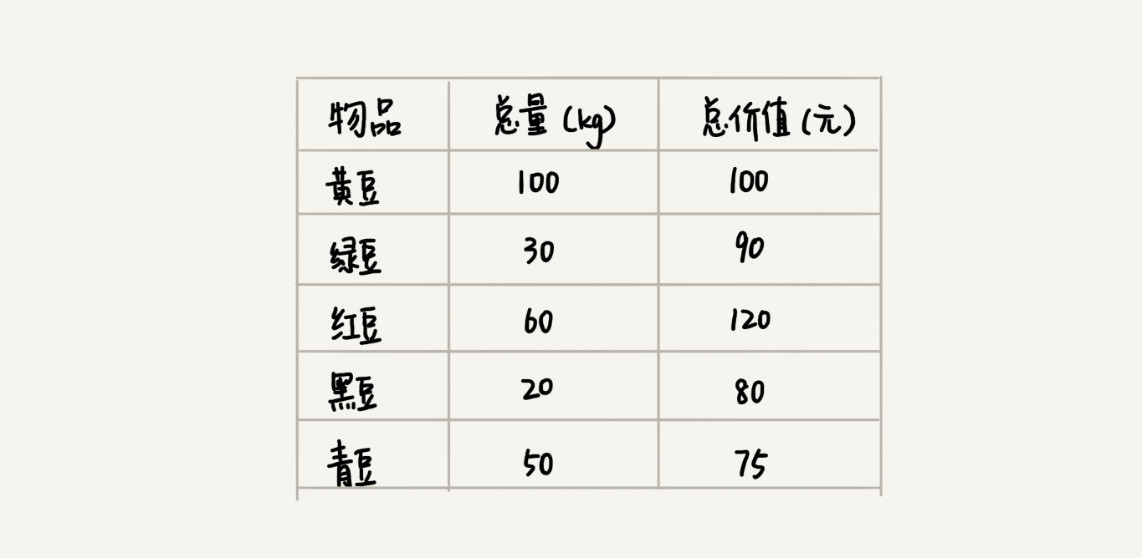
如何理解“回溯算法”?
笼统地讲,回溯算法(Backtracking Algorithm)很多时候都应用在“搜索”这类问题上。不过这里说的搜索,并不是狭义的指我们前面讲过的图的搜索算法,而是在一组可能的解中,搜索满足期望的解。回溯的处理思想,有点类似枚举搜索。我们枚举所有的解,找到满足期望的解。为了有规律地枚举所有可能的解,避免遗漏和重复,我们把问题求解的过程分为多个阶段。每个阶段,我们都会面对一个岔路口,我们先随意选一条路走,当发现这条路走不通的时候(不符合期望的解),就回退到上一个岔路口,另选一种走法继续走。
我们有一个 8x8 的棋盘,希望往里放 8 个棋子(皇后),每个棋子所在的行、列、对角线都不能有另一个棋子。你可以看我画的图,第一幅图是满足条件的一种方法,第二幅图是不满足条件的。八皇后问题就是期望找到所有满足这种要求的放棋子方式: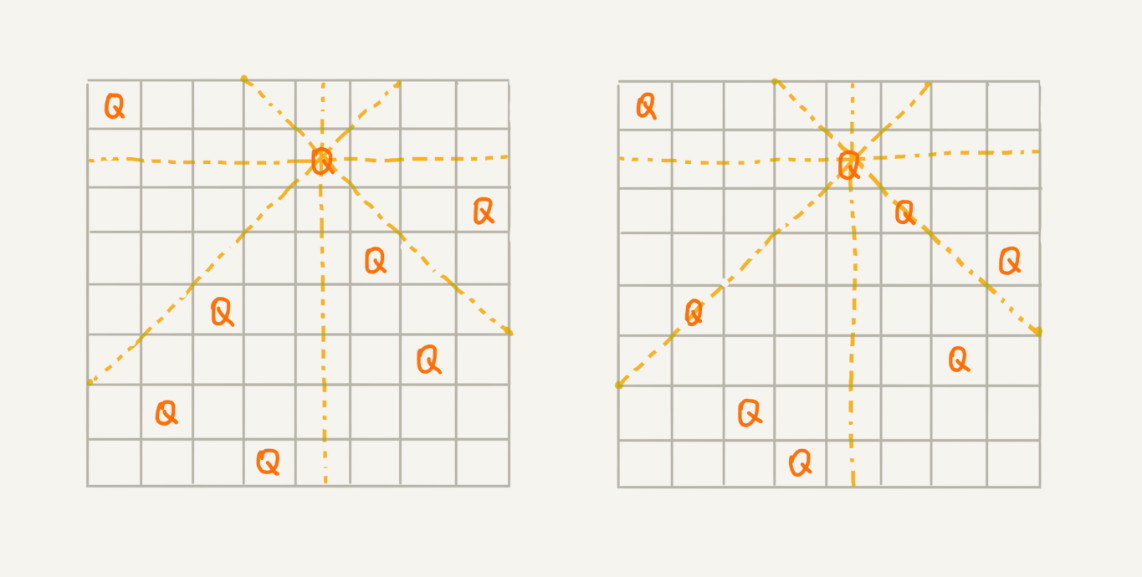
我们把这个问题划分成 8 个阶段,依次将 8 个棋子放到第一行, 第二行, 第三行, …, 第八行。在放置的过程中,我们不停地检查当前放法,是否满足要求。如果满足,则跳到下一行继续放置棋子;如果不满足,那就再换一种放法,继续尝试。回溯算法非常适合用递归代码实现: