用户服务,也并不是每个有访问权限的应用,都可以访问用户服务的所有接口: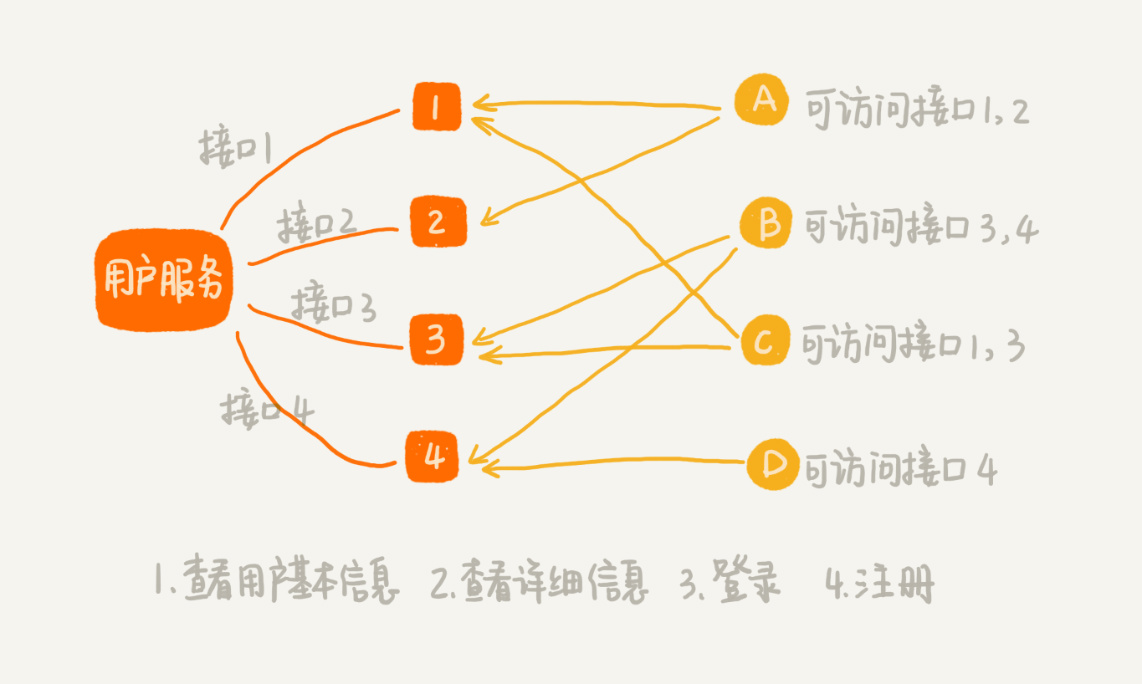
要实现接口鉴权功能,我们需要事先将应用对接口的访问权限规则设置好。当某个应用访问其中一个接口的时候,我们就可以拿应用的请求 URL,在规则中进行匹配。如果匹配成功,就说明允许访问;如果没有可以匹配的规则,那就说明这个应用没有这个接口的访问权限,我们就拒绝服务。