基于单模式串和 Trie 树实现的敏感词过滤
单模式串匹配算法,是在一个模式串和一个主串之间进行匹配,也就是说,在一个主串中查找一个模式串。多模式串匹配算法,就是在多个模式串和一个主串之间做匹配,也就是说,在一个主串中查找多个模式串。尽管,单模式串匹配算法也能完成多模式串的匹配工作。但是,这样做的话,每个匹配过程都需要扫描一遍用户输入的内容,整个过程下来就要扫描很多遍用户输入的内容。如果敏感词很多,比如几千个,并且用户输入的内容很长,假如有上千个字符,那我们就需要扫描几千遍这样的输入内容。很显然,这种处理思路比较低效。
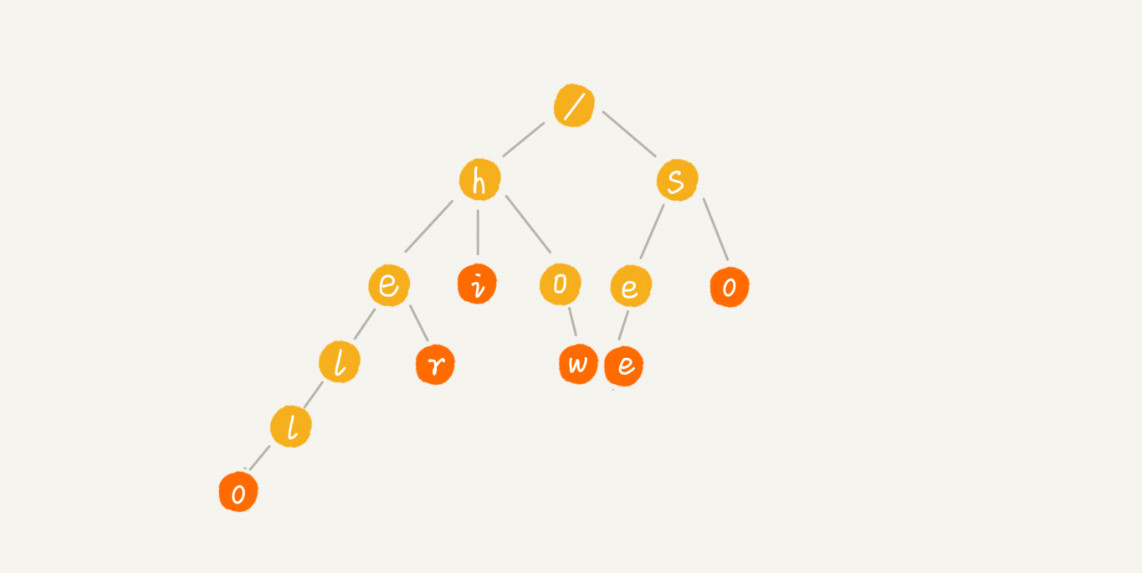
与单模式匹配算法相比,多模式匹配算法在这个问题的处理上就很高效了。它只需要扫描一遍主串,就能在主串中一次性查找多个模式串是否存在,从而大大提高匹配效率。我们可以对敏感词字典进行预处理,构建成 Trie 树结构。这个预处理的操作只需要做一次,如果敏感词字典动态更新了,比如删除、添加了一个敏感词,那我们只需要动态更新一下 Trie 树就可以了。
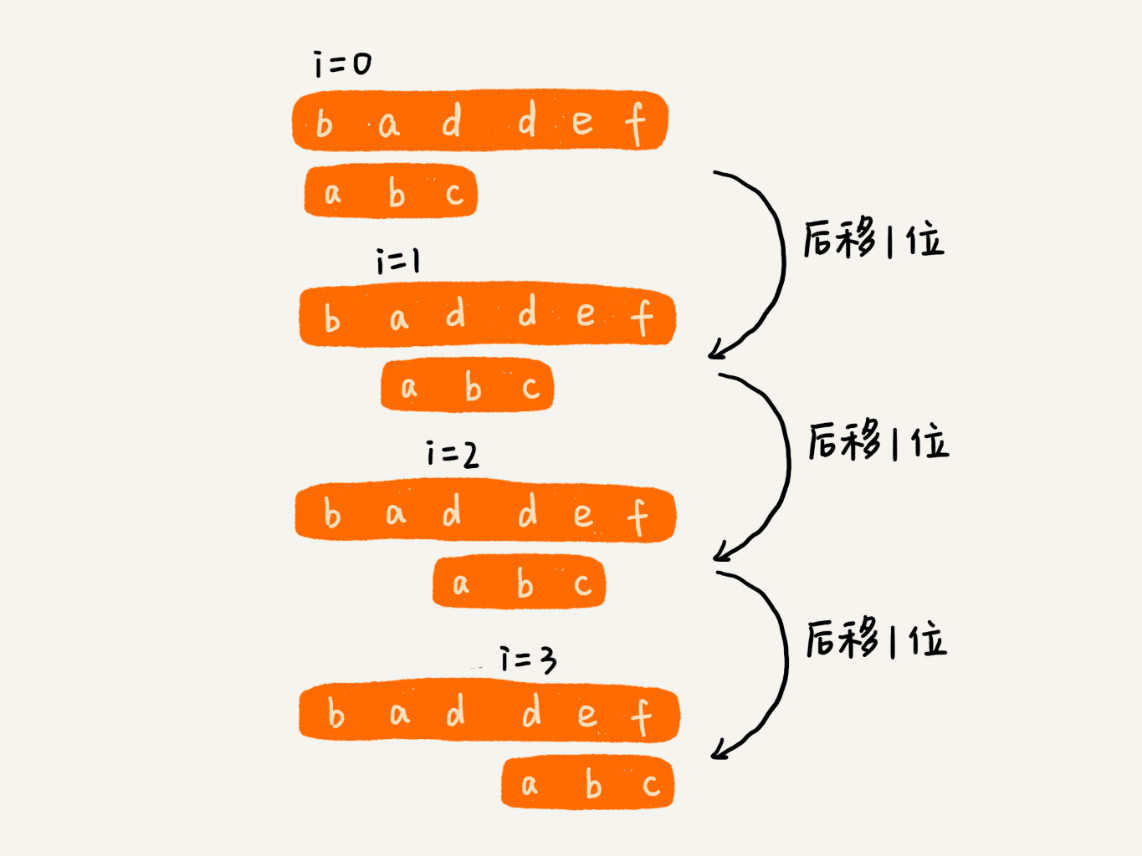
当用户输入一个文本内容后,我们把用户输入的内容作为主串,从第一个字符(假设是字符 C)开始,在 Trie 树中匹配。当匹配到 Trie 树的叶子节点,或者中途遇到不匹配字符的时候,我们将主串的开始匹配位置后移一位,也就是从字符 C 的下一个字符开始,重新在 Trie 树中匹配。基于 Trie 树的这种处理方法,有点类似单模式串匹配的 BF 算法。