BF 算法
BF(Brute Force)算法,中文叫作暴力匹配算法,也叫朴素匹配算法。从名字可以看出,这种算法的字符串匹配方式很“暴力”,当然也就会比较简单、好懂,但相应的性能也不高。我们在字符串 A 中查找字符串 B,那字符串 A 就是主串,字符串 B 就是模式串。我们把主串的长度记作 n,模式串的长度记作 m。因为我们是在主串中查找模式串,所以 n>m。
作为最简单、最暴力的字符串匹配算法,BF 算法的思想可以用一句话来概括,那就是,我们在主串中,检查起始位置分别是 0, 1, 2, n-m 且长度为 m 的 n-m+1 个子串,看有没有跟模式串匹配的: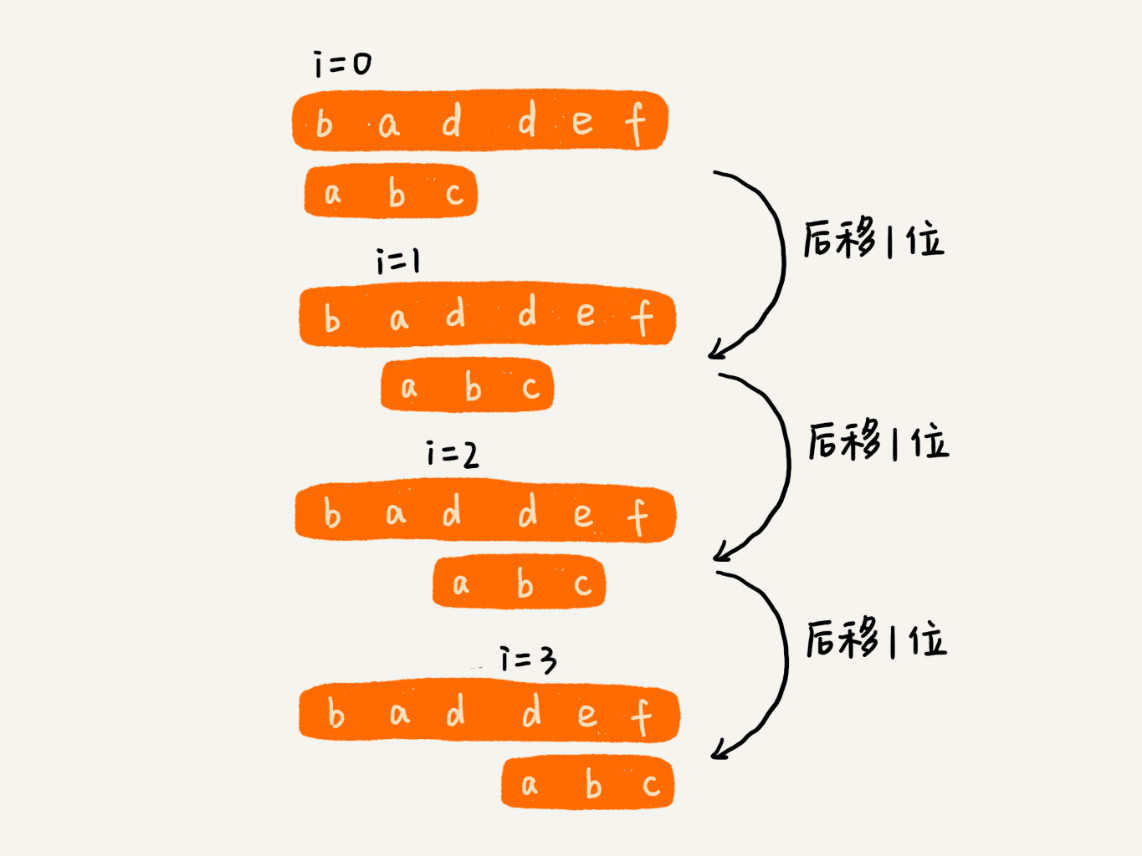
从上面的算法思想和例子,我们可以看出,在极端情况下,比如主串是“aaaaa…aaaaaa”,模式串是“aaaaab”。我们每次都比对 m 个字符,要比对 n-m+1 次,所以,这种算法的最坏情况时间复杂度是 O(n*m)。尽管理论上,BF 算法的时间复杂度很高,是 O(n*m),但在实际的开发中,它却是一个比较常用的字符串匹配算法。原因有两点:
- 实际的软件开发中,大部分情况下,模式串和主串的长度都不会太长。而且每次模式串与主串中的子串匹配的时候,当中途遇到不能匹配的字符的时候,就可以就停止了,不需要把 m 个字符都比对一下。所以,尽管理论上的最坏情况时间复杂度是 O(n*m),但是,统计意义上,大部分情况下,算法执行效率要比这个高很多;
- 朴素字符串匹配算法思想简单,代码实现也非常简单。简单意味着不容易出错,如果有 bug 也容易暴露和修复。在工程中,在满足性能要求的前提下,简单是首选;