如何确定代码源文件的编译依赖关系
我们知道,一个完整的项目往往会包含很多代码源文件。编译器在编译整个项目的时候,需要按照依赖关系,依次编译每个源文件。比如,A.cpp 依赖 B.cpp,那在编译的时候,编译器需要先编译 B.cpp,才能编译 A.cpp。编译器通过分析源文件或者程序员事先写好的编译配置文件(比如 Makefile 文件),来获取这种局部的依赖关系。那编译器又该如何通过源文件两两之间的局部依赖关系,确定一个全局的编译顺序呢: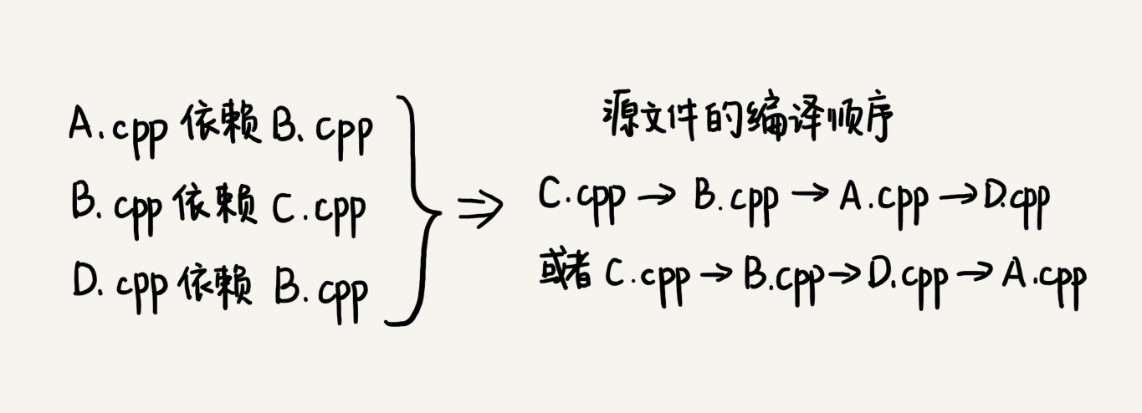
算法解析
我们在穿衣服的时候都有一定的顺序,我们可以把这种顺序想成,衣服与衣服之间有一定的依赖关系。比如说,你必须先穿袜子才能穿鞋,先穿内裤才能穿秋裤。假设我们现在有八件衣服要穿,它们之间的两两依赖关系我们已经很清楚了,那如何安排一个穿衣序列,能够满足所有的两两之间的依赖关系?这就是个拓扑排序(Topological Sorting)问题。从这个例子中,你应该能想到,在很多时候,拓扑排序的序列并不是唯一的: