DRY 原则的英文描述为:
Don’t Repeat Yourself.
中文直译为:不要重复自己。今天,我们主要讲三种典型的代码重复情况,它们分别是:实现逻辑重复、功能语义重复和代码执行重复。这三种代码重复,有的看似违反 DRY,实际上并不违反;有的看似不违反,实际上却违反了。
实现逻辑重复
我们先来看下面这样一段代码是否违反了 DRY 原则:
DRY 原则的英文描述为:
Don’t Repeat Yourself.
中文直译为:不要重复自己。今天,我们主要讲三种典型的代码重复情况,它们分别是:实现逻辑重复、功能语义重复和代码执行重复。这三种代码重复,有的看似违反 DRY,实际上并不违反;有的看似不违反,实际上却违反了。
我们先来看下面这样一段代码是否违反了 DRY 原则:
KISS 原则的英文描述:
Keep It Simple and Stupid.
翻译成中文就是:尽量保持简单。KISS 原则算是一个万金油类型的设计原则,可以应用在很多场景中。它不仅经常用来指导软件开发,还经常用来指导更加广泛的系统设计、产品设计等,比如,冰箱、建筑、iPhone 手机的设计等等。
代码的可读性和可维护性是衡量代码质量非常重要的两个标准。而 KISS 原则就是保持代码可读和可维护的重要手段。代码足够简单,也就意味着很容易读懂,bug 比较难隐藏。即便出现 bug,修复起来也比较简单。
下面这三段代码可以实现同样一个功能:检查输入的字符串 ipAddress 是否是合法的 IP 地址。
其实,只要讲到数据结构与算法,就一定离不开时间、空间复杂度分析。而且,我个人认为,复杂度分析是整个算法学习的精髓,只要掌握了它,数据结构和算法的内容基本上就掌握了一半。
首先,我可以肯定地说,你这种评估算法执行效率的方法是正确的。很多数据结构和算法书籍还给这种方法起了一个名字,叫事后统计法。但是,这种统计方法有非常大的局限性。
测试环境中硬件的不同会对测试结果有很大的影响。比如,我们拿同样一段代码,分别用 Intel Core i9 处理器和 Intel Core i3 处理器来运行,不用说,i9 处理器要比 i3 处理器执行的速度快很多。还有,比如原本在这台机器上 a 代码执行的速度比 b 代码要快,等我们换到另一台机器上时,可能会有截然相反的结果。
后面我们会讲排序算法,我们先拿它举个例子。对同一个排序算法,待排序数据的有序度不一样,排序的执行时间就会有很大的差别。极端情况下,如果数据已经是有序的,那排序算法不需要做任何操作,执行时间就会非常短。除此之外,如果测试数据规模太小,测试结果可能无法真实地反映算法的性能。比如,对于小规模的数据排序,插入排序可能反倒会比快速排序要快!
我们需要一个不用具体的测试数据来测试,就可以粗略地估计算法的执行效率的方法。
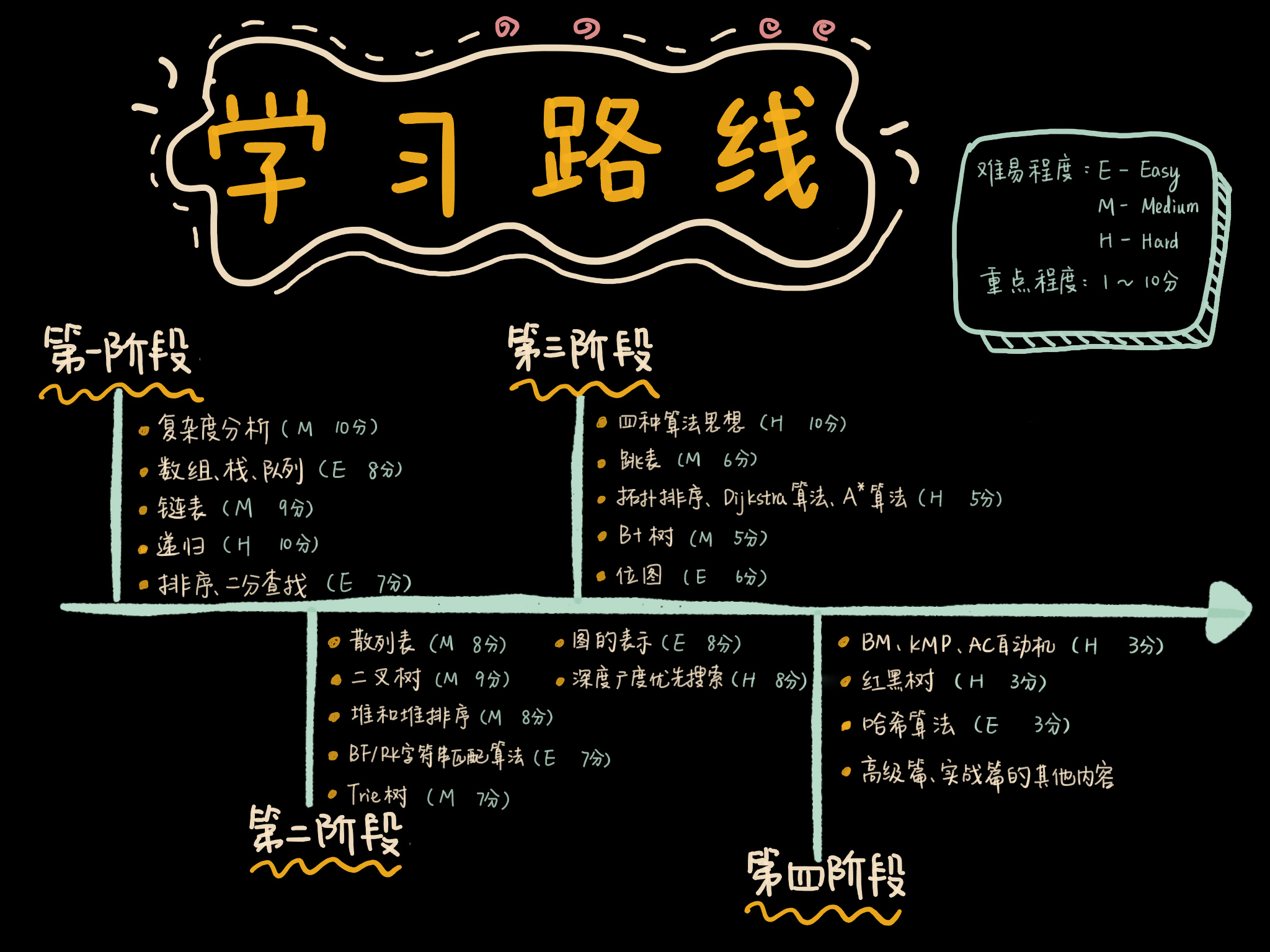
现在,针对每个知识点,我再给你逐一解释一下。我这里先说明一下,下面标记的难易程度、是否重点、掌握程度,都只是针对初学者来说的,如果你已经有一定基础,可以根据自己的情况,安排自己的学习。
尽管在专栏中,我只用了两节课的内容,来讲复杂度分析这个知识点。但是,我想说的是,它真的非常重要。你必须要牢牢掌握这两节,基本上要做到,简单代码能很快分析出时间、空间复杂度;对于复杂点的代码,比如递归代码,你也要掌握专栏中讲到的两种分析方法:递推公式和递归树。
对于初学者来说,光看入门篇的两节复杂度分析文章,可能还不足以完全掌握复杂度分析。不过,在后续讲解每种数据结构和算法的时候,我都有详细分析它们的时间、空间复杂度。所以,你可以在学习专栏中其他章节的时候,再不停地、有意识地去训练自己的复杂度分析能力。
控制反转的英文翻译是 Inversion of Control,缩写为 IoC。我们先通过一个例子来看一下,什么是控制反转:
1 | public class UserServiceTest { |
在上面的代码中,所有的流程都由程序员来控制。如果我们抽象出一个下面这样一个框架,我们再来看,如何利用框架来实现同样的功能。具体的代码实现如下所示: