常常得先把那些乱七八糟的数据,处理成漂亮点的结构化形式。
Python 解释器
一次执行一条语句。
“>>>”是提示符,可以在那里输入表达式。
语言语义
重视可读性、简洁性、明确性,可执行的伪代码。
缩进,而不是大括号
通过空白符(4 个空格)来组织代码。
冒号表示一段缩进代码块的开始,其后必须缩进相同的量,直到代码块结束为止:
常常得先把那些乱七八糟的数据,处理成漂亮点的结构化形式。
一次执行一条语句。
“>>>”是提示符,可以在那里输入表达式。
重视可读性、简洁性、明确性,可执行的伪代码。
通过空白符(4 个空格)来组织代码。
冒号表示一段缩进代码块的开始,其后必须缩进相同的量,直到代码块结束为止:
决策过程中提出的每个判定问题都是对某个属性的测试
考虑范围在上一次决策结果的限定范围之内
决策树学习的目的是为了,产生一棵处理未见示例能力强的决策树。
遵循简单且直观的分而治之(divide-and-comquer)策略。
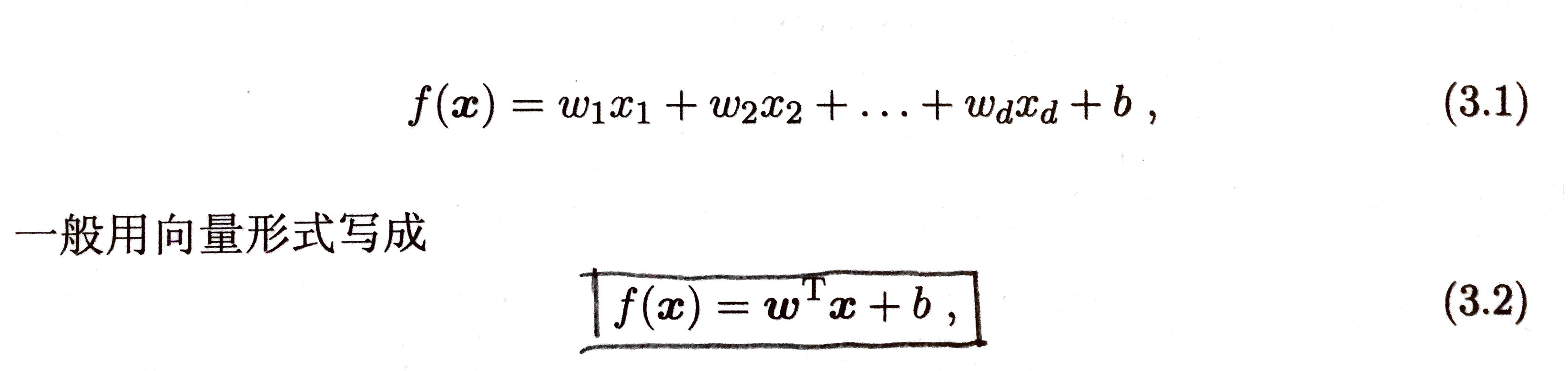
xi 是 x 在第 i 个属性上的取值。
w 和 b 学得之后,模型就得以确定。
许多功能更为强大的非线性模型(nolinear model)可在线性模型的基础上,通过引入层级结构或高维映射而得。
w 直观表达了各属性在预测中的重要性,因此线性模型有很好的可解释性(comprehensibility)。
精度(accuracy),精度 = 1-错误率。
实际希望的,是在新样本上能表现得很好的学习器。
过拟合是无法彻底避免的。若可彻底避免过拟合,则通过经验误差最小化就能获得最优解。
以测试集的测量误差(testing error)作为泛化误差的近似。
测试集应该尽可能与训练集互斥,通过对数据集 D 进行适当的处理,从中产生训练集 S 和测试集 T。
整数 / 整数 = 整数,浮点数 / 浮点数 = 浮点数。
scanf 中占位符和变量的数据类型一一对应,每个变量前需要加“&”符号;
输入输出过程是自动的,没有人工干预。输入前不要打印提示信息,输出完毕后应立即终止程序;
尽量用 const 关键字声明常数。
交换变量:
三变量法(适用范围广,推荐使用)